
ファーストサーバのZenlogic、ストレージ障害の原因は想定以上の負荷、対策したはずの設定にミスがあったため長期化
ファーストサーバが提供しているホスティングサービス「Zenlogic」は、6月下旬から断続的に生じていたストレージ障害に対応するためのメンテナンスが終了の見通しも立たないほど難航し、結局、メンテナンス開始から3日後の夜にようやくサービスが再開されるという事象を起こしました。
参考:ファーストサーバのレンタルサーバ「Zenlogic」、金曜夜からの全面サービス停止が解けず、いまだ停止中。ストレージ障害のためのメンテナンスで(追記あり) - Publickey
サービス再開から約1週間が経過した7月17日、同社はストレージ障害に関する原因およびメンテナンスによるサービス停止が長期化してしまった原因、再発防止策についての報告書を明らかにしました。
報告によると、ストレージ障害の直接の原因は想定を上回る負荷上昇による高負荷状態であり、さらにその対策として行ったネットワーク設定にミスなどがあってストレージシステム全体がスローダウンしてしまったとのことです。
分散ストレージのキャパシティプランニングのミスが発端
ZenlogicはYahoo! JapanもしくはAWSのいずれかのインフラの上にファーストサーバがサービスを構築するアーキテクチャを採用しています。ファーストサーバは自社でインフラを保有しない戦略をとっているためです。
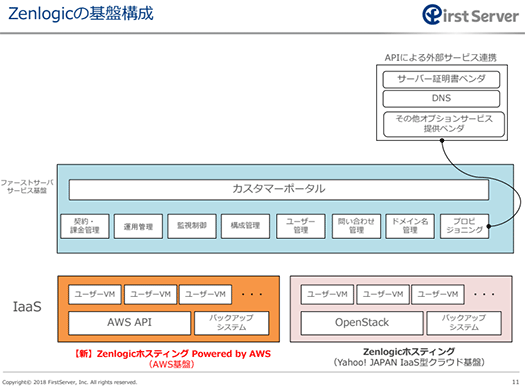
今回障害が起きたのは、Yahoo! Japanのインフラ上に構築されたZenlogicであり、過去にファーストサーバが発表した内容から、ストレージは分散ストレージのCephで構築されていることが推測されます。
Cephは、ストレージサーバをネットワークでつなげて増やしていくほど性能と容量が向上していく、いわゆるスケールアウト可能な分散ストレージを実現するソフトウェアです。ただし、現実にはもちろん無限にスケールできるわけではありません。
このシステム構成の推測と、同社の報告を組み合わせて、なにが起きていたのかを観てみましょう。
まず、同社のストレージ障害の直接的な原因は「ストレージシステムのキャパシティプランでの想定を上回る負荷上昇による一時的な高負荷状態」と報告されています。
ストレージに求められる性能と容量をあらかじめ予測するキャパシティプランニングは難しいものです。ましてや、顧客がどんな用途で利用するか分からないレンタルサーバでのキャパシティプランニングは難しいものかもしれません。
だからこそ、あとからストレージの性能や容量をスケールさせられるスケールアウトストレージをZenlogicのバックエンドに採用したのではないかと考えられますが、その予想を上回る負荷が発生したことが今回の障害の発端でした。
同社は今回の長期メンテナンスに入る前に、何度か障害対策としてストレージの増強とネットワークパラメータの調整などを行ってきたことを明らかにしています。おそらくこれは予想を超えたストレージへの負荷を、Cephのスケールアウト機能を用いて対応させるためにストレージサーバを増やし、それにあわせて分散ストレージの構成について調整を行ったものと推測されます。
ネットワークの飽和を防ぐための設定にミス
しかしこれでは障害が解消しませんでした。
分散ストレージにおいてストレージサーバを増やすと、ストレージサーバ間で処理を平均化するために、追加したストレージサーバへ既存のサーバ群からのデータ移動が行われます。この大量のデータ移動でネットワークが混雑し、今度はそのことが新たな課題となるのです。
Zenlogicでもそれが起きていたようです。
当然同社は、その対策を行ったはずです。次のように報告されています。
ストレージシステム最適化処理などで発生するシステム内部通信がネットワーク全体を飽和させる状況を回避するために、システム内部通信に対してネットワークトラフィック制限を実施しましたが、
しかしこのネットワーク設定にミスがあったと、報告は続いています。
この際のネットワーク設定が一部、不適切な設定となっていたことにより、ストレージシステム全体がスローダウンしました。
ストレージサーバ間のネットワークが十分に機能しなければ、分散ストレージはいつまでたっても本来の性能を発揮できません。Zenlogicもそうした状況になっていたのではないでしょうか。
設定ミスが大量のデータ移動を引き起こし、メンテナンスが長期化
そしてこれまでのストレージサーバの増強とネットワークの設定ミスが重なったことが、最終的に大きな問題となった金曜日夜から月曜日の夜までという異例の長期にわたって大きな問題となった、メンテナンスの長期化の原因のようです。
複数回のストレージシステム増強や、設定値変更に伴い、ストレージシステム内部でこれまでになく大量のデータ移動が発生したこと、および2項のネットワーク設定の一部が不適切な設定となっていたことにより、データ移動完了まで時間を要しました。このため、ストレージシステムの高負荷状態が当初見込みより長期化しました。
ネットワークの設定を正しくし、これまでの設定ミスで偏りが発生していたストレージサーバ間でのデータの移動も最適化しようとした結果、ストレージサーバ間での大規模なデータ移動が発生し、それが終了するのに予想以上に時間がかかってしまった、ということだと推測されます。
対策と返金
同社は対策としてストレージのキャパシティプランの見直しと監視の強化、さらにネットワークの設定のチェック処理の追加などを発表しています。
また障害期間中の利用料金についてはSLAとは別の基準での返金を検討しており、7月末頃までに個別に連絡するとしています。
関連記事
あわせて読みたい
コーディングをAIが支援してくれる「Visual Studio IntelliCode」がアップデート。既存コードからコーディング規約を推測し、適切な設定ファイルを生成
≪前の記事
Angularは包括的なフレームワークだから企業に支持される。UIコンポーネントで知られるインフラジスティックス開発ツール担当VPに聞いた

