
Facebookが大規模スケーラビリティへの挑戦で学んだこと(後編)~キャッシュが抱えるスケーラビリティの問題とデータセンターにまたがる一貫性
全世界で3億人を超える会員を抱え、世界最大のSNSとなったFacebook。同社の技術担当バイスプレジデント Jeff Rothschild氏が、10月8日に米カリフォルニア大学サンディエゴ校で行ったセミナー「High Performance at Massive Scale-Lessons learned at Facebook」の内容を再構成して紹介します。
(この記事は「Facebookが大規模なスケーラビリティへの挑戦で学んだこと(前編)~800億枚の写真データとPHPのスケーラビリティ問題」の続きです)
キャッシュがスケーラビリティに大きな役割を果たしている
Facebookの主な役割は、ユーザーが簡単に(友人たちの)情報を集めることができるだけでなく、情報を作り出すことも容易な点にある。その中心にあるのが「ニュースフィード」というサービスだ。
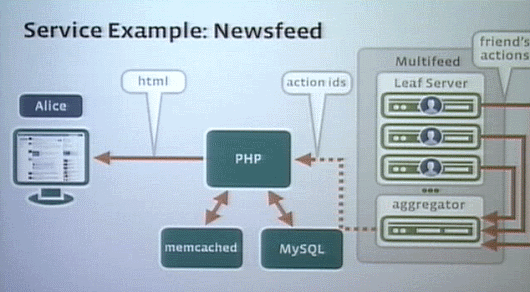
誰かがFacebookで(発言をポストしたり、写真をアップロードしたりして)自分のステータスをアップデートすると、それがリーフノードに伝わる。そしてほかの誰かがページをアップデートすると、そのリクエストがニュースフィードを通じてリクエストを全体に発信し、彼が興味のあるものすべての更新情報を(リーフノードに対して)チェック、それがアグリゲーションされて、PHPレイヤでまとめられWebページが作られ、ユーザーに表示される。
いろんな意味で、こうしたシステムの中心にあるのがキャッシュだ。キャッシュはシステムのスケーラビリティに大きな役割を果たしている。
Facebook では、各ユーザーのデータが連係しているので、1%のアクティブユーザーが自分の情報を変更や追加といった操作をしていても、その結果はほとんどすべてのデータベースにわたって操作されることになる。ここに、ソーシャルアプリケーションのスケーラビリティについての課題がある。
しかしデータの分割ができれば、この課題は比較的簡単に解決する。
5 年前、Facebookが大学生向けのサイトだったときは、バークレイとかハーバードとか大学別にデータベースを持っていて、データを分割していた。主な交流関係は大学内で閉じており、大学間にまたがる関係は、(そういったことが発生する)イベントなどの部分で結べば十分だった。
しかし今はそうではない。ユーザー全体が縦横につながっており、ユーザーはデータベース全体にわたってランダムに分散するように配置している。それだけにスケーラビリティは難しくなっている。
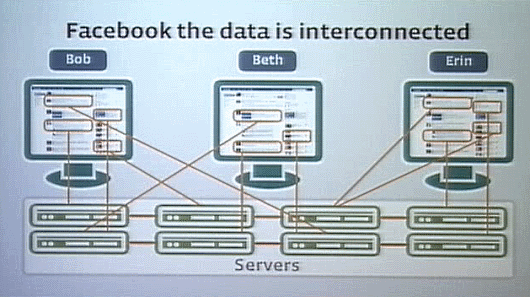
これはつまり自分がページをリドローするとき、何百もの友達に関する大量のデータベースアクセスが発生する、ということである。これを解決するために、非常に高速なキャッシュを採用している。

キャッシュに用いているのがMemcacheだ。Memcacheはクエリ性能を向上してくれる。一方で、Memcacheのデータは容易に壊れやすいという欠点がある。(データが壊れないようにするには)データがデータベースを更新したらキャッシュデータを削除する、というルールにプログラマがみんな従うかどうかにかかっている。

Facebook は大規模運用に耐えるよう、Memcacheも改良してきた。64ビット対応、より効率的なシリアライゼーション、マルチスレッド対応、プロトコルの改良、ネットワークスタックの改良などなど。現在、FacebookではMemcacheが1秒ごとに120ミリオン(12億)のリクエストを処理している。
Memcacheで起こる課題
Memcheを運用していく上での課題の1つは、Network Incastと呼ぶ現象だ。
PHPクライアントがリクエストを出すと、複数のキャッシュからそれぞれ40マイクロセカンドくらいでほぼ同時にまとめて結果が返ってくる。するとスイッチがバッファオーバーランになってパケットが失われてしまうのだ。
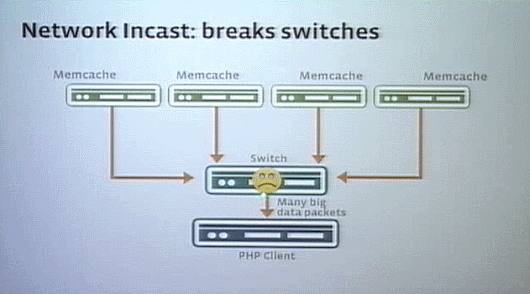
これをなくすために、MemcacheにTCPウィンドウィングに似たオフスライディングウィンドウプロトコルを実装し、応答時間をずらすことで解決した。
ほかにも課題がある。どうやってキャッシュをオーガナイズするかだ。

