
FacebookにおけるMySQLを用いた大規模システムアーキテクチャの現実~MySQL Connect 2013
米オラクルが主催するMySQLのイベント「MySQL Connect」が9月21日から23日まで、サンフランシスコで開催されました。Oracle OpenWorld、JavaOneとの同時開催でした。
基調講演の1つには、MySQLのヘビーユーザーであるFacebookのHarrison Fisk氏が登壇。FacebookにおけるMySQLの役割、大規模運用の背景などを紹介しています。その内容をダイジェストで紹介しましょう。
MySQL@Facebook Lots and lots of small data
Harrison Fisk氏。
Facebookでデータパフォーマンスチームのマネージャをしている。社内ではMySQLはもちろん、HBase Hadoopなどにも関わっている。

まずは、どんな種類のデータをMySQLで扱っているのかについて。
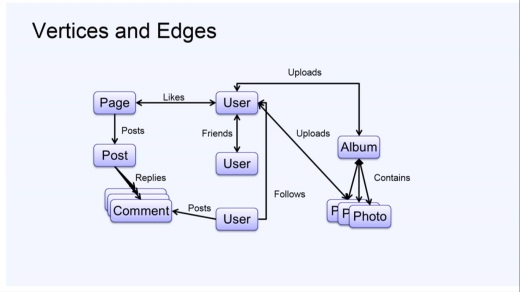
Facebookとは基本的にグラフだ。グラフにはVertices(頂点)とEdge(端)がある。図ではページ、ユーザー、コメント、写真、アルバムなどがあるが、これらがVertices、あるいはObjectsと呼んでいる。Likes(いいね)、友人、アップロードなどはEdgeであり、一方向だったり双方向だったりする。
ビッグデータと呼ばれる分野で出てくるHadoopやデータウェアハウスの多くでは、バッチ処理でデータが分析されたりする。
しかしFacebookではMySQLのデータはリアルタイムにアクセスされている。あなたがFacebookのページ上でフレンドリストを参照したとすると、そのデータはMySQLから引き出されたものかもしれない。
だからわれわれは、ペタバイト級のデータに対して1桁ミリ秒単位でレスポンスタイムを考える。
いくつかの数字を示そう。

(1秒あたり1120万件の更新)
これはピーク時の最大処理速度だ。このほとんどが写真やコメントといったユーザーによって生成されたデータであり、それらがMySQLで処理されていく。その処理にはインサートもアップデートも、もちろんデリートもある。われわれはデータのデリートもしているんだ。

