
Spark 2.0はフロントエンドAPIの創設と10倍の性能向上を目指す。早くも今年の5月頃登場予定。Hadoop Spark Conference Japan 2016
2月8日に都内で開催された、HadoopとSparkをテーマにした国内最大のカンファレンス「Hadoop Spark Conference Japan 2016」の基調講演には、Sparkの開発を進めているDatabricksのReynold Xin氏が登壇。
Xin氏は、現在開発が進んでいるSpark 2.0の概要を紹介しました。セッションの内容をダイジェストで紹介します。
Spark 2.0: What's Next
DatabricksのReynold Xin氏(写真左)。

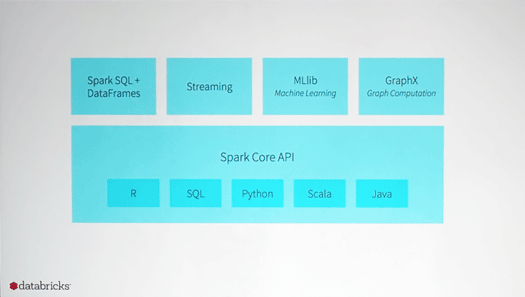
Sparkはスピード、使いやすさ、そして洗練された分析の機能を備えたオープンソースのデータ処理エンジンです。

SpparkのコアAPIではRやSQL、Python、Scala、Javaなどをサポートしています。
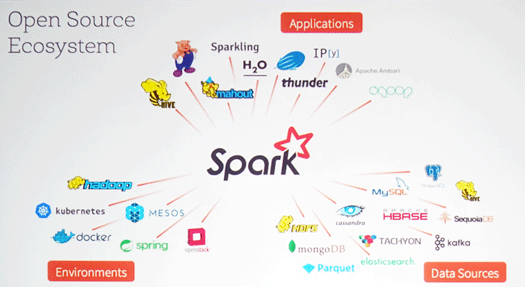
Sparkを取り巻くエコシステムは3つに大別できます。1つはSparkのアプリケーション、2つめはSparkの実行環境、そして3つはデータソースです。
Sparkについて説明したので、Databricksについても紹介しましょう。DatabricksはSparkの創始者によって設立された企業です。Sparkをエンタープライズ向けに提供しています。

昨年2015年はSparkにとって飛躍の年となりました。1000人以上がオープンソースに貢献し、R言語のサポートを開始、幅広い業界が採用するようになりました。
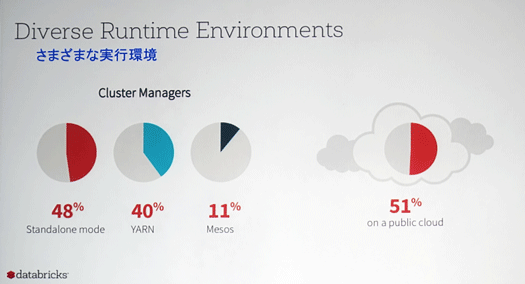
人々がどのような環境でSparkを実行しているのか調べてみたところ、このような結果になりました。半分以上はパブリッククラウドで実行しているのは興味深いところです。

どのようなアプリケーションがSpark上でで使われているかを示したグラフがこれです。エンタープライズで使われているビジネスインテリジェンス、データウェアハウジングが上位で、次がレコメンデーションです。
Spark 2.0はフロントエンドAPIの創設と10倍の性能向上
2015年になって、Sparkはもう完成したの? と聞かれるようになりました。私の答えは「いいえ、開発は今まで以上に活発になって続いている」と答えています。
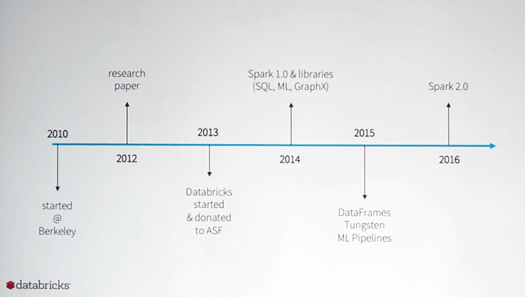
Sparkの開発は2010年にバークリーで始まり、2013年にDatabricksが創立され、この年にSparkがApache Software Foundationに寄贈されるので、Apache Sparkのオフィシャルなスタートはこの年になるでしょう。
2014年にSpark 1.0がSQL、ML、GraphXなどの機能を備えて登場し、2015年にはメジャーバージョンアップによりDataFrames、Tungsten、ML Pipelinesが登場しました。
そして2016年にはSpark 2.0が登場予定です。
Sparkの構造を図で示すとこのようになります。APIを備えたFrontendと実行をするバックエンドが相互に通信しています。

Spark 2.0では、フロントエンドAPIを創設します。これはStreaming、DataFrame/Dataset、SQLを含んでいます。
バックエンドにおいては桁違いの性能向上、つまり10倍の性能向上を見込んでいます。

APIを創設するに当たっての指針は次のように考えています。
シンプルで、セマンティックがきちんと正義され、バックエンドの最適化ができるように十分に抽象化されていることです。

最初に作られたAPIであるRDDはJava/Scalaから利用でき、これはバックエンドのJavaVMで実行されます。次に作ったDataFrameは、ロジカルプランを通したあと最適化がはかられ、バイナリが生成されて実行されます。
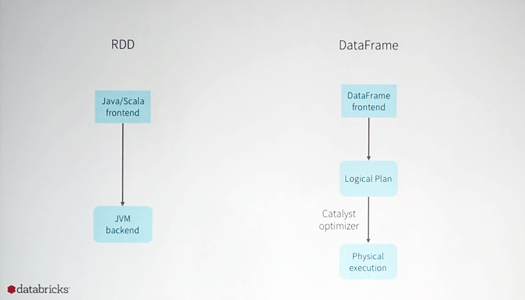
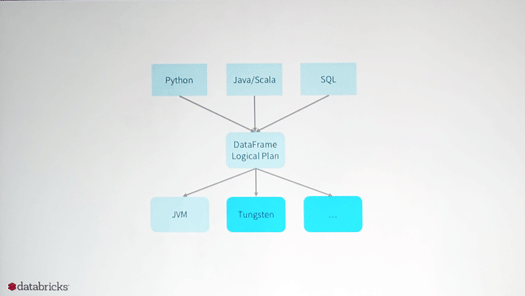
われわれはDataFrame APIを作り直し、Python、Java/Scala、SQLなどで使えるようにしていきます。そこからロジカルプランを通して実行用のバイナリが生成される。しかもこれはTungstenや、あとからより効率的な新しい実行系を追加することもできます。
Spark 2.0でのAPI創設には、主に以下の3つのテーマがあります。ストリーミングDataFrames、DataFrameとDatasetの成熟とマージ、そしてANSI SQLのサポートです。

しかしストリーム処理には課題があります。


詳細は数週間後に明らかにする予定。
10倍の性能向上は可能か?
Sparkはすでにかなり高速だが、Spark 2.0でさらに10倍高速にできるのでしょうか?
少しだけそのようすをお見せしましょう。

これらがいまSpark 2.0で検討されていることです。
スケジュールは次のように予定されています。

Hadoop Spark Conference Japan 2016
あわせて読みたい
Yahoo! JapanのHadoopクラスタは6000ノードで120PB。指数関数的に増大するデータ需要を技術で解決していく。Hadoop Spark Conference Japan 2016
≪前の記事
Apache Hadoopの現在と未来。YARNもHDFSも新しいハードウェアに対応して進化していく。Hadoop Spark Conference Japan 2016

