
コンテナランタイムの仕組みと、Firecracker、gVisor、Unikernelが注目されている理由。 Container Runtime Meetup #2
Dockerに代表されるコンテナの実行を裏で支えているのが「コンテナランタイム」です。
Dockerが登場した当初、コンテナランタイムはDockerに搭載されているものがほぼ唯一の選択肢でしたが、コンテナの利用が広がりとともに複数の選択肢が登場してきています。
このコンテナランタイムに注目したイベント「Container Runtime Meetup #2」が8月22日にオンラインで開催され、コンテナランタイムの技術や動向についての解説が行われました。
本記事では、その最初のセッションとして行われた太田航平氏による「コンテナランタイム はじめの一歩」を紹介します。
コンテナランタイムとは技術的にどのようなものなのか、現時点でなぜ複数の選択肢が登場したのか、それぞれどのような特徴があるのかが分かりやすくまとまっています。
コンテナランタイム はじめの一歩

太田航平(@_inductor_)です。本職はヒューレット・パッカード・エンタープライズという会社でソリューションアーキテクトをしています。

Docker MeetupとかCloud Native Daysの運営をしながら、無限にスケールするインフラはないかなって、日々もやもやと考えています。
さっそく本題に入っていきましょう。
コンテナってそもそも何ですかっていうと、まず「chroot」というLinuxの機能があって、これはrootディレクトリを特定のディレクトリに切り替えて、そこから下を別のファイルシステムとして確立する、といった技術です。
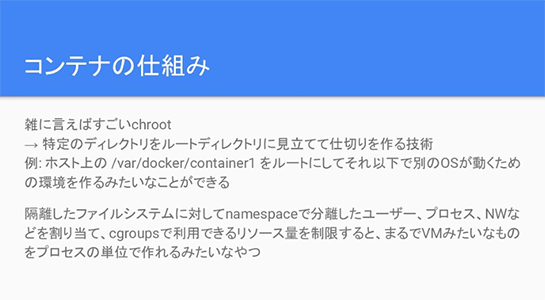
そこに対して「namespace」という機能で、ユーザー、プロセス、ネットワークを個別に割り当てて、さらにリソースにも制限をかけると、まるでVM(仮想マシン)のように動いて面白いね、というのがコンテナですよ、という説明はよくされると思います。
これを図にしました。
まず、対象のディレクトリに対して「pivot_root」という機能を使ってファイルシステムのルートを作ります。
そのうえで「namespace」でそれぞれにrootユーザーを作って、ネットワークやプロセス空間なども切り出して。
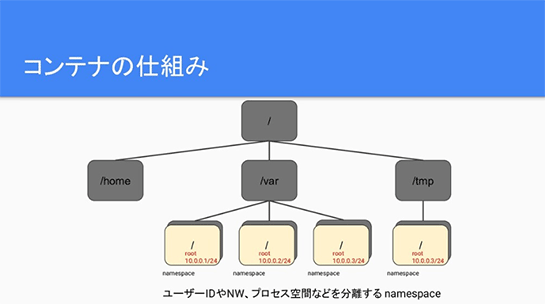
さらにリソースの制限をかけて、そのうえにアプリケーションが動くためのtarファイルのアーカイブを載せて、そのファイルシステムの上でプロセスを立ち上げると、コンテナとして動くわけですね。
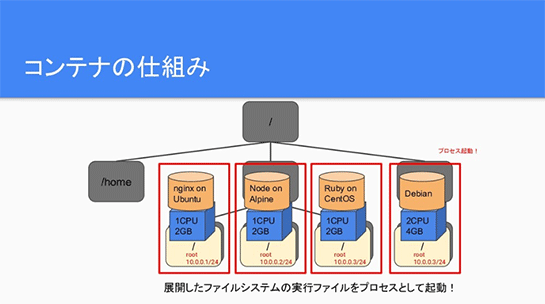
ちなみにこのオレンジの円筒のデータベースみたいなマークはアーカイブファイルですが、これはファイルの実体とかいろいろ入っていて、これのことを「コンテナイメージ」と呼んでいます。
コンテナイメージというのは、DebianだったりUbuntuが動く最低限のファイルシステム群を含んだものをtar形式にアーカイブ化して、レジストリに保存しているわけですね。
コンテナというのはこういうものです、という紹介でした。
高レベルコンテナランタイムと低レベルコンテナランタイム
では、「コンテナランタイム」とはなにしてるんですかというと、いままで説明した作業を全部自動でやってくれるのが、基本的にはコンテナランタイムです。
そしてコンテナランタイムには大きく分けて2つ種類があって、役割がそれぞれ違います。
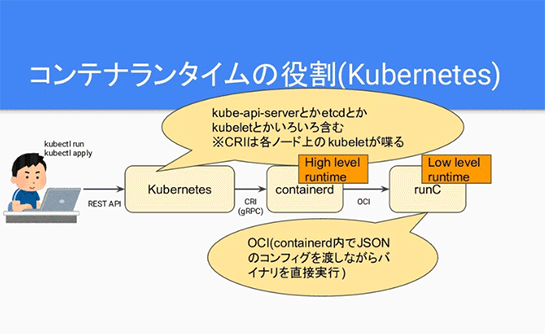
1つが「高レベルコンテナランタイム」です。KubernetesやDockerと直接話して、低レベルコンテナランタイムに渡してくれる役割をしているんですね。これはDockerやKubernetesからの命令を直接受け付ける関係で、ホストOSのうえにdaemonプロセスとして常駐しています。
Kubernetesとやりとりするインターフェイスは決まっていて、それを「CRI」(Container Runtime Interface)と呼びます。CRI自体はgRPC通信で成り立ち、UNIXのソケット通信でgRPCのProtocol Buffersを渡してあげると、containerdとかdockershimなどとやりとりできるようになります。
また高レベルコンテナランタイムは、コンテナイメージを管理する役割も持っています。例えば nginxのイメージをレジストリからpullしてきてローカルに保存したとすると、そのローカルのイメージ管理もこの高レベルコンテナランタイムで行っています。
高レベルコンテナランタイム自体はコンテナを作成しません。そこは低レベルランタイムの役割で、高レベルコンテナランタイムが「docker run」とかそういう命令を受け取ってコンテナを作ってと依頼されたら、じゃあこのイメージがここにあるからコンテナを作ってね、という命令を低レベルコンテナランタイムにお願いします。

