
Pinterestはいかにスケーラビリティと格闘してきたのか(後編)。QCon Tokyo 2013
4月23日に都内で開催されたエンジニア向けのイベント「QCon Tokyo 2013」。急速に人気サイトへと成長したPinterestが、その裏でいかにスケーラビリティと格闘してきたのかをPinterestのエンジニア自身が紹介するセッション「Scaling Pinterest」が行われました。
この記事は「Pinterestはいかにスケーラビリティと格闘してきたのか(前編)。QCon Tokyo 2013」の続きです。
クラスタリングは怖い
スケーラブルなシステムで問題なのは、データベースがひとつのサーバに収まらなくなったときにどうするのか、ということだ。
例えば、Cassandraは自動的にスケーリングしてくれて設定も簡単。可用性も高く単一障害点はない。しかし障害はそれでも起こるもので、クラスタリングの技術はまだ枯れておらず基本的に複雑なものだ。コミュニティもまだ十分ではない。
私たちはCassandraで4回ほど、カタストロフィ(破滅的)な現象に遭遇したことがある。データのリバランシングに失敗したことや、すべてのノードでデータが壊れてしまったこともある。10のノードがあるのになぜか負荷が1つに集中していたので、マニュアルで直したつもりが自動リバランス機能が元に戻してしまったりする。

そんなわけで、私たちが学んだこと「Lesson Learnd #2」は、クラスタリングは怖い、ということ。技術として枯れていないので、変な壊れ方をする。

シャーディングを採用
そこでシャーディング。シャーディングの方法はいろいろあるが、アルゴリズムは非常にシンプル。

どの時点でシャーディングを開始するべきか。シャーディングを始めるには、新しいサービス開発を止めて数カ月はシャーディングに取りかからなければならないし、遅くなるほどシャーディングは難しくなる。
まずできるだけ複雑なジョインを取り除き、キャッシュなど追加する。それでもまだ足りなければシャーディングに取り組む。

私たちはまず、1台のDBに外部キーとジョインを用い、次に非正規化とキャッシュ。さらにリードのスレーブを追加。この段階でシャーディングを考え始めた。
そのあといくつかの機能をシャードしたデータベースとリードスレーブなどを使い始めた。私たちがシャーディングを始めるのは遅すぎたといまは反省している。

