
FacebookがHBaseを大規模リアルタイム処理に利用している理由(前編)
Facebookは大規模なデータ処理の基盤としてHBaseを利用しています。なぜFacebookはHBaseを用いているのか、どのように利用しているのでしょうか? 7月1日に都内で行われた勉強会で、Facebookのソフトウェアエンジニアであるジョナサン・グレイ(Jonathan Gray)氏による解説が行われました。

解説はほぼスライドの内容そのままでした。当日使われた日本語訳されたスライドが公開されているので、ポイントとなるページを紹介しましょう。
Realtime Apache Hadoop at Facebook
なぜリアルタイムデータの分析に、Hadoop/HBaseを使うのか?
MySQLは安定しているが、分散システムとして設計されておらず、サイズにも上限がある。一方、Hadoopはスケーラブルだがプログラミングが難しく、ランダムな書き込みや読み込みに向いていない。

Facebookがデータストアに求めていたのは、大半がほとんどアクセスされないという特徴を持つ巨大なデータを保存でき、柔軟性と可用性があって、強い一貫性を実現できること。一方、データセンター内のネットワークは二重化していたので、ネットワーク分断耐性は求めていなかった。

この要件に合致したのがHBase。抜群の書き込み性能と読み込み性能があり、十分な可用性などがあった。


HBaseはHadoopの一部として開発されたもので、Facebookではその利用にあたり、Hadoopに変更を行った。その1つがファイルの追記(Append)機能。書き込み中にSyncすると、そこまでのファイルがほかのクライアントから見えるようになる。

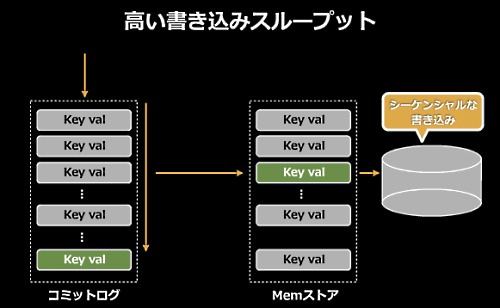
データの書き込みは、まずシーケンシャルにコミットログに書き込み、メモリストアにはソートされて保持される。ディスクにはそれをシーケンシャルに書き込んでいる(ディスクへの書き込みがつねにシーケンシャルであるために、書き込み性能が非常に高い)。
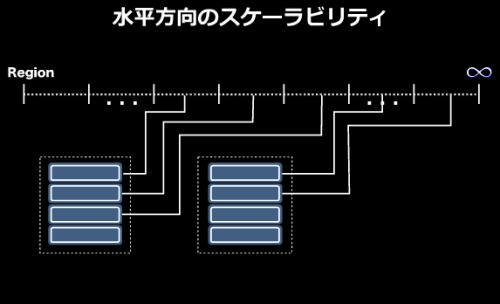
水平方向のスケーラビリティは自動シャーディングによって実現されている。例えば、2台のサーバがそれぞれ4つのシャード(合計8つのシャード)を保持しているとする。
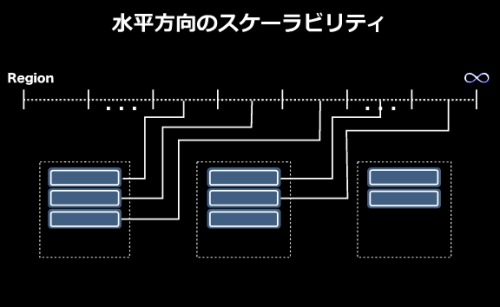
そこへ3台目のサーバが追加されると、自動的に3台目のサーバにシャードが分散配置される。
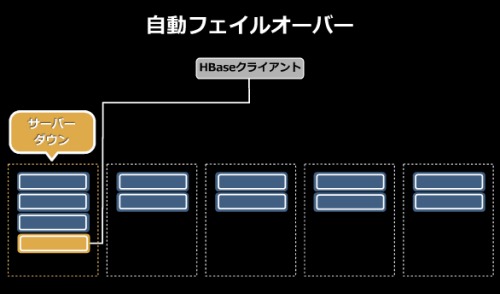
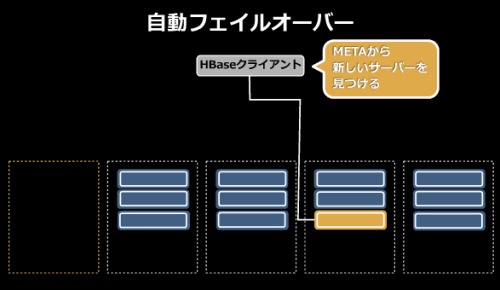
自動フェイルオーバー機能も備える。あるサーバに対して操作中にサーバがダウンすると、そのシャードは自動的に別のサーバに再配置されて処理が続行される。
続きとなる後編では、HBaseが実際にどのようなアプリケ-ションで使われているのかを紹介します。
≫FacebookがHBaseを大規模リアルタイム処理に利用している理由(後編)

