
Twitterが分散フレームワーク「Gizzard」公開! Scalaで書かれたShardingを実現するミドルウェア
Twitterは独自に開発した分散フレームワークの「Gizzard」をオープンソースとして公開しました。GizzardはScalaで書かれたJavaVM上で動作するミドルウェアで、PHPやRubyといったWebアプリケーションからの要求を自動的にデータベースに分散することで、大規模で可用性の高い分散データベースを容易に実現するためのものです。
Gizzard:フォルトトレラントな分散データベースを実現
Twitterのブログにポストされた「Introducing Gizzard, a framework for creating distributed datastores」では、Gizzardは次のようなものであると説明されています。
Gizzard, a Scala framework that makes it easy to create custom fault-tolerant, distributed databases.
GizzardはScala製フレームワークであり、独自のフォルトトレラントな分散データベースを容易に実現する。
Gizzardは以下の図のように、Webアプリケーションとデータストレージのあいだに入るミドルウェアとなり、Webアプリケーションからのデータの「Sharding」を行うことで分散データベースを実現する構造になっています。
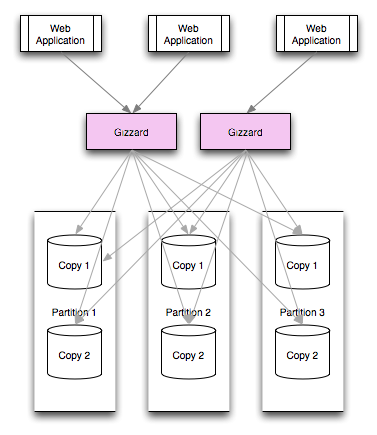 GizzardはWebアプリケーションとデータベースのあいだでShardingを行うミドルウェア。この図はTwitterのエントリ「Introducing Gizzard, a framework for creating distributed datastores」に掲載されていたものを加工
GizzardはWebアプリケーションとデータベースのあいだでShardingを行うミドルウェア。この図はTwitterのエントリ「Introducing Gizzard, a framework for creating distributed datastores」に掲載されていたものを加工Webアプリケーション層では、PHPやRubyなどが典型的なものとされ、データベース層ではリレーショナルデータベースやLucene、Redisなどネットワーク対応のあらゆるデータベースに対応すると説明されています。
Shardingによるデータ分割とレプリケーションを実現
Gizzardの核になっているのが「Sharding」(シャーディング)と呼ばれる技術です。Twitterの説明を借りると、Shardingとは「パーティショニング」と「レプリケーション」の2つの技術からなります。
パーティショニングとは、1つのデータベースをハッシュなどを使って複数の部分に分けることで複数のデータベースに分散すること。レプリケーションは、あるデータのレプリカ(複製)を別のサーバにも作ることです。レプリケーションにより、全体として耐障害性が増すとともに、大量のアクセスに対して複数のサーバが同時にレスポンスできるようになるため性能向上が期待できます。
この2つの技術からなる「Sharding」は、しかし難しい技術だといいます。
The problem is: sharding is difficult. Determining smart partitioning schemes for particular kinds of data requires a lot of thought. And even more difficult is ensuring that all of the copies of the data are consistent despite unreliable communication and occasional computer failures.
問題は、Shardingは難しい、ということだ。データに対して適切なパーティショニングの構造を決定するには多くのことを考慮しなければならない。さらに難しいのは、ネットワークやサーバなどの故障を想定しつつ、すべてのデータの一貫性を実現しなければならないことだ。
そして、既存のオープンソースとして公開されているさまざまなソフトウェアはまだ未成熟だったり制限があったために、独自にGizzardを作ったと。
Unfortunately, as of the time of writing, most of the available open-source projects are either too immature or too limited to deal with the variety of problems that exist on the web.
残念なことに、現時点では多くのオープンソースはまだ未熟だったり、制限があったりする。
トラフィックに対応するための挑戦が続くTwitter
Twitterはめざましい成長の裏で、ずっと「いかに大量のトラフィックをさばくか」という技術的なチャレンジを続けてきました。このチャレンジについては以下の記事でその一部を紹介しました。
上記の記事ではMySQLとMemcachedのボトルネックをいかに克服したか、という内容でしたが、その後Twitterは大量のデータ管理のためにNoSQLデータベースのCassandraを選択したとも伝えられていました。
そして今回のGizzardの発表です。Twitterの技術部門では、大量のデータとトラフィックに対応するためにさまざまな選択肢を検討しているということなのでしょう。