低レベルコンテナランタイムはdaemonではなくてバイナリなんですね。なので誰かから実行してもらう必要があり、高レベルコンテナランタイムがこれを実行しています。
低レベルコンテナランタイムは、コンテナの標準仕様「OCI」(Open Container Initiative)に基づいた「config.json」にどういうコンテナを生成するかが書いてあるので、それに従ってコンテナを実際にspawnするのが役割です。
このときに先ほど説明したLinuxのnamespacesやcgroupの処理も行っています。
図にすると、こういう感じです。
Dockerの場合はdockerdがいて、後ろにcontainerdがいて、さらにその後ろにruncがいて、高レベルと低レベルに分かれています。
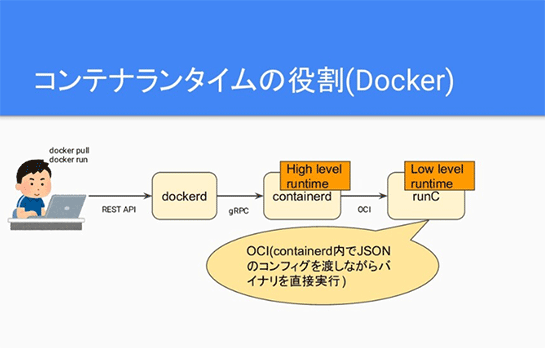
kubernetesの場合はkubernetesがいて、実際にはkubeletがコンテナランタイムとおしゃべりしますが、kubeletがCRIをつかってcontainerdとおしゃべりをして、その後ろにいるruncとOCIでやりとりをしてコンテナを生成します。
「CRI」はkubernetesがコンテナを管理するための標準仕様なので、Cloud Native Computing Foundationという団体が管理しています。
「OCI」はOpen Container Initiativeが標準化した仕様で、コンテナが動くときの仕様は「OCI Runtime Spec」となっていて、コンテナイメージの仕様は「OCI Image spec」となっています。

