
東証がSREによるレジリエンス向上に挑む理由。過去のシステム障害から何を学んだのか?(前編) ソフトウェア品質シンポジウム2022
9月22日と23日の2日間、一般財団法人日本科学技術連盟主催のイベント「ソフトウェア品質シンポジウム2022」がオンラインで開催され、その特別講演として株式会社日本取引所グループ 専務執行役 横山隆介氏による「日本取引所グループシステム部門の取組み ~システムトラブルからの学びと今後の挑戦~」が行われました。
現在、日本取引所グループ傘下の東京証券取引所(以下、東証)は、過去に何度か大きなシステムトラブルを経験し、それを教訓として組織とシステムの改善を続けています。
そこで今回、シンポジウム企画委員会からの要望を受けて行われた特別講演で、東証がこれまでのシステム障害から何を学び、そこから何を変化あるいは進化させてきたのか。わずか2年前のNASのハードウェア障害への振り返りも含めて語られます。
その上で、先進的な運用の取組みとされるSREに東証がなぜ挑戦しているのか、その理由と背景についても説明されました。
本記事はその講演の内容をダイジェストとしてまとめたものです。本記事は前編と後編で構成されています。いまお読みの記事は前編です。
システムトラブルからの学びと今後の挑戦
日本取引所グループの横山と申します。本日は、こういう貴重な機会をいただきましてありがとうございます。

東京証券取引所は過去数度の大きなシステム障害を経験しておりまして、それらからの学びを披露しつつ、皆様の何かしらお役に立てればと思っております。
自己紹介をさせていただきますと、私は日本取引所グループ(JPX:Japan Exchange Group)という持ち株会社においてCIOをしておりまして、グループ全体のITを見る立場をやらせていただいております。

今から35年前に大学を卒業して当時の東証に入りました。当時、東証にCIOという役職は当然のこととしてありませんでしたし、ITを使っていろんな業務を行っているという説明を就職活動のときに受けたこともありませんでした。
ですからシステムを使って仕事をするという感覚もなく会社に入って35年働いているのですが、振り返ってみると、いわゆる業務部門とIT部門の経歴が半々程度になっています。
日本取引所グループ(JPX)ついて
JPXは持ち株会社で、2013年に東証と大阪証券取引所が経営統合した際に誕生しました。
一般にはJPXよりも東証と言った方が今でも知名度は高いような気がしますけれども、そのJPX傘下に東証などが存在していて、そこで株式の取引などをしています。