(1秒あたり6060万回の検索処理)
どれだけのリクエストがユーザーから来ているのか、ということ。

(1秒あたり25億件の読み込み)
これはキャッシュ後のデータ読み込みだけれど、これだけの件数がユーザーに届けられている。
Facebookのページはすべてが動的生成だ。例えば「いいね」といった小さな要素もページを構成しており、データアクセス件数の増加の要因である。こうしたさまざまな種類のデータがリアルタイムにデータベースから取得されてFacebookのページが生成されている。
さらにFacebookユーザーは世界中に広がっており、地理的にまったく分散している。
Facebookはこうしたデータを扱っている。
Facebookアーキテクチャ概要
こうしたデータをFacebookがどう管理しているのか、ソフトウェア構造を見ていこう。これが全体像だ。
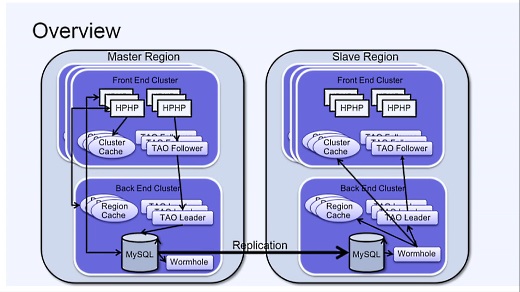
マスターリージョンとスレーブリージョンの2つに大きく分かれていて、この2つは地理的にも離れている。
それぞれのリージョンには、複数のFront End ClusterとBack End Clusterがある。
Front End ClusterにはWebサーバがあり、そこではHPHPが動いている。クラスタごとにキャッシュも用意されている。
Back End ClusterにはMySQLデータベースがあり、キャッシュもある。マスタリージョンとスレーブリージョンのあいだではMySQLのレプリケーションが行われている。
それぞれを見ていこう。
Facebook独自のPHP
HPHPは、Facebook独自のPHPであり、Facebookが自社用に作っている。
理由の1つは性能向上のためだ。HPHPには2つのバージョンがあり、1つはコンパイルバージョンで、PHPをC++に変換し、それをバイナリにコンパイルすることで、実行時の処理が軽くなる。
もう1つはJavaVMのようにPHPをバイトコードに変換してVM上で実行するものだ。これもCPUの処理負荷を軽くできる。
キャッシュにはMemcacheを利用
次はMemcache。オープンソース版だがいくつかの拡張を加えている。
Front End ClusterにはCluster Cacheがあり、ここには非常にホットな最新のデータが入っている。例えば(米アイドルの)ジャスティン・ビーバーが写真を投稿すれば超注目されることは分かっているので、そのデータはそれぞれのクラスタのCluster Cacheに入り、それぞれのクラスタはそこへアクセスする。
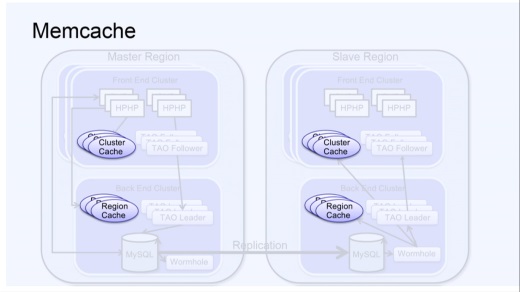
Cluster Cacheはそれにより負荷を分散する役割があるため、Webサーバの近くにあることが大事なのだ。
Region Cacheはデータベースへのアクセスを回避して高速化するためのキャッシュだ。
TAOはわれわれが開発したもので、基本的にはMemcacheをベースにしたカスタムなグラフサーバだ。Facebookのグラフモデルを理解している。
WormholeはPub/Subシステムで、MySQLがログをここに書くと、その内容をほかにディストリビューとしていくというものだ。
MySQL 5.6へマイグレーション中
MySQLは5.1を使っている。これはFacebookがヘビーにカスタマイズしたもの。非同期クライアントライブラリや性能改善のためのパラレルスキャン、ダンプ最適化、モニタリング機能などを社内で開発しており、Facebookの環境で優れた性能をだせるようにしている。
現在MySQL 5.6へのマイグレーションに取り組んでいて、数台が本番で使われ始めている。数カ月でマイグレーションが完了するだろう。
Facebook内部で数多くのレプリケーションを行っているため、MySQL 5.6の新機能ではMulti Thread Slaveに期待している。
MySQL運用自動化のツールを利用
運用について。どうやって世界中にある何千何万ものMySQLを管理しているか。そのためのツールとしてMySQL Pool Scannerを作った。
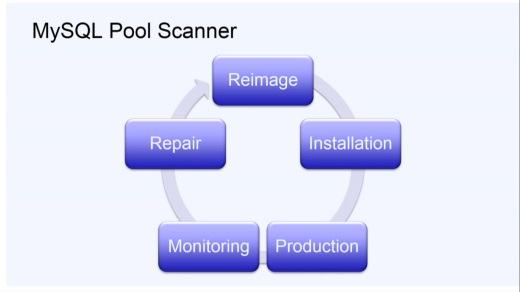
これは自動化システムで、マシンが本番環境に向かってどれだけ進捗しているかを報告してくれる。
例えばまっさらなサーバが配備されると、OSなどのイメージを入れてMySQLをインストール、必要なデータをサーバへコピーして本番投入となる。
本番稼働中はモニタリングを行い、壊れれば修理し、再びイメージを入れ直していく。
ストレージ活用のため圧縮が重要に
Flash/Flachcacheの2種類のストレージを使っている。

Facebookでは高速なストレージとして100%SSDを用いたシステムを採用している。
しかしつねにこれが最良のものとは行かないのは、コストが高いためだ。そこでSSDと巨大な容量のHDDを組み合わせることで、大容量かつSSDで高速アクセスを実現する。

圧縮はいまのわれわれにとって非常に重要だ。なぜなら多くのフラッシュストレージを使っていて、そこには容量的な制約があるからだ。
その制約を乗り越えるために圧縮は非常に重要であり、いまでは本番データのほとんどには圧縮がかかっている。
私たちは優れた圧縮のためにリソースを投入しており、現在のところ非常にうまく機能している。
MySQL Connect 2013
あわせて読みたい
さくらのクラウドがアベイラビリティゾーン提供。設備を完全に分離した第二ゾーンが10月から稼働開始
≪前の記事
ニフティクラウドが、モバイル向けBaaS「ニフティクラウド mobile backend」を提供開始。ストレージ5GB、プッシュ通知やAPIリクエスト月間200万回までは無料

