
クラウドストレージを活用する革新的テクノロジーとしての「重複排除」。ベンダによって異なる圧縮率の裏側にある技術[PR]
クラウドを活用する用途のひとつに、バックアップデータやアクセス頻度の落ちた過去のデータをクラウドへ転送し、長期保存のためにクラウドストレージを使う、というものがあります。
クラウド側もこうした利用用途を意識して、通常のストレージよりもアクセス速度は遅いものの価格の安いアーカイブ向けストレージサービスを提供しているクラウドプロバイダが増えてきました。こうしたクラウドストレージをうまく使うことで、高いコスト削減効果を得ることができます。
このとき、コスト削減効果を高める鍵となるのが、クラウドストレージの費用をできるだけ低くする、という点です。
クラウドストレージの費用は、一般に保存するデータの大きさ、そして保存するデータの送信や受信時にかかるトラフィックに比例した従量課金となっています。
ということは当然のことながら、クラウドにかかる費用を小さくするには保存すべきデータをいかに小さくするかにかかっていることになります。データを小さくするほど、クラウドにかかる費用が小さくなり、しかも長期保存を想定するアーカイブデータであれば、年ごとにその効果は何倍にもなって現れます。
また、転送に掛かる時間も無視できないでしょう。例えばアーカイブデータを送信するとき、あるいは取得が必要になって受信するとき、データが小さいほどその時間が短くて済みます。
そこで注目されるのが、アーカイブデータ向けのデータの圧縮技術です。
ストレージ市場を大きく変えた重複排除の登場
 Dell EMC Data Domain重複排除ストレージシステム。アプライアンスだけでなく、仮想マシン版もある
Dell EMC Data Domain重複排除ストレージシステム。アプライアンスだけでなく、仮想マシン版もあるデータの圧縮技術にはさまざまな種類が存在します。例えばWindowsの標準技術にも使われているZip方式などはもっとも普及している圧縮技術のひとつですが、主に企業におけるバックアップやアーカイブをターゲットとする圧縮技術としてもっとも優れた方式のひとつとされているのが「重複排除」です。
2005年、米国でこの重複排除に関連した特許「US 6928526 B1」をData Domain社が取得(Data Domain社はその後、2009年にEMCが買収)。同社の重複排除技術を基に登場した製品は非常に高いデータの圧縮率を実現しました。それまで安価とされていたテープ媒体に対抗できるほど、ハードディスクドライブへ高効率で大容量のデータ保存を可能にしたのです。
TechCrunchの記事「企業のストレージを変えた四大特許」では、その筆頭に重複排除の技術が挙げられています。それほど、重複排除の技術は革新的でした。
重複排除の基本的な仕組みとは
一般に重複排除を用いると、バックアップやアーカイブデータはオリジナルデータに対しておおよそ10分の1から30分の1、データによってはそれ以上に圧縮できるとされています。
重複排除がデータを圧縮する基本的な仕組みはその言葉から想像されるとおり、データの中から重複しているパターンを探しだし、その部分を省略することで実現されています。
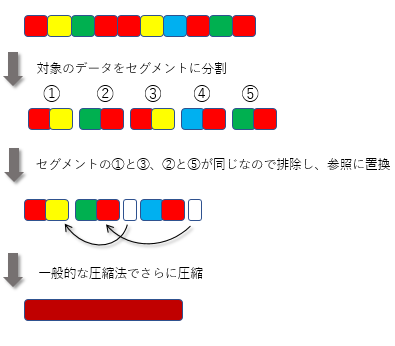
企業で生成されるデータには、例えば同じテンプレートから生成されているパワーポイントファイル群や、わずかにバージョンが異なる多数のドキュメント、全社員ほぼ同じ構成の仮想デスクトップ用イメージファイルなど、重複部分を大量に含むものが数多く存在します。
重複排除はこのようなデータから非常に効果的に重複部分を取り除き、高い圧縮率を実現するのです。
