
「本番環境などという場所はない」マイクロソフトがSaaSの失敗と成功から学んだ、アジャイルからDevOpsへの進化(前編)。Regional SCRUM GATHERING Tokyo 2016
アジャイル開発手法の1つであるスクラムをテーマにしたイベント「Regional SCRUM GATHERING Tokyo 2016」が1月19日と20日の2日間、都内で開催されました。
そこでマイクロソフトが行ったセッション「マイクロソフトが実践したScrum導入7年間の旅。そしてDevOpsへの進化」は、アジャイル開発からクラウドサービスの提供へと進んだマイクロソフトが、サービス開発の過程で学んださまざまな知見を共有するものとなりました。
そこには、アジャイル開発の延長線上にあるDevOpsを成功させる組織と技術、そしてマインドのあり方が紹介されていました。セッションの内容をダイジェストで紹介します。
マイクロソフトが実践したScrum導入7年間の旅。そしてDevOpsへの進化
マイクロソフト コーポレーション シニアテクニカルエバンジェリスト DevOps ITPro 牛尾剛氏。

マイクロソフトのDevOpsエバンジェリストの牛尾と申します。
今日は「マイクロソフトが実践したScrum導入7年間の旅。そしてDevOpsへの進化」という話をしようと思います。
この話は実はマイクロソフトのSam Gukenheimerが行ったAgile Conference 2014(2014年7月に米オーランドで開催)のキーノートなんですね。
でもいまは2016年ですので、彼に話を聞いて、今日はその内容を完全日本語化しました。

マイクロソフトは苦労して時間をかけて、ウォーターフォールからアジャイル開発の世界、そしてDevOpsの世界へと社内の開発を移行させてきました。
まずいちばん最初にDevOpsについて話をしますと、DevOpsとはビジネス、Dev、Opsが協力し、ソフトウェアライフサイクルを改善し、ビジネス価値の創出を改善する活動です。つまり改善活動なんです。
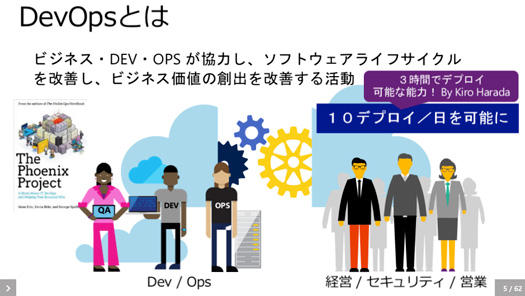
アジャイル開発は開発が中心のイメージですが、DevOpsはオペレーションも含んでいて、アジャイル開発の考え方を拡張したものだと思っていただければいいと思います。
米国では銀行や生保といった堅いと思われている企業でも、DevOpsで一日に10回以上アプリケーションをデプロイしているところがあります。これはテクノロジーだけでは絶対無理で、マインドセットやビジネスルールを変えていかなければいけない。そういうことをしないと達成できないですね。
で、そのDevOpsの効果ですが、これはPuppet Labsが公開している資料ですが、コードのデプロイが30倍スピードアップし、パフォーマンスの低い環境に比べてリードタイムが200分の1に短縮できると。ほんまかいなと思います。
またエラーを60分の1に削減できるとか、エラーからの復元を168倍高速にできるとか。
こうしたことによって企業の収益性や生産性が高まっていると。

