
SpotifyがミスによりKubernetesの本番クラスタを二度も削除。しかし顧客へのサービスにほとんど影響しなかったのはなぜか?
今年、2019年5月20日から3日間にわたりスペイン バルセロナで開催されたKubeCon+CloudNativeCon Europe 2019の基調講演では、SpotifyがミスによってKubernetesのクラスタを消去してしまった経験を振り返るという非常に興味深いセッション「Keynote: How Spotify Accidentally Deleted All its Kube Clusters with No User Impact - David Xia」(基調講演:SpotifyはいかにしてKubernetesクラスタの全削除というミスにもかかわらず顧客への影響を引き起こさなかったのか?)が行われました。
障害が起こることをあらかじめ計画としてインフラの構築どう反映させるのか、そして堅牢なシステムはどのような企業文化から生まれるのか、といった点を学べるセッションになっています。
本記事ではその内容をダイジェストで紹介しましょう。
SpotifyはGoogle Kubernetes Engineを採用
Spotifyのインフラエンジニア、David Xia氏。
Spotifyは音楽をストリーミングサービスとして提供しており、10億人以上のユーザーがサブスクリプションしている。1000人以上のデベロッパーが1万以上の仮想マシンを基盤に開発している。

インフラはGoogle Cloud Platformを利用しており、Kubernetesの基盤としてGoogle Kubernetes Engine(GKE)を利用。
米国、欧州、アジアの3つのリージョンにそれぞれKubernetesの本番クラスタを構築。各クラスタは1時間ごとにバックアップが実行される。
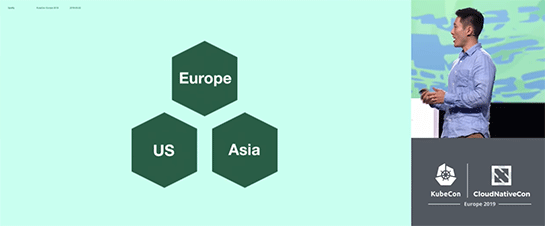
誤ってKubernetesの米国クラスタを削除
2018年、私はGKEの機能をテストするため、本番クラスタと同じ機能を持つテストクラスタを作成して操作していた。
このとき、Webブラウザのタブを複数開いており、あるタブはKubernetesの本番クラスタ、別のタブはKubernetesのテスト用クラスタを操作するためのものだった。
テストが終わったあと、テストクラスタを削除するつもりで、操作するタブを間違って本番クラスタのタブでクラスタの削除を行ってしまう。
GKEはとても操作が簡単で、簡単にKubernetesクラスが作れる。同様に、簡単にKubernetesを削除できる。そして削除をはじめたらその処理を止める方法はない。
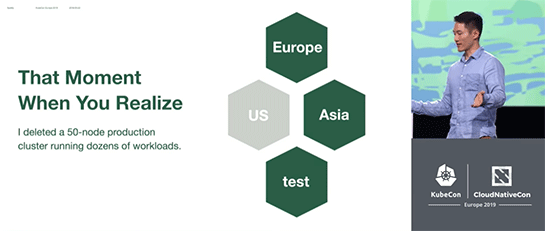
失われたクラスタを再作成するには手作業が必要で、しかも手順がちゃんとマニュアル化されておらず、スクリプトにもバグがあったことなどが影響して、3時間15分かかった。
ふたたびKubernetesのクラスタを削除、今度は2つも削除
約1カ月後、われわれはクラスタ作成をコード化することでこうした問題がふたたび起こることを防ごうと、Terraformを導入した。
これによってクラスタの作成をコード化し、バージョン管理や変更時のレビューなどが可能になる。
しかしこれが原因で、こんどは1つならず2つのクラスタを失うことになるのだ。次にその話をしよう。
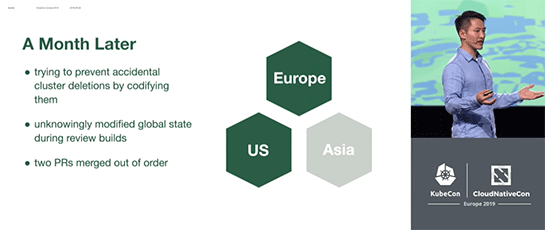
Terraformはクラスタの状態をファイルに保存する仕組みを備えているが、使い始めのころはまだそうした挙動に詳しくなかった。
あるエンジニアがクラスタ定義の動作を確認するためレビュービルドを行ったところ、知らないうちにクラスタの状態を示すファイルが書き換わってしまい、これを本番用のコードにマージしてしまった。
それを本番クラスタに適用したところ、本番クラスタからアジアリージョンが失われてしまった。
アジアクラスタを再構築するべく、Terraformのスクリプトをローカルで動作確認したのちに本番環境で実行した。しかしローカル環境では気づかなかった、本番環境でのパーミッション不足があり、その結果、動作不良によりわれわれは米国リージョンのKubernetesクラスまで失うこととなった。

3つある本番用Kuberntesクラスタのうち、2つまでの同時に失ってしまったのだ。
ユーザーから障害が影響したというレポートはまったくなかった
この障害によってエンジニアチームは、非Kubernetesベースの仮想マシンを多数立ち上げることとなり、それにあわせてインフラチームは古いIPアドレスベースで記述されていた部分をすべてアップデートするといった作業に追われた。
しかし幸いにも、この障害によってユーザーになにか影響があったという報告はまったくなかった。

計画的に障害に備えよ
なぜこういったことが可能だったのか? われわれは計画的に障害に備えており、またKubernetesのような複雑なインフラへの移行は徐々に行っており、しかも社内には積極的に学ぶカルチャーが存在していたためだ。
具体的には、Spotifyにおいて当時Kubernetesの利用はまだβ段階であったため、各チームには全面的なKubernetesへの移行ではなく、部分的な移行を推奨していた。
さらにサービスディスカバリ機構はKubernetesのものではなく社内のものを使ってPodのIPアドレスを指していたため、Kubernetesクラスタが失われたときにはそのIPアドレスを削除してサービスディスカバリを再起動することにより、すぐに非Kubernetesのインスタンスへのフェイルオーバーが可能となった。

まとめ
大事なことは、障害に備えてクラスタをちゃんとバックアップしておくこと。リストアのテストをしていないバックアップは、バックアップの意味をなしていない。

そしてインフラのコード化を進めること。ただし新しいツールの導入は徐々に行うこと。
さまざまな状況を想定した複数のディザスタリカバリテストを行うこと。
社内には、失敗したときに人を責めるのではなく、そこから学ぶという文化を創ること。私がクラスタを削除したときでさえ、Spotifyのチームは私をサポートしてくれた。
そしてようやく先週から、われわれもサービス全体をKubernetesへ移行する準備ができて、その作業を進め始めたところだ。
あわせて読みたい
OLTP+OLAPのエンタープライズ向けRDBMS「Actian X」、ライセンスとサポートを無償で提供する導入支援プログラム開始。新規導入や切り替え企業を募集中[PR]
≪前の記事
ブロードコムによるシマンテック買収交渉が進んでいるとの報道

