
Twitterのクジラ解剖学、あるいは彼らがいかにサーバの処理能力を向上させたか
Twitterを利用していると、ときどきクジラの絵の画面が表示されることがあります。これはTwitterの処理能力がパンクして一時的に利用不可になったときに表示されるお馴染みの画面。
2月9日にTwitter Engineeringブログにポストされたエントリ「The Anatomy of a Whale」(クジラの解剖学)では、Twitterのエンジニアたちがこのクジラの内部に分け入ってどのようにTwitterサーバの処理能力を向上させたのか、という話が詳しく語られています。
彼らが行ったのは、まず詳細なデータを取得して原因がどの辺にあるのかを推測すること。そこから多数の無駄な処理を発見し、ソースコードの修正による性能の向上に成功します。
元記事は非常に長いエントリになっていますが、問題の調査から解決に至るアプローチについて多くのエンジニアの方の参考になりそうな内容が含まれていますし、Twitterの内部をかいま見る点でも興味深い内容です。ここではポイントをかいつまんで紹介していきます。
クジラの解剖開始!
まず、クジラの画面についての正確な説明。
It is a visual representation of the HTTP "503: Service Unavailable" error. It means that Twitter does not have enough capacity to serve all of its users. To be precise, we show this error message when a request would wait for more than a few seconds before resources become available to process it.
それは「503: Service Unavailable」のこと。つまり、全ユーザーにサービスを提供するだけのキャパシティが十分ではなくなった状態。もう少し正確にいうと、処理要求に対して、それを処理するためのリソースが利用可能になるまでに数秒以上待たされるようになると、この画面が表示される。
この画面はユーザーからの処理要求が増えたときだけに出るわけではない、とも書いています。
But much more likely is that some component part of Twitter suddenly breaks and starts slowing down.
Twitterのサーバの一部が壊れて遅くなったときにこの画面が出ることもよくある。
壊れるというのは機材の物理的な故障だけでなく、ソフトウェア的なバグのことも含んでおり、Twitterエンジニアリングチームは今回、このバグの原因について調べていくことになります。
Debugging performance issues is really hard. But it's not hard due to a lack of data; in fact, the difficulty arises because there is too much data.
性能に関する問題解決(デバッグ)はとても難しい。それはデータがない難しさではなく、実際にはあまりにも多くのデータがあるから難しいのだ。
I/OかCPUか?
Twitterの処理は大きくI/OのフェーズとCPUのフェーズに分かれており、そのどちらに性能低下の原因が含まれているのかを切り分けるのが最初の作業となります。
Composing a web page for Twitter request often involves two phases. First data is gathered from remote sources called "network services". For example, on the Twitter homepage your tweets are displayed as well as how many followers you have. These data are pulled respectively from our tweet caches and our social graph database, which keeps track of who follows whom on Twitter.
Twitterの要求に対してWebページを作成する処理は2つのフェーズから構成される。最初は「Network Services」と呼ばれ、リモートソースから情報を集めてくる処理。例えば、たくさんのフォローユーザーのつぶやきと一緒にあなた自身のつぶやきも表示されるとき、これらのデータはソーシャルグラフデータベースとつぶやきのキャッシュ(tweet caches)の参照から得られる。
The second phase of the page composition process assembles all this data in an attractive way for the user. We call the first phase the IO phase and the second the CPU phase.
2番目のフェーズはそうして集めたデータを1つのページに組み立てていく処理となる。1番目のフェーズはI/Oフェーズ、2番目のフェーズをCPUフェーズと呼ぼう。
Twitterエンジニアリングチームは、1日のあいだにこのCPUフェーズとI/Oフェーズのレイテンシがそれぞれどうなっているかをグラフ化してみました。
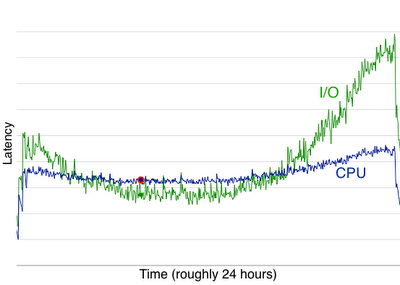 I/OフェーズとCPUフェーズの1日のあいだのレイテンシのグラフ(ブログ「The Twitter Engineering Blog: The Anatomy of a Whale」から引用)
I/OフェーズとCPUフェーズの1日のあいだのレイテンシのグラフ(ブログ「The Twitter Engineering Blog: The Anatomy of a Whale」から引用)するとグラフで分かるように、負荷が低いときにはCPUレイテンシがI/Oレイテンシを上回るのに対し、負荷が高まるにつれてI/Oレイテンシが急激に上昇することが判明します。
これには2通りの解釈があると説明されています。つまり、1日のあいだで利用者がTwitterの使い方に変化がある(恐らく、Webページ経由とAPI経由のこと)、もしくは負荷が高まるにつれてネットワークサービスの性能に何らかの問題があるかです。
ほかのデータなどを参照した結果、Twitterエンジニアリングチームは後者を仮説としてさらに調査を進めます。つまり、I/Oフェーズに問題がありそうだ、ということです。
そこでI/Oフェーズにかかわるさまざまなコンポーネントのレイテンシを計測したところ、以下のグラフに原因らしきものがはっきりと浮かび上がってきました。
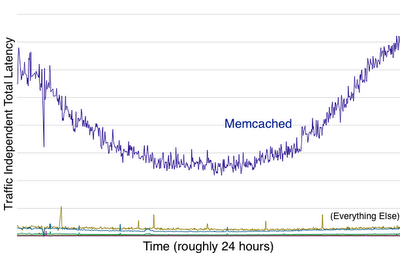 I/Oフェーズの中でMemcachedのレイテンシが大きく変化していることが分かる(ブログ「The Twitter Engineering Blog: The Anatomy of a Whale」から引用)
I/Oフェーズの中でMemcachedのレイテンシが大きく変化していることが分かる(ブログ「The Twitter Engineering Blog: The Anatomy of a Whale」から引用)そうです。Memcachedのレイテンシが、I/Oフェーズのレイテンシの原因となっていることはほぼ間違いないと、このグラフから読み取ることができます。
次は、何がMemcachedのレイテンシの原因となっているか? を突き止めることです。
Memcachedのレイテンシの原因は何か?
