
Twitterの大規模システム運用技術、あるいはクジラの腹の中(後編)~Twitterのサブシステム「Unicorn」「Kestrel」「Flock DB」
米サンタクララで行われていたWebサイトのパフォーマンスと運用に関するオライリーのイベント「Velocity 2010」の、Twitterのシステム運用について説明するセッション「In the Belly of the Whale: Operations at Twitter」(クジラの腹の中:Twitterでの運用)を紹介をしています。
この記事は「「Twitterの大規模システム運用技術、あるいはクジラの腹の中(前編)~ログの科学的な分析と、Twitterの「ダークモード」」の続きです。
Twitterのサブシステム「loony」「Murder」「memcached」
ここからはTwitterのサブシステムについて紹介しよう。
Twitterは非常に巨大なサイトで、大量のマシンを使って数百万のユーザーにサービスを提供している。その内側では多くのことが起きている。
運営管理上の最大の問題の1つは、どのマシンがどれなのかを認識することだ。私たちはマネージドホスティングを使っているが、Web100といったホスティング上の名前を自分たちの名前にマッピングしている。これを管理するために使っているのが「loony」で、マシンのセントラルデータベースだ。
loonyはLDAPとも結びつけて、どのマシンに誰がアクセスしているかも管理している。リアルタイムで管理しているので、サーバのグルーピングや、メールサーバやWebサーバといった役割の違うサーバをオンデマンドでデプロイするのにとても役立っている。

マシンを作成するときに使うのが「Murder」だ。昨日のFacebookのディスカッションの中で、Bittorrentを使ってソフトウェアをデプロイするという話があったけれど、私たちも同じことをしている。オープンソースのライブラリで合法的なピア・ツー・ピア技術によって、ソフトウェアを数千台のサーバへ高速にデプロイしてくれている。

Webサイトが遅くなったときに、多くのオペレーションチームがmemcachedを使おうとするだろう。しかし多くのデータをmemcachedのキャッシュに入れようとしてデータの退避(Evictions)が発生し、バックリンクのトラフィックが増大してしまうという現象が発生する。
memcachedを使う場合には、セグメントごとのデータ量に気をつけて使うべきだ。 (参考:Facebookが大規模スケーラビリティへの挑戦で学んだこと(後編)~キャッシュが抱えるスケーラビリティの問題とデータセンターにまたがる一貫性)

Twitterのサブシステム「Unicorn」「Kestrel」「Flock DB」
さて。Twitterへのリクエストは、ロードバランサーを通りApacheへ到達する。これがその流れだ。そして昨年の最大の成功は、「Unicorn Rails Server」への移行だった。
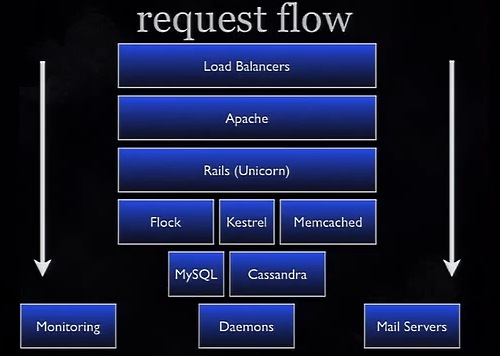
Rails ServerのMongrelとUnicornを比較すると、Mongrelは、スーパーマーケットのレジに並ぶたくさんの列があるが、どの列の処理ががどれだけかかるか知らされないままに並ばせられるようなものなのに対し、Unicornは処理してくれる番が自動的に割り振られる長い列の中で待っているようなものだ。
Unicorn Rails ServerによってCPUの負荷を約30%下げることができたし、メモリ使用量を下げることもできた。また、素早くリクエストを切り替えることができるため。ダウンタイムなしでのデプロイを可能にしてくれた。

もう1つ、処理の効率化を実現したのが非同期化だ。昨年、私たちは処理パイプラインの多くをキューイングサーバの中に入れた。
オープンソースの「Kestrel」はmemcachedに似ている(同じプロトコルを使う)が、データをキューイングしてくれるサーバだ。これによりリクエストに対して処理を非同期にすることができ、処理するWorkerを減らすことになり、パイプラインの処理が効率化した。

Workerとしての処理にはdaemonを使う。ツイートをコピーしてメールを出したり、新たなフォローが発生するといった処理だが、これまで処理ごとにさまざまなタイプのdaemonを運用していた。昨年、これを1つにまとめてさまざまな処理ができるようにしたことでサイト全体のパフォーマンスを高めることができた。

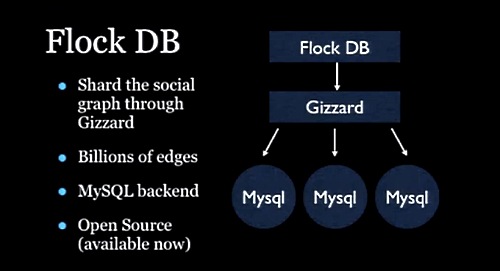
ソーシャルネットワーキングでの重たい処理の1つが、誰が誰をフォローしているかというソーシャルグラフの処理だ。そこでFlock DBを開発した。データベースにはMySQLを利用しているが、ShardingレイヤとしてGizzardを利用している(参考:Twitterが分散フレームワーク「Gizzard」公開! Scalaで書かれたShardingを実現するミドルウェア)。
「何でもキャッシュ」はベストではない
私たちはmemcachedにツイートを保持するし、memcachedのオープンソースの大いなる貢献者でもある。しかしたとえリアルタイムシステムではあってもデータのストアは必要だ。 経験から私たちは「Cache Everything!」(何でもキャッシュしろ!)はベストなポリシーではないことを発見した。データベースの拡張としてキャッシュを使うべきだ。
もしもmemcachedにすべてのデータを入れておいて、それが失われてしまったら何時間も復旧にかかるだろう。過去に私たちはその犠牲者となった。データベースに入れておけばロードできるのだ。

最後にまとめを。初期の頃からコンフィグレーションマネジメントの実行をおすすめする。そしてできるだけ多くのログをとること。われわれのケースでは1つの設計ですべてのサイズに合うことはないかった。何度も作り直しが発生した。

そして、道具を使い分析すること、ログはインフラの問題解決にとても大事だということ。そしてそれを繰り返すことだ。
関連記事
Twitterがログを科学的に分析してボトルネックを発見、問題解決を行ったときの様子は、次の記事で紹介しています。
また、本文中で紹介されたFlock DBで使われている「Gizzard」の解説は以下です。
大規模システムの運用については、Facebookの事例も詳細に解説した記事を過去に掲載しています。
あわせて読みたい
SIerがコンサルにも利用可能、セキュリティ成熟度をベンチマークできる無料ツール。最新版をIPAが公開
≪前の記事
Twitterの大規模システム運用技術、あるいはクジラの腹の中(前編)~ログの科学的な分析と、Twitterの「ダークモード」

