
グーグルが構築した大規模システムの現実、そしてデザインパターン(1)~MapReduce編
グーグルが「Evolution and Future Directions of Large-Scale Storage and Computation Systems at Google」(グーグルにおける、大規模ストレージとコンピュテーションの進化と将来の方向性)という講演を、6月に行われたACM(米国計算機学会)主催のクラウドコンピューティングのシンポジウム「ACM Symposium on Cloud Computing 2010」で行っています。
グーグルはどのようにして大規模分散システムを構築してきたのか、そして、そこからどのようなことを学んだのかが語られていますし、後半では大規模分散システムのデザインパターンという、非常に興味深いノウハウも公開している、非常に情報量の多い講演です。
その講演の内容を、全部で4つの記事、MapReduce編、BigTable編、教訓編、デザインパターン編に分けて、紹介したいと思います。
講演を行ったのはグーグルのJeffrey Dean氏。1999年にグーグルに入社し、現在はSystems Infrastructure Groupのフェローです。
信頼性はソフトウェアによって実現される
グーグルのコンピュータ環境のシステムやソフトウェアとその革新について紹介しよう。また、大規模分散システムのための技術についても説明していく。

これがオレゴン州ダレスにあるグーグルのデータセンター。ここで多くのサーバが稼働している。

サーバにはコモディティハードウェアが使われ、ハードディスクかFlashドライブを内蔵している。これを、各サーバへのスイッチを備えたラックに収納する。ラックそれぞれはセントラルネットワークへのアップリンクを持つ。
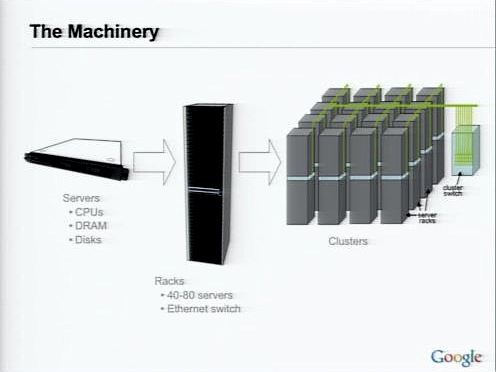
しかし、これらのリアルなマシンは、リアルな問題を引き起こす。それは、ファイバーケーブルが切断されるといったデータセンター間ネットワークの問題から、ラックやルータの故障、各サーバの故障まで、さまざまなレベルで起きる。
そこで、重要なポイントは「信頼性はソフトウェアによって実現される」ということだ。

グーグルのクラスタで実行されている処理とは?
グーグルのクラスタソフトウェアについてみていこう。
クラスタは数千台のマシンで構成されている。サーバOSはLinuxで、そのうえに分散ファイルシステム(Google File Systemもしくは次世代のGFSであるColossus)のためのチャンクサーバ、ジョブのためのスケジューリングスレーブが稼働している。これらは、スケジューリングマスターとGFSマスターによってコントロールされている。
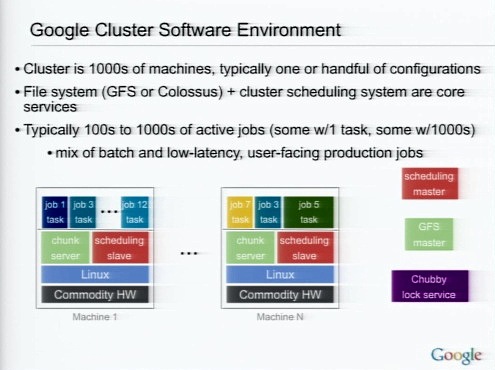
GFSとジョブスケジューリングのほかに、グーグルで一般的に使われているのは、分散処理のMapReduceや分散データストアのBigtableなどだ。

大規模分散処理の一翼を担うMapReduce
MapReduceについて紹介しよう。MapReduceはプログラミングモデルの一種で、大規模並行処理をプログラマがシンプルに記述できる。どのマシンがどの処理を実行するか、といった細かいことをライブラリが隠蔽してくれる。

