
Google、大規模データをリアルタイムに分析できるクラウドサービス「Google Cloud Dataflow」を発表。「1年前からMapReduceは使っていない」。Google I/O 2014
大規模分散処理のフレームワークとしてGoogleが開発し、Hadoopに採用されて広く使われているMapReduce。しかしGoogleはもうMapReduceを使わず、より優れた処理系の「Google Cloud Dataflow」を使っていることが、Google I/O 2014の基調講演で明らかにされました。

GoogleのシニアバイスプレジデントUrs Hölzle氏は、「エクサバイトのスケールまで扱え、パイプライン処理を記述しやすく最適化もしてくれる。それにバッチもリアルタイム分析も同じコードで記述できる」と、Cloud Dataflowの特長を説明します。
Google I/Oの基調講演から、Google Cloud Dataflowの解説部分を紹介します。
バッチ処理もストリーム処理も同一コードで書ける
Cloud Dataflowはシンプルなフルマネージドサービスで、データの取得、変換、分析、分類の一連の処理をバッチでもリアルタイムでも処理できる。
プログラマが分析処理のプログラムを書き、Cloud Dataflowに送ると、最適化、展開、スケジューリング、モニタリングをCloud Dataflowが行ってくれる。

デモとして、ワールドカップ関連の何百万ものツイートを、それぞれネガティブかポジティブかを分析し国別に分類する、というものを作ってみた。
まずはCloud Pub/SubからのJSONストリームを受け取る。ここではパイプラインをストリームモードで動作させているが、バッチモードもできる。

次にデータ変換やマッピングを行う。Google Translate APIなどを使えるし、並列処理を最適化してくれる。
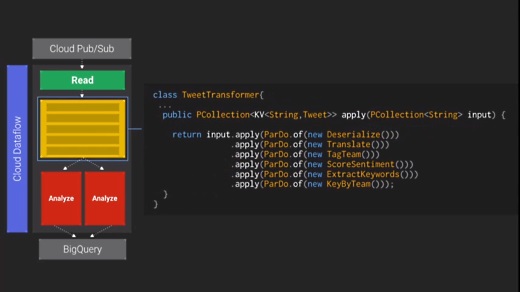
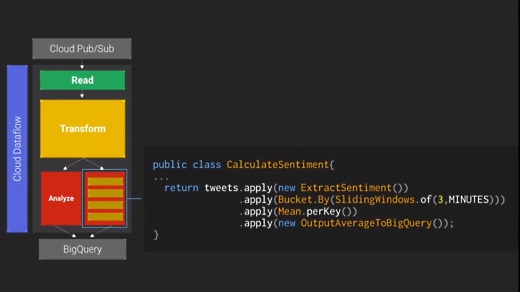
そしてデータ分析の部分。ここでは3分間のスライディングウィンドウを設定し、それに対して分析を行う。データのシャッフリングなどは全部Cloud Dataflowがやってくれるので、プログラマが心配する必要はない。
Dataflow Consoleから管理画面を呼び出すと、処理のトポロジーが分かりやすく表示される。これまでに524万ツイートを処理したようだ。
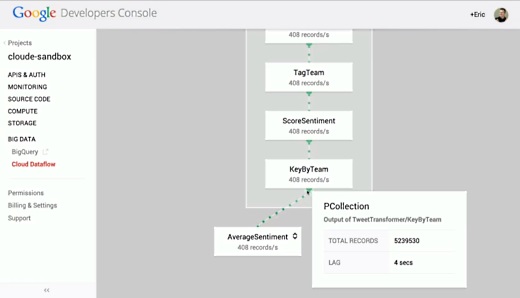
Googleが1年前にMapReduceの利用をやめた理由がお分かりだろう。Cloud DataflowはMapReduceでステップごとに実行していたパイプライン全体を提供し、しかもスケーラビリティや並列性をプログラマが心配する必要はない。そして他のあらゆるシステムよりも高速かつスケーラブルなのだ。
なぜこうしたものを作ったかといえば、それは我々自身がこのようなものを必要としていたからである。

Google I/O 2014
- [速報]Googleが新しいUXの体系「Material Design」を発表。あらゆるデバイスとスクリーンに適用。Google I/O 2014
- [速報]次期Android「L」は新VM「ART」を採用。従来のDalvikの2倍の性能、64ビットフル対応。Google I/O 2014
- [速報]Google Appsで、Word/Excel/PowerPointファイルを変換せずそのまま編集、保存可能に。Google Driveは容量無制限へ。Google I/O 2014
- Google、大規模データをリアルタイムに分析できるクラウドサービス「Google Cloud Dataflow」を発表。「1年前からMapReduceは使っていない」。Google I/O 2014
あわせて読みたい
[PR]物理サーバ群をクラウドのように利用可能。性能オーバーヘッドなし、故障時にはすぐ新サーバへ。ベアメタル型アプリプラットフォーム
≪前の記事
[速報]Googleが新しいUXの体系「Material Design」を発表。あらゆるデバイスとスクリーンに適用。Google I/O 2014

