
グーグルのBigQuery、高速処理の仕組みは「カラム型データストア」と「ツリー構造」。解説文書が公開
SQLのクエリに対応し、3億件を超えるデータに対してインデックスを使わないフルスキャン検索で10秒以内に結果を出す。グーグルのBigQueryは大規模なクエリを超高速で実行する能力を提供するサービスです。その内部を解説する文書「An Inside Look at Google BigQuery」(PDF)を公開しました。
グーグルは大規模クエリを実行するサービスとして社内でコードネーム「Dremel」を構築しており、2010年にそのDremelを解説する文書「Dremel: Interactive Analysis of Web-Scale Datasets」を公開しています。BigQueryは、そのDremelを外部公開向けに実装したものです。
グーグルはこのDremel/BigQueryが持つ大規模分散クエリの能力を活かして、以下の分野で活用しているとのことで、グーグルの社内プラットフォームとしても重要なサービスになっています。
- クロールしたWebページの分析
- Android Marketでインストールされたアプリケーションのデータ追跡
- Google製品のクラッシュレポーティング
- Google BooksのOCR結果
- スパム分析
- Google Mapsのマップタイルのデバッグ
- 数十万のディスクのモニタリングジョブの統計分析
- グーグルのデータセンターのモニタジョブ
カラム型データストア
公開されたドキュメントによると、Dremel/BigQueryが高速にクエリを実行するために備えている特徴が「カラムナストレージ」(Columnar Storage、カラム型データストア)とツリーアーキテクチャ(Tree architecture)です。
カラム型データストアは、通常のデータベースでは1行ごとにまとまって格納されるデータを、列(Column)ごとにまとめて格納する方式です。
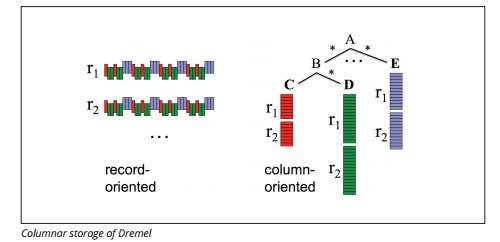
グーグルはこの方式には以下の利点があると説明しています。
- トラフィックの最小化
クエリ対象となる列のデータだけにしかアクセスしないため、トラフィックが最小化できる。例えば「SELECT top(title) FROM foo」(fooテーブルからtitle列の1番となる値を取得する)というクエリならば、title列だけを縦にずらっとアクセスすればいいだけです。 - 高い圧縮率
ある研究によると、通常のデータベースでのデータ圧縮率は3対1なのに対し、カラム型データストアの圧縮率は10対1にまで達するとのこと。その理由として、同じ列に含まれるデータは類似性が高く、カーディナリティ(いわゆるデータのばらつき)が小さいためです。
ただしカラム型データストアには欠点もあります。それはデータの更新操作が苦手なこと。Dremel/BigQueryでもこの欠点は同様であり、アップデートの操作は用意されていません。
こうしたカラム型データストアの特徴については、Publickeyの以前の記事でも触れています。
ツリーアーキテクチャ
BigQueryのもう1つの特徴が、クエリを大規模分散処理に展開するためのツリーアーキテクチャです。
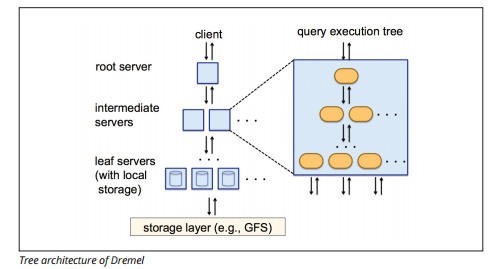
クライアントからクエリを受け取るroot serverから、実際にクエリ処理を実行する多数のleaf serversに対して、クエリがツリー構造で広がっていくことで、大規模分散処理を実現しています。
この2つのテクノロジーが、Dremel/BigQueryの高速性のカギだと説明されており、MapReduceと比べてアドホックなクエリの繰り返しが得意で、OLAPやMOLAPに比べてフルスキャン性能がきわめて高い点が利点だとしています。
あわせて読みたい
マイクロソフトはYammerからDevOpsを学ぼうとしている
≪前の記事
Engine Yard、クラウドと同じRoR/PHP/Node.js環境をローカルに構築する「Engine Yard Local」無償公開