Tiwtterエンジニアリングチームはまず、Memcachedへのクエリの実行速度をそれぞれ計測しました。
get 0.003s
get_multi 0.008s
add 0.003s
delete 0.003s
set 0.003s
incr 0.003s
prepend 0.002s
get_multiが遅いことが分かりますが、それ以外は極端に遅くなっているものはなさそうです。続いて、どのクエリが多く呼び出されているのか、その割合を計測しました。
get 71.44%
get_multi 8.98%
set 8.69%
delete 5.26%
incr 3.71%
add 1.62%
prepend 0.30%
ここでははっきりと傾向が読み取れます。getクエリが圧倒的に多くなっています。つまり、問題はgetクエリにある可能性が高まってきました。続いての調査は、どこでどんなgetクエリが処理されているか、です。
彼らはグーグルのパフォーマンスツールや、独自に書き起こしたツールで、ソフトウェアのどのコンポーネントがどのような情報を呼び出しているのか、その依存関係や回数などを徹底的に調査していきました。
Unfortunately, we collected a huge amount of data and it was hard to understand.
膨大なデータを集めたが、残念なことに簡単には理解できるものではない
してもらえないだろう。
Memcachedのクエリを徹底的に削減
その中で、例えばよく使われる過去の履歴データを読み出すのに、多くのMemcacheコールを発行している部分を発見します。以下はその例を引用したものです(コメントを省略しています)。
get(["User:auth:missionhipster",
get(["User:15460619", user id (used to match passwords)
get(["limit:count:login_attempts:...",
set(["limit:count:login_attempts:...",
set(["limit:timestamp:login_attempts:...",
get(["limit:timestamp:login_attempts:...",
get(["limit:count:login_attempts:...",
get(["limit:count:login_attempts:...",
get(["user:basicauth:...",
get(["limit:count:api:...",
set(["limit:count:api:...",
set(["limit:timestamp:api:...",
get(["limit:timestamp:api:...",
get(["limit:count:api:...",
get(["home_timeline:15460619",
get(["favorites_timeline:15460619",
get_multi([["Status:fragment:json:7964736693",
彼らはソースコードを改良し、この17回のコールから無駄な7回のコールの削減などを実行します。これだけでよく使われる機能が42%も性能向上したことになるわけです。
At this point, we need to write some code to make these bad queries go away. Some of them we cache (so we don't make the exact same query twice), some are just bugs and are easy to fix. Some we might try to parallelize (do more than one query at the same time).
この時点で、不要なクエリを排除するためにいくつかのコードを書く必要があった。クエリのいくつかはキャッシュし(同じクエリを2度繰り返さないようにし)、いくつかはバグで簡単に修正できた。いくつかは並列化した(これで同時に多くのクエリが処理できる)。
こうした最適化を続けていき、またハードウェアの改善も並行して行ったことで、Twitterは50%ものキャパシティ改善が可能になった、とこのエントリでは書かれています。
彼らのアプローチは次のような一文でまとめられています。
First, always proceed from the general to the specific. Here, we progressed from looking first at I/O and CPU timings to finally focusing on the specific Memcached queries that caused the issue. And second, live by the data, but don't trust it.
最初に、つねに全体から部分へと処理していく。ここでは、I/OとCPUを調査してから最終的にMemcachedクエリへとフォーカスしていった。2つ目は、データを重視すること、しかし信じすぎてもいけない、ということ。
Publickeyではこれまでに、Facebookやグーグル、Salesforce.comのスケーラビリティに関する内部アーキテクチャについても紹介しています。以下の関連記事もぜひご覧ください。

