
オープンソースのクラウド基盤「OpenStack」、その経緯と仕組みとは
クラウドを構築するために商用のソフトウェアやオープンソースのソフトウェアなどが多数登場してきています。その中の1つとして注目されているのがOpenStackです。
OpenStackとはどのようなソフトウェアなのか、その歴史的経緯と技術的な解説を行っているビデオ「openstack building a free massively scalable cloud computing platform」が公開されています。
これは2月にベルギーのブリュッセルで行われた「Free and Open Source Software Developers' European Meeting」(FOSDEM)で行われたセッションを記録したものです。
Building a free massively scalable cloud computing platform
OpenStackデベロッパのSoren Hansen氏。

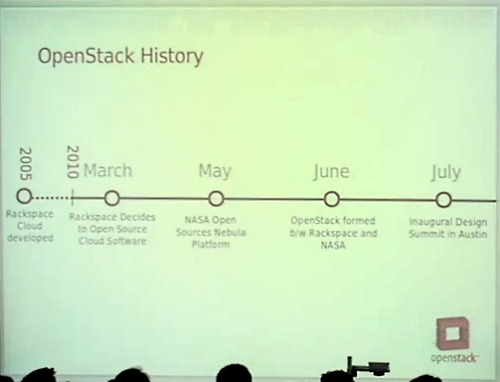
OpenStackには、NASAとRackspaceという2社が大きく関わっている。

RackspaceとNASA
Rackspaceは2005年にクラウドサービスを開始した。
Rackspace Cloud Filesはオブジェクトストアで、ブロブデータを格納、取得できる。ただしこれはブロックデバイスではない。
特徴として、ほぼ無限のストレージで、使った分だけ支払うというモデルを実現できる。つまりAmazon S3のようなものだ。

Rackspace Cloud Serversは、仮想マシンを実行するいわゆるクラウドコンピューティングで、VPSとAPIからなる。自動的にインスタンスのサイズやOSを選択できる。
おそらくこうしたサービスは最初にAmazonクラウドが提供したものだ。小さな一歩だが人類にとって大きな一歩、みたいなものだろう。
あらかじめたくさんハードウェアを調達しておかなくても、わずか数分で入手できるようにした。
コンピュータリソースの調達方法を根底から変える点が、クラウドコンピューティングの素晴らしいところだろう。
そして使った分だけ課金できる。これがRackspace Cloud Serviersだ。

Cloud Filesは2009年に書き直され、2010年にはCloud Serversも書き直され、そしてオープンソース化した。

NASAの経緯についても紹介しよう。
NASAは単に宇宙船を打ち上げるだけでなく、政府のための研究も行っている。そこでクラウドに注目し、構築を始める。

Amazon EC2互換のEucalyptusを検討したが、スケーラビリティや信頼性の問題に直面し、NASAは自身でコンテナサーバをベースにしたNebulaを構築した。

Openstackのミッション
興味深いことに、両者が同じ時期にクラウド開発に取り組んでおり、3月にRackspaceがオープンソース化したのに続いて、5月にはNASAがNebulaをオープンソース化した。
それでRackspaceの誰かがNASAに電話して、ちょうどオブジェクトストアを開発してオープンソースにしたところで、この2つを組み合わせてクラウドコンピューティングの開発を一緒に進めないか? といった話をした。
それが6月の半ばだったと思う。そこから話はとんとん拍子に進んで2010年7月にはデザインサミットをオースティンで開催。200人くらいが集まり、30社くらいの会社の賛同も得てOpenStackの発表を行った。
OpenStackのミッションは、オープンソースのクラウドコンピューティング基盤として、シンプルな実装と大規模なスケーラブルを実現することだ。クラウドのApacheのように広まりたいと希望している。

オブジェクトストアのSWIFT
続いてOpenStackの技術的な面を紹介しよう。
Openstack Storage / コードネームSWIFT。オブジェクトストレージのSWIFTは非常にシンプルだ。
これまでよく用いられていた方法や以前のCloud Filesなどでは、すべてのコンポーネントが状態を共有するために、マスターデータベースの内容を多くのスレーブで共有したり、Gossipのようなプロトコルを使って情報共有をしていた。
オブジェクトをストアするAPIをコールするとしよう。普通のやり方なら、例えばデータベースを参照して、すでにそのオブジェクトがあるかどうかを確認して、あれば上書きし、それをほかのサーバにレプリケートする、といったやり方になる。

