
[速報]Amazonクラウド、データ統合サービスの「AWS Data Pipeline」を発表。データのバッチ処理、スケジューリングなどの自動化を実現。AWS re:Invent基調講演(Day2)
ラスベガスでイベント「re:Invent」を開催中のAmazon Web Services。2日目の基調講演ではハイメモリインスタンス、ハイストレージインスタンスの発表に続き、データ統合や処理のスケジューリングなどデータ分析作業の自動化が行える「AWS Data Pipeline」が発表されました。
AWS Data Pipelineは、Amazonクラウド内のさまざまなデータソースやオンプレミスのデータソースの複製や統合を行い、分析処理へと流しこみ、レポートを作成するという一連の処理を自動化。スケジュールによってルーチンワークに落とし込めるツールです。
より速くビジネスを改善するために、迅速な開発とその運用からのフィードバックを開発に反映するサイクルを素早く回す、いわゆるDevOpsの手法が用いられれます。このとき、適切なフィードバックを得るために多くの計測とその分析が欠かせません。AWS Data Pipelineは、こうしたクラウド時代の開発運用とビジネス展開を実現する上で重要なツールとして活用できます。
「AWS Data Pipeline」は、クラウドを活用することでビジネスを迅速に改善、展開することができるのだ、というAmazonクラウドの方向性を明確に示したサービスです。
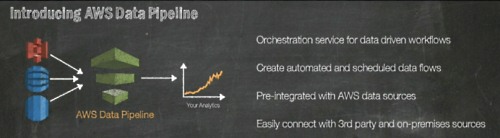
「AWS Data Pipeline」はデータドリブンなワークフローを構築
Amazon.com CTO、Werner Vogels氏。

データはDynamoDBやAmazon S3などさまざまな場所で発生し、保存されている。これら大量のデータを分析することは、データに基づくビジネスを実現する核心だ。

それを助けるための新しいサービスを発表する。「AWS Data Pipeline」だ。これはデータドリブンなワークフローを構築する。
データの複製や別のデータベースへの移動、あるいはRedshiftで分析するといった処理を自動化し、スケジュールを設定し、レポーティング処理を実現する。サードパーティのツールやオンプレミスのデータにも対応する。
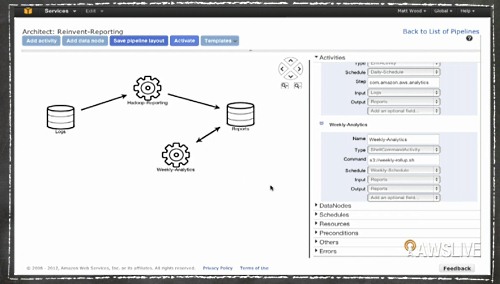
デモ:ここではDynamoDBのデータ(左のデータベース)を、Amazon EMR(Elastic MapReduce)で処理してAmazon S3へ保存すると言った処理を、画面上でドラッグ&ドロップやメニュー操作で簡単に設定でき、これを毎週、あるいは毎日といったバッチ処理として設定することもできる。
AWS re:Inventレポート
- [速報]Amazonクラウド、新サービス「Redshift」発表。データウェアハウスの価格破壊へ
- エンタープライズがクラウドへ移行する6つの理由。AWS re:Invent基調講演(Day1)
- Amazonはハイマージンをむさぼる既存の「偽装クラウド屋」とは違う。AWS re:Invent基調講演(Day1)
- [速報]Amazonクラウド、インメモリデータベースと大規模データ分析に適した2つの大型インスタンス「ハイメモリ」と「ハイストレージ」を発表。AWS re:Invent基調講演(Day2)
- [速報]Amazonクラウド、データ統合サービスの「AWS Data Pipeline」を発表。データのバッチ処理、スケジューリングなどの自動化を実現。AWS re:Invent基調講演(Day2)
- 「KindleとAWSは似ている」 Amazon CEOジェフ・ベゾス氏、自社のクラウドビジネスを語る。AWS re:Invent基調講演(Day2)
- AmazonクラウドのCTO「クラウドネイティブなアーキテクチャには4つの戒律がある」。AWS re:Invent基調講演(Day2 AM)
- Amazonは1時間に最大1000回もデプロイする。クラウドネイティブなデプロイとはどういうものか? AWS re:Invent基調講演(Day2 AM)
あわせて読みたい
「KindleとAWSは似ている」 Amazon CEOジェフ・ベゾス氏、自社のクラウドビジネスを語る。AWS re:Invent基調講演(Day2)
≪前の記事
[速報]Amazonクラウド、インメモリデータベースと大規模データ分析に適した2つの大型インスタンス「ハイメモリ」と「ハイストレージ」を発表。AWS re:Invent基調講演(Day2)