普通、アジャイル開発をやっていてもプロダクトをリリースするのは3カ月ごととかじゃないですか。それが1日に10回もできるなんて、DevOpsはすごいじゃないですかと。
サービス初日にいきなり7時間もサービスをダウンさせたマイクロソフト
ここからは、「Visual Studio Team Services」というサービスをいまマイクロソフトはDevOpsで開発しているのですが、そこで学んだことをみなさんと共有したいと思います。
プロジェクト管理のための製品で、プロジェクトを作って、Gitなどでバージョン管理やコードのビルドができて、リリースマネジメントもできてという製品です。
このサービスは元々「Team Foundation Services」という製品で、オンプレミスにインストールするパッケージソフトウェアでした。
それをクラウド版として展開を始めたとき、リリースの初日に7時間もサービスがダウンしました。
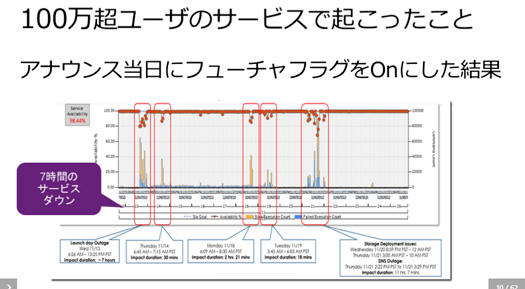
しかもネットワークのログもちゃんととってなかったので原因究明もうまくいかなかったりと。
こういうことがきっかけで、マイクロソフトもそろそろDevOpsに取り組まなければならないのかな、となったわけです。
で、2010年から時間をかけて、いろんなひどいめに遇いながらも「SaaSプロバイダとしての学び」を得てきました。
これがそれらです。これをこのあと説明していきたいと思います。
組織の変遷
マイクロソフトの体制は、最初はウォーターフォールでした。で、Scrum Agileをやりました。やったときにはこういう体制でした。
QAがいてDevがいてOpsがいて、Program Mangementがありました。
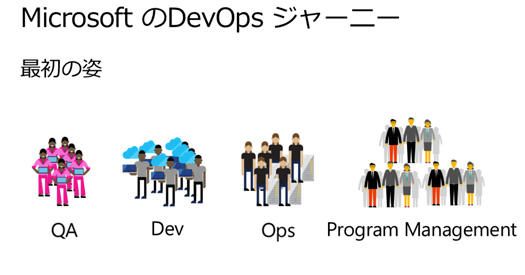
ただ、スプリントの後半だけしかQAが忙しくないとか、そういった事情もあり、まずDevとQAを一緒にして、Engineeringチームにしました。
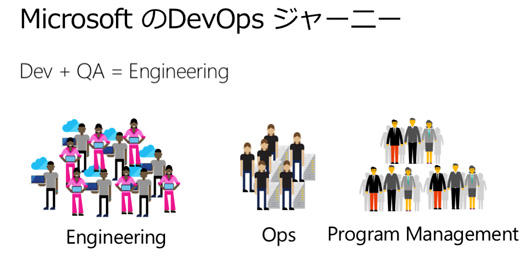
でも、今度はEngineeringからOpsに渡してデプロイしてもらうのにも時間がかかるよねと。
そこでEngineeringチームにOpsとProgram Mangementも一緒にして、Featureチームにしました。QAもDevもOpsもみんないて、1つのチームとして働いてもらう。
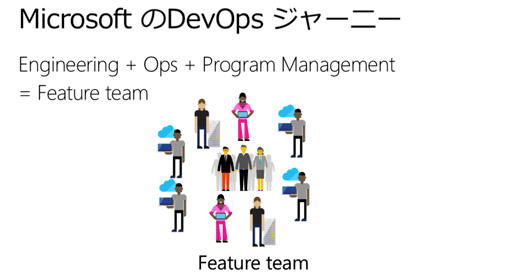
さらにこのチームに権限も与えて、お客さんとも直接お話をして製品開発をがんばってねと。
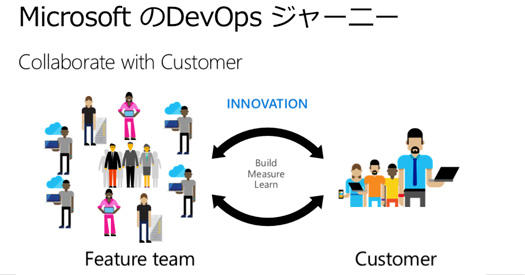
チームの自己組織化とエンタープライズとしての提携
SaaSプロバイダとしての学びの1つ目は「チームの自己組織化とエンタープライズとしての提携」です。