MapReduceは、Mapで必要な情報を取り出し、シャッフルとソートをしてReduceに渡し、ここで統合、要約、フィルタリング、変換といた処理を行うものだ。
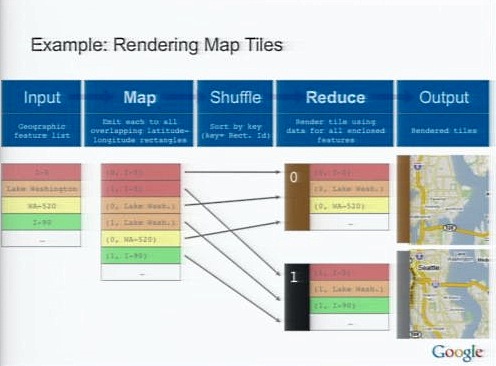
Google Mapをどうやってレンダリングしているか、というサンプルでMapReduceの処理を紹介しよう。
いちばん左のInputで、世界の道路区分のグラフ情報を入力する。その右のMapステージで、そのデータをタイル(四角形)に分解し、道路の情報がどのタイルに合致するかを見つけていく。例えばシアトルのどの場所のタイルか、といったことだ。
Reduceでは、レンダリングのために必要な情報がタイルごとに集まっているので、ここでjpgなどのイメージにレンダリングする。
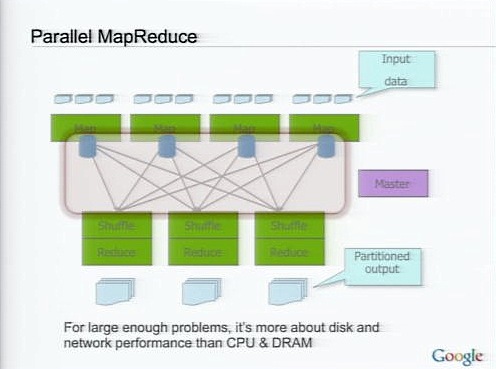
そしてMapReduceでは、Mapタスク、Reduceタスクがすべて並列に実行できる。ただし、もしも処理が非常に大量な場合、この部分のネットワークとディスクの部分がボトルネックとなる。
グーグル内部でMapReduceをどれくらい使っているか、という統計。おおざっぱにってエクサバイト級のデータを処理している。
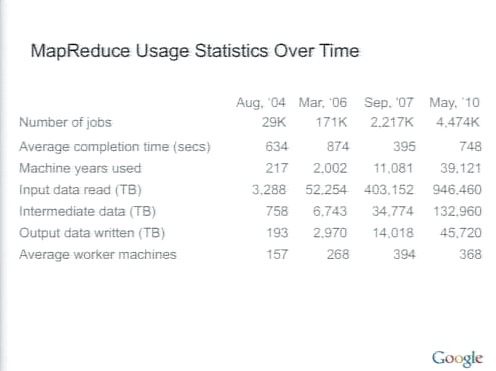
MapReduceはたんにシーケンシャルファイルを読んでいるのではなく、B-treeなど構造的なデータをデータソースとして読んでいる。

次回は現在グーグルが利用しているデータストアのBigTableと、さらに大規模なマルチデータセンター対応を目指して構築中のデータストアであるSpannerなどについて。
次回「グーグルが構築した大規模システムの現実、そしてデザインパターン(2)~BigTable編」に続く。
- グーグルが構築した大規模システムの現実、そしてデザインパターン(1)~MapReduce編
- グーグルが構築した大規模システムの現実、そしてデザインパターン(2)~BigTable編
- グーグルが構築した大規模システムの現実、そしてデザインパターン(3)~教訓編
- グーグルが構築した大規模システムの現実、そしてデザインパターン(4)~デザインパターン編
本記事で紹介している、2010年6月に行われたACM(米国計算機学会)主催のクラウドコンピューティングのシンポジウム「ACM Symposium on Cloud Computing 2010」の基調講演では、グーグルのほかにセールスフォース・ドットコムとFacebookが登場しています。
セールスフォース・ドットコムの講演内容は、以下の3本の記事で詳しく紹介しましたので、ぜひご覧ください。