しかしSWIFTでは違う方法を採用している。例えばAPIでputを呼び出す。
PUT /APIバージョン/アカウント/コンテナ/オブジェクト
このときAPIのバージョンはあらかじめ決まっているので、アカウント名、コンテナ、オブジェクトの3つの値のMD5かなにかでチェックサムをとる。こんな値だとする。
089a3d9219f058807e4c15e51cd5d1ac
この最初の4バイトが、このオブジェクトを格納することになる3つのサーバをユニークに定義している(1つのオブジェクトは冗長性のために自動的に3つのサーバに格納される)。
いちいち何かを参照することはしないのだ。クラスタはリング構造を持ち、ノードには自動的にこれらの値が割り当てられる。状態を共有したりする必要がない。
これはPOST、GET、DELETEの操作でも同様に行われる。
オブジェクトのリストを出すときはどうするか? 例えば、あるアカウントのコンテナに格納されているオブジェクトの一覧をだすのはどうするか。
GET /APIバージョン/アカウント/コンテナ
このGETのアカウントとコンテナの2つの値から同じようにチェックサムを求める。この値も同じようにサーバをユニークに指定しており、そのサーバには、このアカウントのあるコンテナが格納しているオブジェクトの一覧を返すデータベースのように値を返してくれる。
状態を共有する場面ではこのような方法が使われている。こうした仕組みは非常にうまくスケールしてくれる。これがSWIFTの仕組みだ。
仮想マシンを管理するNOVA
Openstack Compute / NOVAは、少しSWIFTよりも複雑だ。
これは自分なりに説明した図だ。
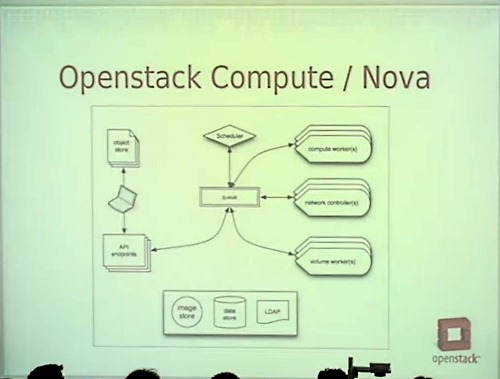
(図の右側に、コンピュータワーカー、ネットワークコントローラー、ボリュームワーカー、中央上にスケジューラ、左下がAPIサーバ)
APIサーバに対して仮想マシンを増やしたいとリクエストしよう。するとまずユーザーに関するバリデーションが行われ、仮想マシンののクオータがチェックされる。
同時にメッセージキューに命令が送られ、スケジューラがリクエストをピックアップし、コンピュータワーカーに送り、仮想マシンのイメージをフェッチする。
続いてネットワークコントローラーにIPアドレスをもらいに行き、ネットワークコントローラーはDHCPからIPを取得、ボリュームワーカーからはディスク領域を取得してブロックデバイスを割り当てられる。
そして仮想マシンが起動される。
仮想マシンごとにファイアウォールを関連させることもある。というのも、われわれのゴールは数百万もの仮想マシンを扱うことであり、1つの巨大なファイアウォールで全体をカバーすることはできない。できるだけ分散して処理する必要があるのだ。
関連記事
- クラウド事業者のためのオープンソースプロジェクト「OpenStack」
- OpenStackが、DaaS(Database as a Service)を実現する「Project RedDwarf」を立ち上げ
- クラウド構築のための「OpenStack」、商用ディストリビューションをシトリックスが発表「Project Olympus」
- クラウド基盤となるソフトウェア、ビットアイルはOpenStack、IDCフロンティアはCloudStackを採用へ。担当者に理由を聞いた
- クラウドのすべてのスタックがオープン化。データセンターは「Open Compute」、IaaSは「OpenStack」、PaaSは「Cloud Foundry」