重複排除の圧縮率をより高める「可変長セグメント」
ただしすべての重複排除が同じわけではありません。例えばData Domainでは、独自の「可変長セグメント」と「インライン処理」によって、より高い圧縮率の重複排除を、プロセッサとメモリを活用することで高速に実現しています。
可変長セグメントとは、重複したデータを探索する際にセグメントの大きさを固定しないことで、より効果的に重複データを発見する技術です。
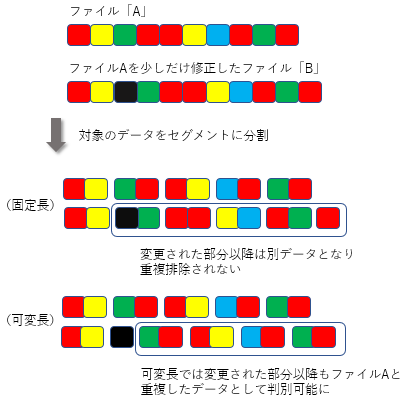
例えば、あるファイル「A」があり、そのファイルAの一部を追加変更して新たにファイル「B」を作ったとしましょう。
固定長セグメントでは、変更部分以降は全部異なったデータだと認識される可能性が高いので十分な重複排除は働きません。しかし可変長セグメントであれば、変更部分を除いた部分はファイル「A」とファイル「B」は同一なので、非常に効果的に重複排除が働きます。
こうした重複排除のテクノロジーにおける効率の差は、実際の運用では非常に大きな差として現れることがあります。
例えば可変長セグメントを用いたData Domainの圧縮効果が99.7%、一般的な重複排除で用いられている固定長セグメントでの圧縮効果が97%だとしたとき、両者の差はわずか3%程度に見えます。
しかし実際には、オリジナルデータの大きさが圧縮後に0.3%になるのと、圧縮後に3%になるという違いになり、圧縮後のデータサイズの比は10倍になるのです。

すると、このデータをクラウドに転送した場合、転送トラフィックにかかるコストも、保管に掛かるコストも10倍違うことになります。
高い圧縮効果がいかにクラウド活用時のコストに効いてくるのか分かるでしょう。
さらにData Domainはこの重複したセグメントの探索処理を、メモリとストレージを効率的に利用することで高速に行う「Stream Informed Segment Layout」(SISL)と呼ばれるアーキテクチャを用いることで、重複排除後のデータのみをバックアップメディアに高速に書き込む「インライン処理」を実現しています。
これにより実質的に非常に高いスループット性能を実現しています。
Data Domain Cloud Tier
ここまで説明したような効率的な重複排除と高速な処理を活用しつつ、データの保管にクラウドを活用する機能を提供するのが、Data Domainからクラウドへ重複排除後のデータを自動送信する「Data Domain Cloud Tier」です。
対応クラウドはAmazon Web Services、Microsoft Azure、Virtustream。そしてEMCのオブジェクトストレージであるElastic Cloud Storageにも対応。

Data Domain Cloud Tierを利用することで、単純にクラウドへバックアップデータを送信するのと比較すると、重複排除後の小さなデータサイズによる圧倒的な低コストでクラウドストレージを活用できます。
Data Domainにはアプライアンスとしての製品としてハイエンドからミドルレンジ、スモールレンジ向けの製品だけでなく、仮想化ハイパーバイザ上で実行可能なバーチャルエディションも用意されています。導入規模に応じて、柔軟な構成でクラウドを活用するバックアップ、アーカイブシステムがData Domainで構築できるでしょう。
あわせて読みたい
動画の内容を自動判別してくれる「Google Cloud Video Intelligence API」ベータ公開で誰でも利用可能に。アダルトコンテンツの検出機能が新たに追加
≪前の記事
「Open Source Friday」をGitHubが提唱。金曜日は自分の好きなオープンソースに貢献しよう