さらに2019年に東京商品取引所を子会社化しまして、JPXは金融商品の現物や先物、商品、コモディティの現物や先物など様々なプロダクトを取り扱う総合的な取引所になりました。今でも世界有数の取引所の1つだと思います。
グループ全体での社員数は約1200名。その中の約300名がいわゆるIT部門としての社員です。ただしパートナーベンダーから常駐で支援いただいてる方が約400名いるので、その方々を合わせるとおおよそ700人になります。
arrowheadを始めとする日本取引所グループのシステム概要
続いて、我々のシステムの概要をご説明できればと思います。
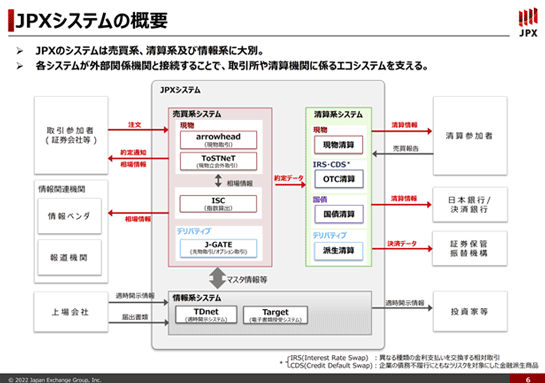
我々のシステムは大きく「売買系システム」と「清算系システム」に区分けをしています。
売買系システムはメインのシステムで、現物の株式、例えばトヨタやソフトバンクといった個別の会社の株式の取引が行われています。その中心が「arrowhead」です。
売買系システムにはもう1つ「J-GATE」という、大阪取引所で行われている先物やオプションの取引を司っているシステムがあります。
これはアメリカのNASDAQという取引所が提供しているシステムです。パッケージソフトウェアとは少し違うのですが、海外のシステムを持ってきて構築し、我々が使っているシステムです。
ちなみにarrowheadは我々とメインベンダーの富士通が一緒になってスクラッチから作っているシステムです。
arrowheadもJ-GATEも売買(ばいばい)を司っているシステムです。
この売買というのは、取引参加者という承認を受けた証券会社が我々と接続をして、売り買いの注文を出してくるというのが基本ですね。
売買を司るシステムは、その売り買いの注文をマッチングさせて、これを約定(やくじょう)と言いますが、結果をお返しするのが最も基本的な動作です。これを非常に高速かつ大容量で行うのが特徴です。
約定の結果を、我々は「清算」という用語を使っていますが、例えば株式を例にすると、株式を売ってお金と交換する、といったことを最終的にしますので、それを司るシステムが「清算系システム」です。
清算系システムは約定データを基本的にリアルタイムで受け取りますが、素のまま受け取ると通常は1日でだいたい600万件から700万件くらいでしょうか。それを証券会社ごとにまとめて差し引き処理などをしています。
中央下にあるのが「情報系システム」で、これは上場会社の適時開示という、例えば合併しますとか、決算発表とか、様々なコーポレートアクションを発表するための機能(TDnet:適時開示システム)と、それから証券会社や上場会社と連絡を取るような機能(Target:電子書類授受システム)があります。
また、皆さんがテレビやネットで見ておられるいわゆる株価等の情報は、基本的には売買系システムのデータをそのまま吐き出したものが、情報ベンダーや報道機関に流れていきます。
我々のシステムは非常に多くの、しかも様々な種類の接続先がありまして、それぞれ役割が違っていたり、授受するデータが違っているものが複雑に繋がっている、というところは、この図でなんとなく記憶していただきたいところです。
それが後で出てくるレジリエンス、つまり仮に我々が障害を起こしたときにどうやって迅速に復旧させるか、ということに非常に繋がってくるんですね。
2005年から2006年にかけてシステムトラブルが立て続けに発生
このスライドはJPXのIT部門、従来でいうと東証なのですが、今はJPXのIT部門ということで、これまでの取組みをギュッと凝縮して書いております。
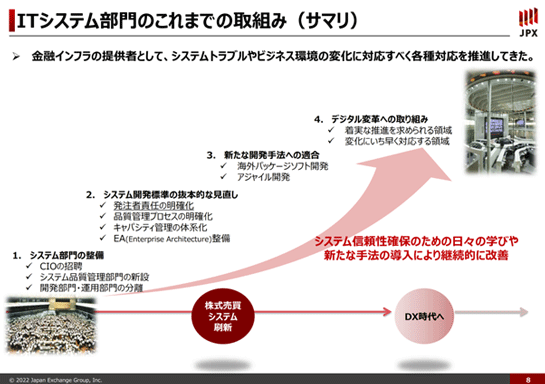
ここは格好の良いことばっかり書いているのですが、システムトラブルとビジネス環境の変化に対応すべく各種対応を推進してきた、ということになります。
実はこの前段となる極めて大きな出来事がありまして、そのことを話さないとここへ繋がってこないので、まずその話をさせていただきます。
それは2005年から2006年にかけて、当時の東証が、大きなシステムトラブルを3回起こしたことです。
2005年11月:システム障害で約半日取引停止
2005年の11月1日に株式の売買システムで障害がありました。おおよそ9時から13時半まで約半日、障害で取引が停止するという大変大きなシステムトラブルがありました。
2005年12月:ジェイコム事件
その同じ年の12月に、いわゆる「ジェイコム事件」と言われるトラブルが起こりました。当時、ある証券会社が、ジェイコムという会社が新規上場する際に、1株61万円の売り注文を出すはずが、間違えて1円で61万株の売り注文を出してしまったんです。
証券会社はその売り注文を取り消そうとしたのですが、取り消すことができなかったために、不適切な大量の約定(本来61万円の株が1円で買えてしまう)が成立したのです。取り消しができなかったのは我々のシステムのバグだったわけですけれども、極端な誤発注がトリガーとなってバグが顕在化してしまいました。
61万株のうち約14万株が約定してしまって、本来はその売り注文を取り消せれば大きな事故にはならなかったと思うのですが、取り消せなかった。
その後、この件はその証券会社と訴訟になりまして、400億円余りの損害賠償請求をされて、最高裁まで争った結果、100億円余りの賠償金を支払うことになりました。
2006年1月:ライブドアショック
その2005年12月の翌月には、「ライブドアショック」という出来事がありました。当時、ライブドアが大規模な株式分割を行っているなかで、社長だった堀江氏が逮捕されるということがありました。
そこからライブドアの株価が急落して大量の注文と約定が発生し、東証のキャパシティが耐え切れなくなり、通常は15時まで行う株式の売買を14時40分に停止した。キャパシティオーバーとなる可能性が高くなったため、あらかじめ売買を止めたのです。
このように11月、12月、1月と3回続けて東証で非常に大きなシステムトラブルが発生しました。私は当時、IT担当の企画課長のポジションを務めていたのですけれど、これは生涯忘れられない記憶になりました。
システムこそ業務の根幹であると理解できていなかった
この3つのシステムトラブルを振り返ると、まず11月に約半日売買が止まったのはプログラムのリリースミスでした。
テストはしていたのですが、プログラム資産を入れ替えるときに、A資産をリリースすべきところでB資産をリリースしてしまい、システムの不整合が起きて売買が止まってしまった、ということです。
当時は資産管理を全部ベンダーに丸投げしていて、それが根本原因である、ということに尽きると思うわけで、これがこの後の様々な対策や取組みの端緒となっています。
12月のジェイコム事件の誤発注に伴う注文取消し不能のシステムトラブルは、バグが原因です。発注の極端な取り違えがトリガーとなっているとはいえ、そうしたケースまで含めたテストが十分にできていなかった、ということが原因で、これはプログラム品質の問題だったと思います。
最後のライブドアショックの件は、完全にキャパシティ管理のミスです。当時のシステムはメインフレームベースで、キャパシティの拡張が非常に難しかったという要因はあるにせよ、やはりキャパシティ管理がしっかりできてなかった。そのことが大きな原因だった。
結局は我々が完全な装置産業、インフラ産業になっていて、システムこそ取引所業務の根幹であるというようなことが、当時の私も含めて、2005年当時の取引所の経営の中でそういったことが十分に理解できていなかった。
従って、それに対して適切な人的・金銭的なリソースを割くこと、リスク管理をすること、ができていなかったのです。
≫後編に続きます:大規模障害を受けて、東証はベンダーへの丸投げをやめ、運用チームの地位向上に取り組み、そしてSREへ挑むことになるのです。
東京証券取引所のシステム開発
あわせて読みたい
東証がSREによるレジリエンス向上に挑む理由。過去のシステム障害から何を学んだのか?(後編) ソフトウェア品質シンポジウム2022
≪前の記事
DenoがSlackの新しいプラットフォーム基盤に採用されたことを発表。SlackのBotなどはDenoベースでの開発に