キャッシュの中で小さいオブジェクトをたくさん扱うサーバは、たくさんのリクエストを処理して返事をするためCPUを多く使う、一方大きなオブジェクトを扱うサーバはデータ送受信のためにネットワークの帯域幅を大量に使う。
そこで、キャッシュに対してオブジェクトの種類をミックスすれば、CPUと帯域幅のリソースをどちらもフルに使うことができそうだ。
しかし、実際にはこんなに簡単なルールは当てはまらない。
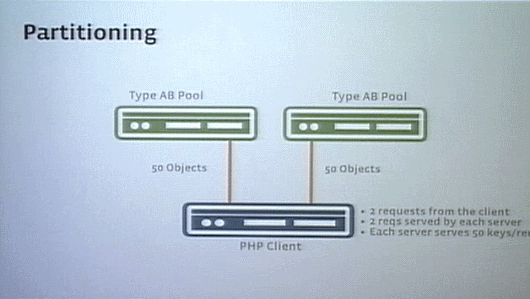
2つの(キャッシュ)プールに、2種類のオブジェクトTypeAとTypeBをバランスよくミックスして配置したとする。クライアントから、TypeAについてのリクエスト、 TypeBについてのリクエストをそれぞれのプールに送るとしよう。すると、どちらのプールもリクエストに応えて、TypeAについてのリクエストに該当するTypeAを50個、TypeBについてのリクエストに該当するTypeBを50個返答してきたとする(つまり2つのプールを合わせると、リクエストに合致するTypeA、TypeBのオブジェクトがそれぞれ100個ずつあるということになる)。
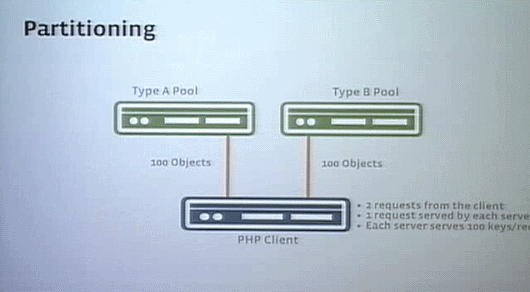
こんどは、(各プールでのオブジェクトのミックスをやめて)2つのプールそれぞれをTypeA専用、TypeB専用にする。そして同じようにクライアントからTypeAについてとTypeBについての2回のリクエストをそれぞれのプールに投げたとする。すると、TypeA専用プールはTypeAについてのリクエストにのみ応え、該当するTypeAを100個返答し、TypeB専用プールはTypeBについてのリクエストにのみ応え、該当するTypeBを100個返答する。この状態でネットワークのバンド幅にも問題がなく、しかも後者の構成の方がリクエストに対して1つのプールの容量が2倍になっているではないか。
別の例を出そう。
2つのプールがどちらもTypeAのオブジェクトを保存しているとする。このプールに対してクライアントが100回のリクエストを投げると、該当する50個のオブジェクトを返すが、すでにリクエストの処理でどちらのプールもCPUがいっぱいになってる。
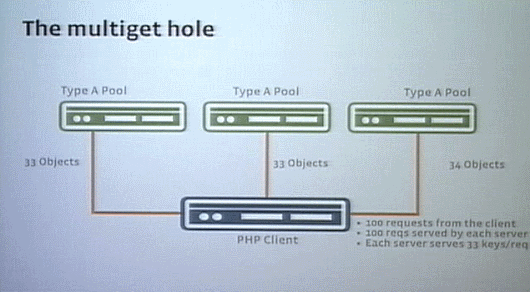
CPU がいっぱいならと3台目のプールを追加してTypeAのオブジェクトを少しそちらに振り分けると、各プールが返答するオブジェクト数は1台あたり50個から33個(もしくは34個)に減るが、各サーバが100リクエストをクライアントから受け取ってCPUがいっぱいなのは変わらずだ。
これを解決するには、(追加したサーバにオブジェクトを振り分けるのではなく)追加したサーバにオブジェクトをレプリケーションする。そしてクライアントがリクエストを分割してそれぞれのサーバに送るようにして、各プールが受け取るリクエスト数を減らせばよい。