低レベルコンテナランタイムに脆弱性があるとかなり危険
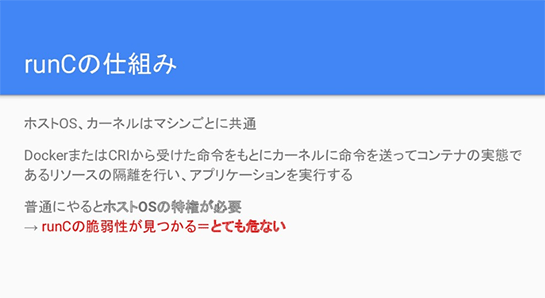
低レベルコンテナランタイムの「runC」は、Dockerの裏で動くコンテナランタイムですが、こんな感じでDockerとかcontainerdがイメージを管理するレイヤがあって、そこから命令を受けてファイルシステムを展開したり、プロセスを初期化したりして、Linuxカーネルのうえでコンテナを作る役割をしています。
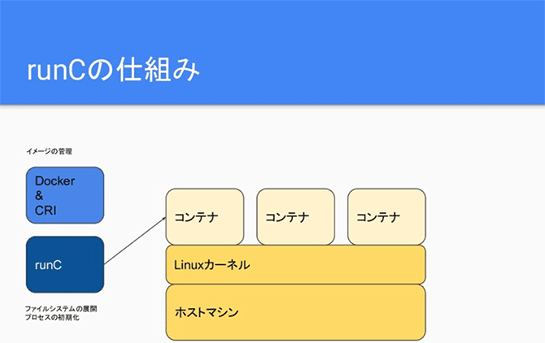
このとき、Linuxカーネルやホストマシンはコンテナ間で共通のものを使っています。なので普通にやるとホストOSの特権が必要なのですね。
なのでrunCの脆弱性が見つかると、あるコンテナの中で特定の処理をするだけでホストOSの特権がとれちゃうみたいな、けっこうあぶない脆弱性が過去に見つかったこともありました。
この危険性をなんとかできないかなと、いろんな人が思ったわけです。
そこで、runCとは違うアプローチで同じことが実現できないかと。OCIという標準仕様を基に、いくつかの団体がいろんなアプローチでより安全なランタイムの実装をしています。
AWSの「Firecracker」やGoogleの「gVisor」などがその代表です。
AWSが作っているFirecracker
FirecrackerはAWSが作っている、microVMという仕組みに基づいたバーチャルマシンモニタです。
microVMは軽量かつ起動が高速で、動的に生成されるVMのこと。
FirecrackerはRust製で、125msくらいの速さで起動します。実際に触ってみると、もうこんなスピードでOS起動がしたのかと思えるほど面白いものになっています。

その仕組みは、Firecracker自体はCLIなどで普通に命令が叩けます。FirecrackerはKVMを採用しているので、ホストOSのカーネルを使ってmicroVMを立ち上げてくれます。そのうえでゲストOSが動いて、例えばUbuntuなども動かせますけど、普通のVMと同じように使えて、軽量で、なおかつ動的に起動できます。
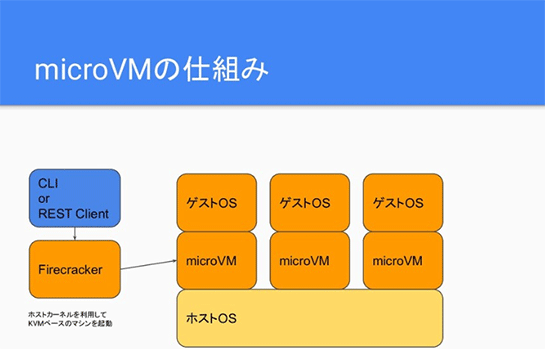
これをどうコンテナとして使うのかというと、「Firecracker-containerd」というオープンソースのプロジェクトがあって、これがFirecracker上でrunCとcontainerdを組み合わせてコンテナを作成できるようにしています。
軽量なVMで、なおかつDockerより軽量なcontainerdの組み合わせによって、Dockerとほぼ同じような形でDockerイメージが動く。
図にすると、microVMの上にゲストOSがひもづいて、そのうえでコンテナが動くと。なのでコンテナをひとつ作成すると、その裏でmicroVMが起動して、でも使う人はそれを気にすることなくコンテナとして使える、ということです。
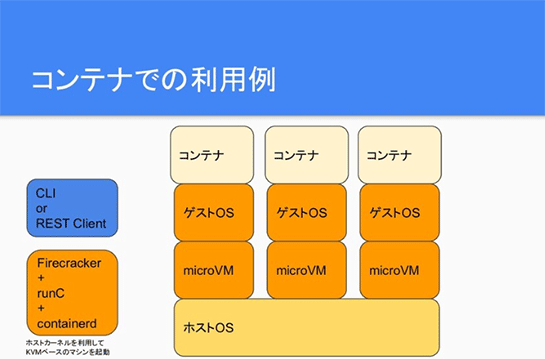
microVMのメリットとデメリットは、既存のVMと比べてもリソースの割り当てが柔軟で、これくらいのリソースでVM作って、というJSONの構成ファイルを投げるとその通りに作ってくれるので、めちゃくちゃ便利です。
REST APIを備えているのでVMの操作が機械的に可能で、起動も高速なのでスケールも速い。しかもVMであるために、ホスト環境との隔離性が高い。
デメリットとしては、VM自体を起動することになるのでそのオーバーヘッドが無視できない環境だと、125msはどうしてもかかるので厳しいのかなあと思います。
Googleが作っているgVisor
一方で、gVisorはGoogleが作っているコンテナランタイムです。ptrace版とKVM版がありますが、ここではptrace版の話だけをします。
gVisorでは、Linux上でgVisorというプロセスを動かすことでゲストカーネルが展開されるんですね。
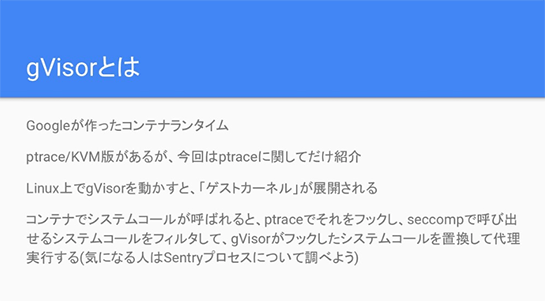
そのうえでコンテナが動くのですが、コンテナの中でシステムコールが必要な場合、ゲストカーネルがそれをフックして、さらに呼び出せるシステムコールをフィルタして、さらにgVisorのなかで、このゲストカーネルがカーネルのふりをしてコンテナの中に処理を返します。

