
最近話題の「カラム型データベース」とはどんな仕組みのデータベースか?
トランザクション処理を重視する一般的なデータベースは、1行ごとにデータを扱う。カラム型データベースはそれとは異なり、列方向にまとめでデータを扱うことで集計作業などを得意とし、データウェアハウス用途などに用いられている。
「カラム型」あるいは「カラムストア型」「列指向型」などと呼ばれるデータベースの話題が目立つようになってきました。
例えばSAPのHANA、IBMが買収したNetezza、ヒューレット・パッカードが買収したVertica、オラクルのExadata、それにNoSQLの代表的なデータベースCassandraなどがカラム型データベースの機能を備えています。また、マイクロソフトの次期SQL Serverにもカラム型データベース機能が統合されると伝えられています。
とはいえカラム型データベースは最近登場した技術ではなく、Sybase IQでは10年以上前から採用されていた仕組みでした。
カラム型データベースとはどのような仕組みのデータベースで、従来のデータベースとどこが違い、なぜ最近になって注目されているのでしょうか?
カラム型データベースについては、2009年の記事「カラムナデータベース(列指向データベース)とデータベースの圧縮機能について、マイケル・ストーンブレイカー氏が語っていること」で取り上げたのが最初でした。あれからいくつか調べたことなども含め、もういちどここで整理しておこうと思います。
ちなみに冒頭にも書いたように、カラム型データベースという呼び方以外にも、列指向、カラムストア、Columnar Database(カラムナデータベース)など、さまざまな呼び方がされているようです。
行指向とカラム型(列指向)の特徴
通常のリレーショナルデータベース、例えばMySQLやOracleやDB2やSQL Serverなどは「行指向」のデータベースです(一般的なデータベースは行指向であるため、明示的に「これは行指向のデータベースです」という言い方をすることはほとんどありませんが)。
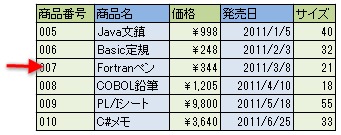
行指向のデータベースでは、1つ1つの行をひとかたまりのデータとして扱います。データの追加も行単位で行われますし、検索結果も複数の行として返ってきますし、削除や更新の際には特定の行をカーソルなどが差し示したうえで、その行に対して更新や削除といった操作が行われます。
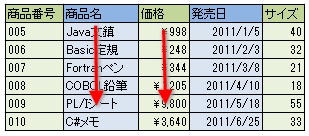
一方でカラム型データベース、つまり列指向のデータベースは、列方向にデータをまとめて扱います。そのため、特定の列の値をまとめて処理することに非常に長けています。例えば、あるテーブルから商品名と価格だけを抜き出す処理などは非常に得意です。逆に、特定の行を抜き出して更新したり削除したりするのは苦手です。
一般に、行指向のデータベースではディスクへのデータの書き込みが行ごとの読み書きに最適化されており、カラム型データベースでは列方向に最適化されています。
まとめると、一般的な行指向のデータベースは、追加更新削除のようなオンライントランザクション処理が得意で、カラム型データベースでは列を抜き出して操作する集計処理などが得意です。
圧縮と並列処理も得意
カラム型データベースでは、データ圧縮の効率が高いというもう1つの特徴があります。
列方向にデータを見ていくと、データ型が揃っていることもあって値が似ていたり、同じ値が繰り返し表れることがよくあります。そのために列方向のデータは非常に圧縮効率が高いのです。
また、データの集計や分析が中心となるカラム型データベースのユースケースでは、データの一貫性を維持するためのロック処理がほとんど必要ありません。そのため分散処理、並列処理を実装しやすいという特徴も備えています。
カラム型データベースが注目される理由
カラム型データベースは得意の集計処理やデータ圧縮処理を活かして、ビジネスインテリジェンス用のデータベースとして主に使われています。Sybase IQ、HANA、Netezza、Vertica、Exadataなどはどれもそうした用途中心の製品なのです。
これまで分析用のデータベースは、高速な検索や結合処理を実現するためにインデックスを多用し、そのため元のデータの何倍もの容量を必要とすることがほとんどでした。しかしビッグデータの時代を迎えたいま、分析のためとはいえ元のデータ量の何倍ものディスク容量を必要とすることはコストの面でもストレージ管理の面でも現実的ではなくなりつつあります。
そのため、オリジナルデータに対して圧縮が効いて数分の一の大きさになり、しかも集計処理も得意で、分散処理でスケールアウトしやすいカラム型データベースが注目され始めたのだと考えられます。
インメモリとカラム型データベースの可能性を調べる
HANAには、これまで主流だったリレーショナルデータベースとは異なる2つの技術的な特長があります。1つはデータベースをメインメモリ上に保持する「インメモリデータベース」、もう1つはデータを列(カラム)指向で処理する「カラム型データベース」です。 この2つの技術はいま、主要なデータベース製品にも次々に採用されています。
あわせて読みたい
エンタープライズ向けのFirefoxに踏み出すモジラ
≪前の記事
2011年6月の人気記事トップ10!「JavaScriptと性能についての本当の話」「サーバは液体のよう流れる」「データベースのスケーラビリティ」