このようにリソースの管理というのは非常に複雑で、どのようにデータの分散をオプティマイズするかはとても難しい問題だ。実のところ、プールに対してオブジェクトをどのように分散配置させればいいのか、という最適化は人間がマニュアル作業でやっている。
MySQLは使っているがリレーショナルデータベースとしてではない
Facebookではデータの保存はMySQLサーバを使い、シェアドナッシングアーキテクチャを採用している。シェアードアーキテクチャを用いないのが基本的な原則で、できるだけすべてを独立させておくことにしている。

MySQL はすぐれたリレーショナルデータベースだが、我々はそれをリレーショナルデータベースとしては使っていない。すぐれたデータ保全性(Data Integrity)のために使っている。これまで人間のミス以外に、MySQLのせいでデータが壊れたり失われたりしたことはない。
データセンター間での一貫性を確保する方法
Facebookは最初、サンタクララにあるデータセンターで始めた。そこにはWebティア、Memcacheティア、データベースティアの3層が含まれていた。

その建物がいっぱいになると、サンフランシスコにデータセンターを作った。
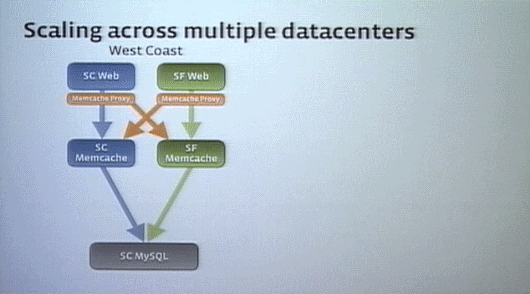
そこにはWebティアとMemcacheティアを入れたが、サンフランシスコとサンタクララはそれほど遠くなかったため、データベースティアはサンタクララを共有するようにした。3~4ミリセカンド余計にかかるが、その程度ならほとんど問題ない。
しかし、それぞれのデータセンターにあるMemcacheティアの一貫性についての課題を解決しなければならなかった。そこで、それぞれのデータセンターにMemcacheプロキシを導入(図のオレンジの部分)。キャッシュ内のデータがデリートされると、プロキシーがそのコピーデータをすべて削除するようにした。
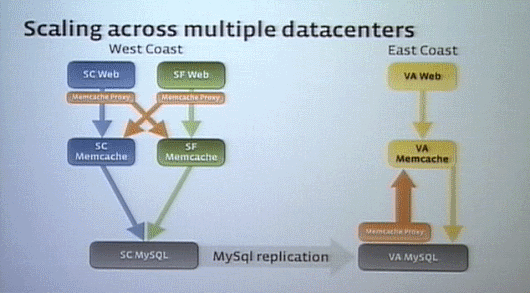
その後、われわれは東海岸にもデータセンターを作った。最初に考えたのは、西海岸と東海岸を結んでキャッシュの一貫性を得るためにMemcacheプロキシを導入することだった。
しかし問題は、Memcacheティアはプロキシーを通して情報を得て、データベースティアはレプリケーションを行っていることで、Memcacheとデータベースのデータの競合状態が発生することだった。

そこでプロキシをMySQLに組み込むことにし、MySQLのデータの変更をMemcacheティアにも同時に行う機能を追加した。これによって、データベースに対する変更は自動的にリモートデータセンター内のキャッシュにも反映されるようになった。
会場から質問:ネットワークのボトルネックについては触れていないが、どうなのか?
ネットワークもボトルネックになっている。特にデータセンターのインターナルネットワークは。リクエストに対して数百台のサーバから返事が返ってくるときのスイッチのオーバーフローに触れたが、特にそうした問題が起こらなくてもネットワークには大きなストレスになっている。
アーキテクチャ的には、もっとWebティアでキャッシュを活用してトラフィックを下げることは検討中だ。しかし、高速なネットワークによってスパイクが発生したときでも対応できるようにするなど、ネットワークはスケーラビリティにとって重要な要素だ。
会場から質問:(マイクがオフで聞き取れず)
Facebookで稼働しているサーバ台数を答えるとき、いつもその台数は間違っている。なぜかというとサーバは増え続けているからね。現在では、3万台程度のサーバがある。
スケーラビリティに関連する記事
これまでにPublickeyで公開した、クラウドのスケーラビリティに関連する記事も参照してみませんか?
あわせて読みたい
仮想化のメリットと課題について、導入済みの大手企業はどう考えているのか?
≪前の記事
Facebookが大規模スケーラビリティへの挑戦で学んだこと(前編)~800億枚の写真データとPHPのスケーラビリティ問題

