
グーグルが構築した大規模システムの現実、そしてデザインパターン(2)~BigTable編
グーグルが「Evolution and Future Directions of Large-Scale Storage and Computation Systems at Google」(グーグルにおける、大規模ストレージとコンピュテーションの進化と将来の方向性)という講演を、6月に行われたACM(米国計算機学会)主催のクラウドコンピューティングのシンポジウム「ACM Symposium on Cloud Computing 2010」で行っています。
講演の内容を4つの記事(MapReduce編、BigTable編、教訓編、デザインパターン編)で紹介しています。この記事はMapReduce編の続き、BigTable編です。
分散処理に対応するBigTable
次はBigTableの説明に移ろう。BigTableは、大規模分散の半構造化データストアシステムだ。
グーグルでは多くの構造的なデータを保存している。ページランクの計算のためのURLやWebのデータ、ユーザーごとのデータ、位置情報等々。しかもこれが大規模に存在している。これを数千台のマシンで分散処理でき、故障にも対応できるようなストレージが必要だった。

BigTableの基本的なデータモデルは、ロー、カラム、それにタイムスタンプによるバージョニング。
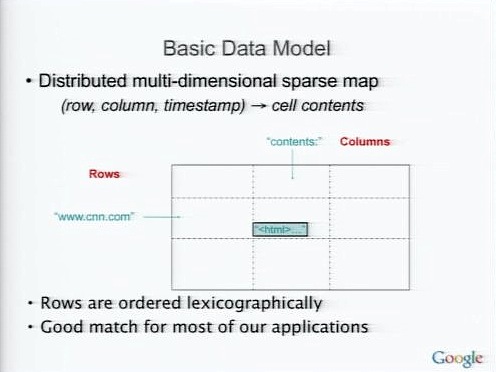
BigTableを分散処理に対応させるメカニズムが、Tabletと、TabletのSplittingだ。Tabletには多くのローが保存されており、Tabletにデータを格納していくとTabletが大きくなっていく。そしてある程度大きくなったらTabletを分割し、分散させていく。
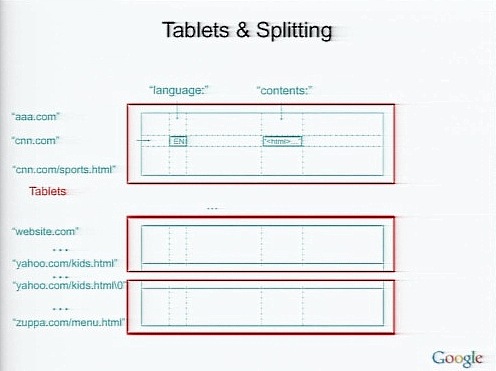
BigTableはグーグルの主要なデータストアであり、多くの実際のサービスで使われている。

BigTableに付随する実行コード
さて、BigTableについての新しい情報も紹介しよう。
以前は、グーグル内のそれぞれのグループが独自にBigTableを利用し、それぞれがBigTableを管理していた。現在ではBigTable専用チームで管理するようにしている。
また、性能分離を向上させている。グーグルマップ、ブックスキャニングチームなどが大量のMapReduceをはじめても影響がないようになった。耐障害性も向上させている。

レプリケーションも進歩しており、データは3つの異なるデータセンターにレプリケーションされるようになった。レプリケーション間での一貫性はEventual Consistency(結果整合性)を採用している。
ユーザー向けのほとんどのデータはレプリケーションされるようになっている。

BigTable Coprocessorsと呼ぶ、Tabletごとに付随するコードを実行できるようにした。このコードはTabletの分割などにも追随していく。RPCによる操作とは異なり、「これこれの行をとりだしたい」という抽象化した要求をTabletに対して投げ、複数のサーバで並列に実行できる。

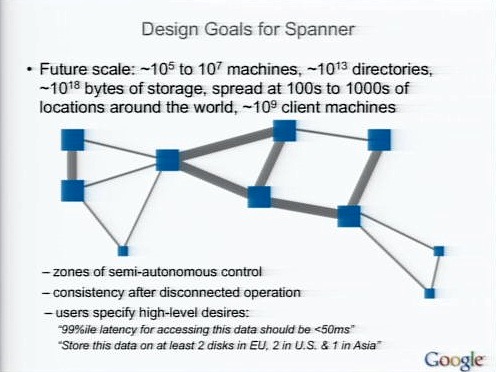
マルチデータセンターの上に作られるSpanner
現在取り組んでいるのが「Spanner」だ。グーグルがこれまで(Spanner以前に)作ってきたのは、個別のデータセンター用のものだった。サービスデベロッパはそれらを組み合わせてクラスタレベルでのアプリケーションを作ってきた。
Spannerでは、マルチデータセンターの上にストレージやコンピューテーションを作ろうとしている。さらに、プログラマは強いコンシステンシも容易に使えるようになる。

Spannerのゴールは、10万台から1000万台程度のサーバで構成され、1つのネームスペースを持つものだ。内部はゾーンという単位で管理しようとしている。
次回は、グーグルが大規模システム構築で学んだこと。教訓編です。