そのあとでアーキテクチャを再考し、IDによるシャーディングを行った。シャーディングを行うとジョインなどがなくなるため、スキーマを計画的に変更しなければならない。
64ビットのIDでシャードを指定
われわれがどうシャードしたか、具体的な方法だが、これはFacebookやFriendfeedなどのやり方を研究し、そこからわれわれに合ったものを採用した。
まず8つのサーバそれぞれに512個のデータベースがあり、それぞれにユニークな名前(db00001、db00002、db00003~db04096)がついている。名前からどのデータベースがどの物理サーバにあるかが分かる。また物理サーバにはそれぞれスレーブサーバが用意されており、レプリケーションされている。
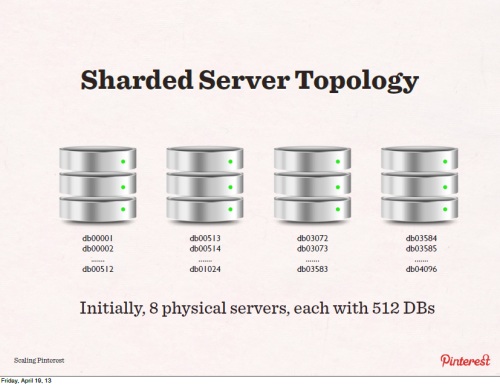
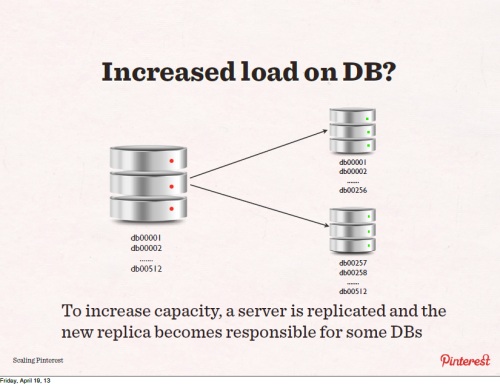
仮にキャパシティがもっと必要になればデータベースを分けて新しいサーバにレプリカを作り、再コンフィグレーションする。例えば512のデータベースを256までと512までに分けて、それに合わせてコードを直す。こういう分割は容易にできる。
データのIDは64ビットで、Shard IDがどのシャードにデータがあるのかを示しており、Typeはどのタイプのデータなのか、そしてLocal IDでそのテーブル内の位置を示している。アプリケーションはどのシャードがどのサーバに入っているか知っているため、これらによって中間のサーバなどに頼ることなく直接そのデータに到達できる。
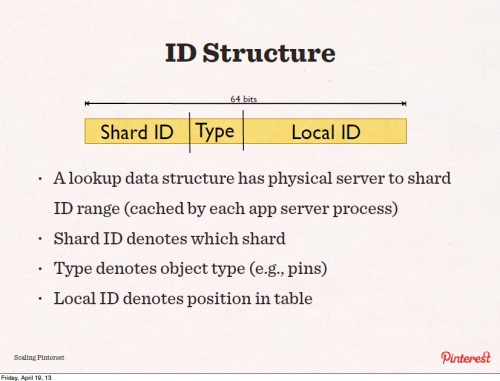
新規のユーザーは0から4096までのランダムなシャードに割り当てられる。ボードやピンなどのタイプはユーザーと合わせて付けられる。Local IDはインクリメンタルに付く。

オブジェクトテーブルにはユーザーのボードやピンなどの情報が入っている。
マッピングテーブルには、ユーザーがボードを持ってるとか、ピンがイイネされているとかをマップする。明示的にオブジェクトが何かのオブジェクトとつながるといった単純な構造。すべてのルックアップがシャードに載るとデータの移動がないので、システムはシンプルになる。
検索時に99.9%はキャッシュにヒットする。

それと、われわれが過小評価していたのは古いシステムから新しいシステムへの移行。これに4カ月かかった。5億のピン、16億のフォローデータ移行のためにスクリプティングファームを作った。コード書きに1カ月、データの移行に3カ月かかった。
5年から10年はこのシステムで
将来について。MySQLはいろいろと使われているが、まだクラスタリングの準備は出来ていないと思うので、5年から10年はこのシステムで行くと思う。自動化シャーディングは使えるテクノロジとなっていくだろう。

ここでわれわれが学んだこと「Lesson Learned #3」。チームが200人など大きくなるとコミュニケーションが難しくなり、楽しくなくなってくるので、カルチャーとして楽しい雰囲気にするのは大事だと思う。

当日のスライドへのリンク。
QCon Tokyo 2013
- JavaScriptのプログラミングスタイルはどうあるべきか? 重鎮Douglas Crockford氏が脳の働きとの関係を語る(前編)。QCon Tokyo 2013
- JavaScriptのプログラミングスタイルはどうあるべきか? 重鎮Douglas Crockford氏が脳の働きとの関係を語る(後編)。QCon Tokyo 2013
- Pinterestはいかにスケーラビリティと格闘してきたのか(前編)。QCon Tokyo 2013
- Pinterestはいかにスケーラビリティと格闘してきたのか(後編)。QCon Tokyo 2013
- OpenStackの構造と内部動作、自分でクラウドを構築する意味とは。QCon Tokyo 2013
あわせて読みたい
次期Java 8は来年2月、Java EE 7は今年6月にリリース予定。Java Day Tokyo 2013
≪前の記事
Pinterestはいかにスケーラビリティと格闘してきたのか(前編)。QCon Tokyo 2013