まずTeam Room。開発に携わっているひとは100人以上いて、国も5カ国ぐらいにまたがっているディストリビューテッド(分散した)チームです。でもTeam Roomはオープンスペースで、すぐ話しかけられるようになっています。

マイクロソフトは大きな組織ですが、実は小さなチームの集合体だと思ってください。
3週間スプリントでリリースしています。
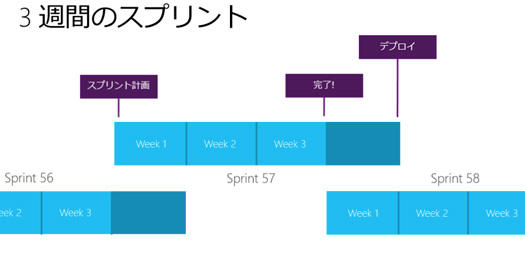
僕はマイクロソフトに昨年の8月に入ったばかりなのですが、マイクロソフトはけっこうメール文化の会社でした。理由が最近なんとなくわかってきたのですが、Outlookで連係させるとめっちゃ便利なんです。スケジューラと連係したり、Skypeと連係させてクリックだけでSkypeで会議ができたり。
左側はスプリントが始まったときのスプリントメール。右側はスプリントデモの日のメールで、デモの動画が見られます。
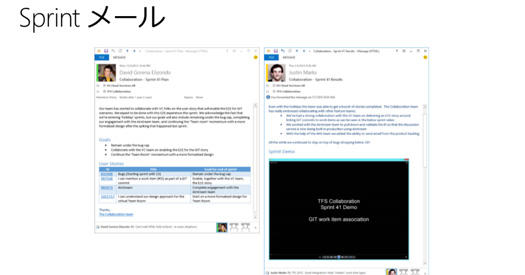
こういったやり方で、分散したチームでも連係してうまくやっていけると。
技術的負債をマネジメントする
次は「技術的負債をマネジメントする」。

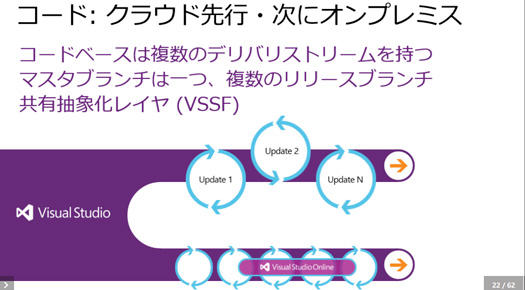
実は「Visual Studio Team Services」には2つのバージョン、クラウド版とオンプレミス版があります。
2つのコードベースは同じ1つのコードで、それぞれリリースブランチを複数持っているということになります。
またリリースのタイミングは異なっていて、クラウドバージョンは3週間に一回。オンプレミスの方は3カ月に1回です。
原則として、テストは可能な限り低レベルで書く。Azureの開発に関わっている日本人に、Azureでシステムテストや受け入れテスト、負荷テストは自動化しているのか聞いたところ、もちろんぜんぶ自動化していると、じゃないとリリースに間に合わないと言っていました。
それから“Write Once, Run Anywhereという、Javaで聞いたような原則があります。
テストは手元のマシンでも、QAでも、本番環境でもどこでも動くように書きましょうと。
それからプロダクトはテストが容易な設計にする。そうしないとテストの自動化ができないので、グローバルにリリースするプロダクトとして致命的になると。
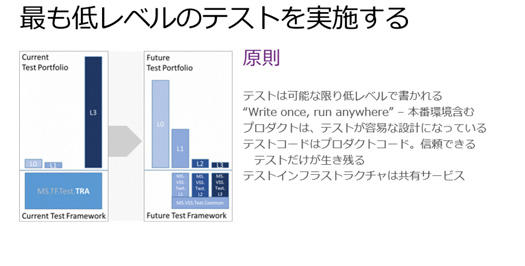
テストコードはオマケみたいに見られがちですが、テストもプロダクトコードとして考える。リファクタリングもしていらないコードは捨て、信頼できるコードだけを残す。
ひどい目にあっているユーザーを追跡する
次は「顧客価値のフロー」ですね。

