
SREによる構成変更がGmailなど広範囲な障害の引き金に。3月13日に発生した障害についてGoogleが報告
3月13日の11時53分から15時13分(いずれも日本時間)までの3時間20分のあいだ、GmailやGoogle Drive、Google Photos、Google Storage、App EngineのBlobstore APIなどGoogleの広範囲なサービスで一部の機能が利用できなくなる、あるいは遅延が発生するなどの障害が発生しました。
その原因と対策について、Googleが「Google Cloud Status Dashboardのインシデント#19002」として報告しています。
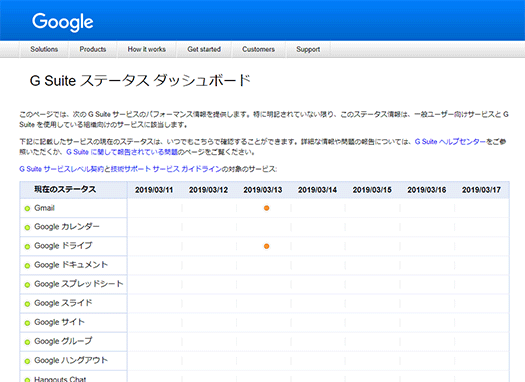 3月13日にGmailやGoogle Driveに障害が発生していることが分かる
3月13日にGmailやGoogle Driveに障害が発生していることが分かる報告では障害の原因が、ストレージ内のリソースを削減しようとしたSRE(Site Reliability Engineer)による構成変更にあったと説明。
SRE(Site Reliability EngeneeringもしくはSite Reliability Engineer)とは、高い信頼性や性能を発揮するシステムインフラを実現するため、運用においてもソフトウェア開発を積極的に行っていく方法もしくはそれを実践するエンジニアのことを指します。GoogleのシニアVPであるBen Treynor氏が提唱した、先進的な運用改善のアプローチとして注目されています。
しかしそのSREも人間が行うことですから、やはり完璧ではなかったわけです。下記はGoogleの障害報告から引用します。
ROOT CAUSE
On Monday 11 March 2019, Google SREs were alerted to a significant increase in storage resources for metadata used by the internal blob service. On Tuesday 12 March, to reduce resource usage, SREs made a configuration change which had a side effect of overloading a key part of the system for looking up the location of blob data. The increased load eventually lead to a cascading failure.
根本原因
2019年3月11日月曜日、GoogleのSREらが、社内のBlobサービスで使われているメタデータ用ストレージリソースの使用が劇的に増加している、というアラートを受け取る。12日火曜日、リソース使用量を減らすため、SREらがコンフィグレーションの変更を行ったが、これにはBlobデータの場所を参照するというシステムの重要な機能の一部を過負荷にしてしまうという副作用が含まれていた。そして負荷の増大は最終的に次々と障害を引き起こすことになった。
内部ストレージが障害を引き起こしたことで、それに関連する複数の社外向けのクラウドサービスに影響が出たわけです。最終的にこの障害は、SREがマニュアル操作で過負荷による社内Blobサービスのトラフィックを削減し、収束させることとなります。
そして次のような対策が報告されました。
In order to prevent service disruptions of this type, we will be improving the isolation between regions of the storage service so that failures are less likely to have global impact.
こうしたタイプのサービス障害を避けるため、私たちはストレージサービスのリージョン間の分離を高め、これによってグローバル全体に障害の影響が及ばないようにする。
We will be improving our ability to more quickly provision resources in order to recover from a cascading failure triggered by high load.
また、高負荷による障害の波及が次々に広がらずに普及できるようにするため、より迅速なリソースのプロビジョニングができるように改善する。
We will make software measures to prevent any configuration changes that cause overloading of key parts of the system. We will improve load shedding behavior of the metadata storage system so that it degrades gracefully under overload.
さらに、システムの重要部に対する過負荷が構成変更によって起こらないように、ソフトウェアによる計測を実現する。メタデータストレージシステムの負荷低減動作を改善し、過負荷時でも適切に負荷が低下するようにする。
SREが原因となった障害の対策にも、あるいはSREが原因の対策だからこそ、さらにしっかりとSREで対応していくことが報告から見えてくるようです。
あわせて読みたい
Linuxの業務システムから「このExcelシートと同じレイアウトで帳票を印刷してください」に対応できるJavaライブラリが登場[PR]
≪前の記事
Node.js Foundationと、ESLintやAppiumなどをホストするJS Foundationが合併し「OpenJS Foundation」が発足

