
SAP、Apache Spark上の新クエリエンジン「SAP HANA Vora」発表。大量のIoTデータもOLAPのようにドリルダウン可能
2015年9月3日
欧SAPは、Apache Spark上で稼働するクエリエンジン「SAP HANA Vora」を発表しました。
SAP HANA Voraは、大量のデータをメモリ上で処理できるオープンソースのフレームワークである「Apache Spark」上で稼働するクエリエンジン。Hadoopのファイルシステムである「HDFS」からデータを読み取り、さまざまな分析を高速に実現します。
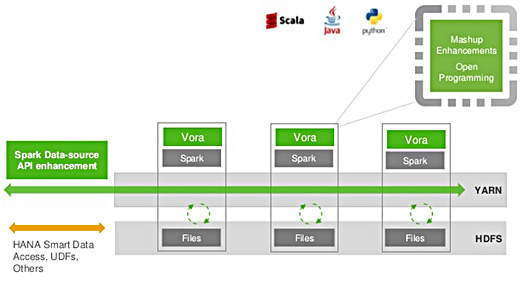 「SAP HANA Vora: An Overview」から一部を抜粋
「SAP HANA Vora: An Overview」から一部を抜粋これまでリレーショナルデータベースに保存された売り上げや顧客などのビジネスデータは、いわゆるOLAP(Online Analytical Processing)と呼ばれる仕組みを用いて対話的にクエリを行い、データの一部へとドリルダウンすることで売り上げの上位顧客に関する嗜好分析や、特定の時期における売り上げの変動などより詳細な分析を行うことが可能でした。
HANA Voraはセンサーデータなどに代表されるいわゆるIoTの分野で生成される大量のデータに対しても、従来のOLAPのようにリアルタイムに詳細な分析を行ったり、ビジネスデータと組み合わせた分析などを可能にするものです。
SAPはHANA Voraを同社のインメモリ処理基盤であるSAP HANA Platformの一部とし、フトウェアとして提供するのに加えて、同社のクラウドサービスであるSAP HANA Cloud PlatformでSaaS(Software as a Services)としても提供するとしています。
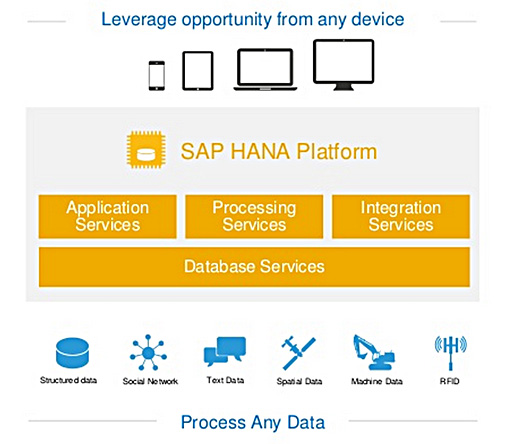 「SAP HANA Vora: An Overview」から一部を抜粋
「SAP HANA Vora: An Overview」から一部を抜粋これによりSAPはIoTを含むあらゆるビジネスデータをインメモリで迅速かつ高度に処理できる基盤としてのSAP HANA Platformを強化していく戦略を、さらに一歩前進させたことになります。
あわせて読みたい
≫次の記事
さくらインターネット、Windowsテクノロジーで構築された「さくらプライベートクラウド powered by Windows Azure Pack」の提供を開始
≪前の記事
マイクロソフト、OfficeのUIフレームワークを「Office UI Fabric」としてオープンソースで公開
さくらインターネット、Windowsテクノロジーで構築された「さくらプライベートクラウド powered by Windows Azure Pack」の提供を開始
≪前の記事
マイクロソフト、OfficeのUIフレームワークを「Office UI Fabric」としてオープンソースで公開