サービスにはSLA(サービスレベル契約)があって、可用性が何パーセントなどと決まっていて、そこを下回らないようにすると。
で、マイクロソフトもいちばん最初はOutside-inのテストとして、外からPingを打ってサービスをチェックしていました。でもこの方法はサービスが増えるとよく分からなくなります。
次にやったのはコマンドのヘルス。コマンドとは機能のことで、ビルドとかワークアイテムの作成とか、そういうコマンドを実行してログをとっていた。しかしこれも機能が増えるとログに埋もれてわかりにくくなった。
そこで最終的に到達したのは、アカウントごとの失敗、つまりユーザーがビルドに失敗しているとか、時間がかかりすぎているとか、そういうことを計測するようにした。
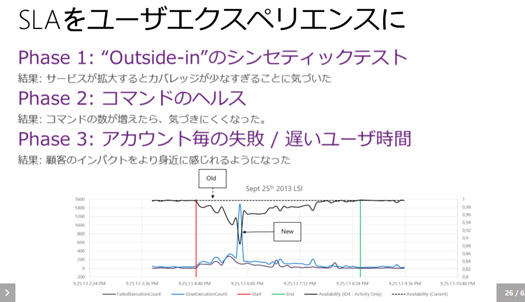
すると顧客のインパクトをより身近に感じることができるようになった。
こういう段階を踏んで改善していきました。
さらに、例えば99.9%の可用性を達成しても、一方で0.1%に当たってひどい目にあっているユーザーがいて、その人に着目する。
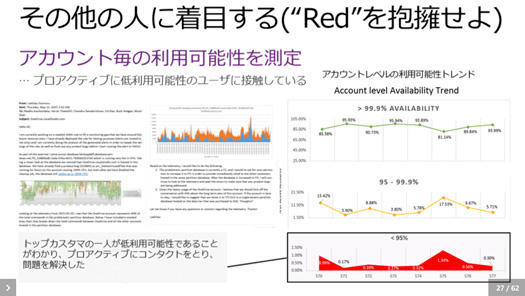
ひどい目にあっているユーザーさんを追跡して、コンタクトしてディスカッションして問題を解決する。「Redを抱擁せよ」と言います。
こういうことは、アジャイル開発だけのときにはやっていなかったことですね。
≫後編に続きます。後編では、本番環境そのものを用いてフィードバックを受け、障害原因の分析などを行う例を紹介します
Regional SCRUM GATHERING Tokyo 2016
- 「本番環境などという場所はない」マイクロソフトがSaaSの失敗と成功から学んだ、アジャイルからDevOpsへの進化(前編)。Regional SCRUM GATHERING Tokyo 2016
- 「本番環境などという場所はない」マイクロソフトがSaaSの失敗と成功から学んだ、アジャイルからDevOpsへの進化(後編)。Regional SCRUM GATHERING Tokyo 2016
- 厳格なウォーターフォールの金融系IT企業が、スクラムを採用した初のアジャイル開発プロジェクトの経緯と成果を語る(前編)。Regional SCRUM GATHERING Tokyo 2016
- 厳格なウォーターフォールの金融系IT企業が、スクラムを採用した初のアジャイル開発プロジェクトの経緯と成果を語る(後編)。Regional SCRUM GATHERING Tokyo 2016
あわせて読みたい
「本番環境などという場所はない」マイクロソフトがSaaSの失敗と成功から学んだ、アジャイルからDevOpsへの進化(後編)。Regional SCRUM GATHERING Tokyo 2016
≪前の記事
社内で勝手に使われているクラウドサービスを検出し、シャドーITを撲滅するサービス「Cisco Cloud Consumption as a Service」、シスコが発表

