
カラム型データベースはなぜ集計処理が高速で、トランザクションが苦手なのか。インメモリとカラム型データベースの可能性を調べる(その4)
現在主流となっているOracle、SQL Server、DB2などのリレーショナルデータベースは事実上すべて、行(ロー)指向で内部の処理を行っています。一方で、最近急速に注目されているのが、列指向で内部処理を行い、大量データの集計や分析処理に優れた「カラム型データベース」(あるいはカラム指向データベース、カラムナーデータベース)です。
カラム型データベースはSybase IQやNetezza、Verticaなどデータウェアハウス専用のデータベースで主に採用されています。また、SQL Serverには「ColumnStore Index」、Oracle Exadataには「Hybrid Columnar Compression」と呼ばれるカラム型データベースの技術が搭載されています。これらも集計や分析処理を高速に行うためのものです。
カラム型データベースはもっぱら集計や分析専用の技術として生まれ、その利点がビッグデータの時代に注目され実装が広がってきました。しかし、そのカラム型データベースでデータの追加削除更新などを伴うトランザクション処理も高速に実現する、という製品が登場しました。SAP HANAです。
本当にそんなことができるのか?
2010年にSAPがHANAを発表し、カラム型データベースエンジンでトランザクション処理も行うと発表したとき、本当にそんなことができるのか、非常に疑問に思いました。しかしHANAはその後バージョンアップを重ねて実際にトランザクション処理を実装し、同社のERPソフトウェアのバックエンドとして機能するようになっています。
HANAはどのような仕組みでカラム型データベースでトランザクション処理を実現しているのでしょうか。その仕組みを説明する前に、なぜカラム型データベースは集計処理が得意なのか、そしてなぜトランザクション処理が苦手なのかについて見ていきましょう。
カラム型データベースはなぜトランザクションが苦手か?
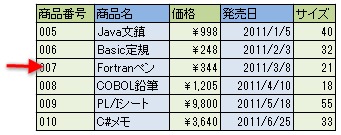
通常のリレーショナルデータベースは「行」指向で処理を行います。ある条件に対する検索結果を求めるときには、データベースから1行目を取り出して条件に合っているかをチェックし、次に2行目を取り出してまた条件に合っているかをチェックし、という作業を順に繰り返していきます。
棚卸しのために、いま在庫として持っている商品の価格を全部足し合わせる集計処理を行うときには、在庫データから1行目を取り出し、その中から価格の列を抜き出して足し算、2行目を取り出し、その中から価格の列を抜き出して足し算、という処理を繰り返します。
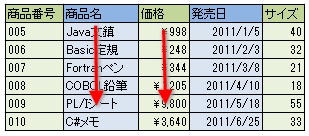
一方でカラム型データベースは列指向で処理を行います。列方向にデータをまとめて保存しており、列方向に読み込んで処理するため、列方向の処理に非常に長けています。
在庫の価格を全部足し合わせる集計処理では、在庫データから価格の列だけを読み込んでまとめて足し算できるため、それ以外の列のデータを処理する必要がありません。そのため、行指向のデータベースに比べると非常に短時間で処理できます。
カラム型データベースでは、データ圧縮の効率が高いというもう1つの特徴があります。 列方向のデータは同一のデータ型であり、しかも住所や氏名、価格など特定の種類のデータが並んでいるため、ばらつきが小さく同じ値が繰り返し表れることも多いため、圧縮効率が非常によいのです。
列方向へのデータ圧縮は、列指向の処理をさらに高速にします。ある列を10分の1に圧縮できたのならば、その列を読み込む時間も10分の1になるからです。カラム型データベースとデータ圧縮は、セットで実装されているのが一般的です。
Oracle Exadataの資料によると、通常の行指向データベースでの圧縮(BASIC・OLTP圧縮)が3分の1から5分の1程度なのに対し、カラム型データベース機能のHybrid Columnar Compressionでは10分の1から50分の1にまでデータを圧縮できると説明されています。列方向の圧縮の効率性がおわかりでしょう。
1件追加するごとに、データの追加処理や展開圧縮が何度も行われる
データの集計や分析は極めて高速に行えるカラム型データベースですが、データの追加や削除、更新といった処理を行おうとすると、そのデータ構造がとたんに性能の足をひっぱります。
例えば、データを1件追加することを考えましょう。データ1件には商品名と価格と個数の列が含まれているとします。従来の行指向のデータベースなら1行の追加が1回の処理で済みます。ところがカラム型データベースは列方向にデータが保存されており、列方向にデータを操作するので、この1件を追加するのには商品名の列を読み込んでデータを追加、価格の列を読み込んでデータを追加、そして個数の列を読み込んでデータを追加と、追加処理が3回走ります。
しかもデータベースが列ごとに圧縮されているとすれば、列ごとに圧縮データを展開し、データを追加。そして再び圧縮しなくてはなりません。データの削除や更新でも同じことです。
いかにインメモリデータベースが高速だとしても、カラム型データベースでデータの追加更新削除などの処理は、そのままでは非常に遅くなってしまう構造になっているのです。
これが、カラム型データベースの集計や分析処理が高速な理由、そして追加更新削除を含むトランザクション処理が苦手な理由です。
このトランザクション処理が苦手なカラム型データベースに対して、SAP HANAはどのような実装で対応したのでしょうか。次の記事で見ていきましょう。
≫次の記事「カラム型データベースでトランザクション処理を実現するカラクリとは? インメモリとカラム型データベースの可能性を調べる(その5)」に続きます。
インメモリとカラム型データベースの可能性を調べる
- インメモリデータベース、カラム型データベースは使い物になるのか? インメモリとカラム型データベースの可能性を調べる(その1)
- 従来のデータベースをメモリに載せるだけではだめなのか? インメモリとカラム型データベースの可能性を調べる(その2)
- インメモリデータベースでサーバが落ちたらデータはどうなる? インメモリとカラム型データベースの可能性を調べる(その3)
- カラム型データベースはなぜ集計処理が高速で、トランザクションが苦手なのか。インメモリとカラム型データベースの可能性を調べる(その4)
- カラム型データベースでトランザクション処理を実現するカラクリとは? インメモリとカラム型データベースの可能性を調べる(その5)
あわせて読みたい
カラム型データベースでトランザクション処理を実現するカラクリとは? インメモリとカラム型データベースの可能性を調べる(その5)
≪前の記事
インメモリデータベースでサーバが落ちたらデータはどうなる? インメモリとカラム型データベースの可能性を調べる(その3)