つまりコンテナにカーネルのふりをするLinux上のプロセスがgVisorです。
さっき言ったmicroVMとはまったく違うアプローチだということがお分かりいただけると思います。
Unikernelを採用した「Nabla Container」
時間がありそうなのでUnikernelの話もしましょう。
Linuxにはカーネルがありますが、ひとつのカーネルにいろんなものを詰め込んでいます。これを一般的にモノリシックカーネルと呼びます。
Unikernelはそれとは逆で、あるアプリケーションを動かすのに必要なものだけを含んだカーネルのことを指します。使わないものは一切排除してしまって、あたかもアプリケーションライブラリのような形でOSを動かすのです。

これが「Unikernel」と言われているものです。ですので、軽いし、速いし、セキュアだという特徴があります。
コンテナとしては、IBMが作っている「Nabla Container」プロジェクトでUnikernelを採用しています。
Nabla Containerでは「Runnc」というランタイムがあって、これがgVisorと似たような形でSeccompでフックしてシステムコールの制限をかけます。OSには必要なコンポーネントしか入っていないので、悪いことをしようとしてもできない、ということになります。

ただ、Unikernelはカーネルが(通常のLinuxとは)全く違うものを使っているので、既存のDockerイメージをそのまま使うことはできないんですね。なのでDockerイメージのビルドのやり直しが必要になります。
ですからあるアプリがあるとき、それをNabla containerで使おうとするときにはNabla container用のDockerイメージを再度作る必要があります。
図としてはこのような形です。

Runncがホスト上にあり、専用にビルドされたバイナリを読みだして、そのうえでコンテナが実行される、という感じになります。
Unikernelは、FirecrackerのようなVMと違ってホスト上でプロセスとして動くので高速で、しかもただのプロセスなので軽量です。カーネルの機能も絞られているためホストとの接点も小さく、セキュアでもあります。
ただUnikernelは知名度が低く、知見もあまりないため一般に導入のハードルが高く、イメージの再ビルドも必要なので、そこも導入の大変さがあると思います。
まとめ
このセッションのまとめです。

ありがとうございました。
公開されているスライド
あわせて読みたい
Googleが10年以内に、全データセンターとオフィスを二酸化炭素を排出せずに生産したエネルギーでまかなうと宣言
≪前の記事
Amazon Redshiftが単一クラスタあたり最大10万テーブルまで対応へ。これまでの2万テーブルから拡大

