
終わりなく増えていくストリームデータ特化の分散ストレージ「Pravega」、EMCがオープンソースで公開。これまでのストレージとどう違う?[PR]
ファイルへの保存やデータベースへの格納といった、これまで親しまれてきた方法では扱いにくい、新しい形式のデータが存在感を高めつつあります。
それは継続的に大量のデータが流れ込んでくる「ストリームデータ」です。
例えば、システム内のさまざまなアプリケーションやサーバが生成するログ、ソーシャルメディアから流れてくる利用者の声や自社製品の評判、あるいはIoTを活用したシステムでは、工場内やオフィス、工作機械や自動車などの機器に組み込まれた多数のセンサーから大量に送られてくるリアルタイムデータなどがそれにあたります。
Pravega:終わりがなく増えていくストリームデータのためのストレージ
ストリームデータの特徴として、その内容が温度や位置情報、画像、動画、文字列など多様で、データの断片ごとに時刻や順番を持つこと。さらにストリームデータの量は動的に変化し、明確な終わりがないため容量が際限なく増えていくこと、などが挙げられます。
こうしたストリームデータを扱うシステムは、例えばKafkaでリアルタイムにデータを収集し、それをCassandraやSparkなどで分析する、といった複数のミドルウェアを組み合わせた構成が一般的でしょう。この場合、ミドルウェアごとにそれぞれストレージを持つ個別のシステムで運用されることになります。システム管理は複雑になり、システム間でのデータ複製などによる手間もかかるものになるでしょう。
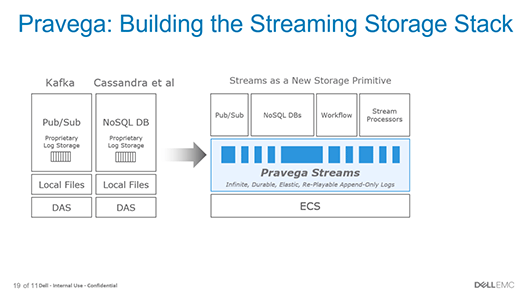
こうしたストリームデータにおける課題を解決するためにDell EMCがオープンソースとして公開した「Pravega」(プラベガ)は、ストリームデータの処理に最適化された単一の抽象化されたスケーラブルな分散ストレージを実現するソフトウェアです。
Pravegaはストリームデータを高信頼かつスケーラブルに保存するストレージを実現すると同時に、保存したデータをほかのシステムに複製せず、そのままPravegaのうえで分析、加工することを可能にします。

高速なストレームデータ処理と大規模なアーカイブをティアリングで実現
Pravegaは、ストリームデータを短期間保存するTier-1ストレージとしてリアルタイム処理に最適化された高可用分散ストレージのApache BookkeeperをPravegaクラスタ内に実装し、長期間の保存のためのTier-2ストレージとして、Pravegaクラスタの外部に配置された大容量向け分散ファイルシステムのApache HDFS、Dell EMC IsilonまたはElastic Cloud Storage (ECS)を用いることができます。
この2つの階層化ストレージの上に、ストリームデータAPI(Segment Store)、コントローラ(Controller)、分散処理基盤(Zookeeper)などを加えものが、Pravegaの基本的な構造となります。
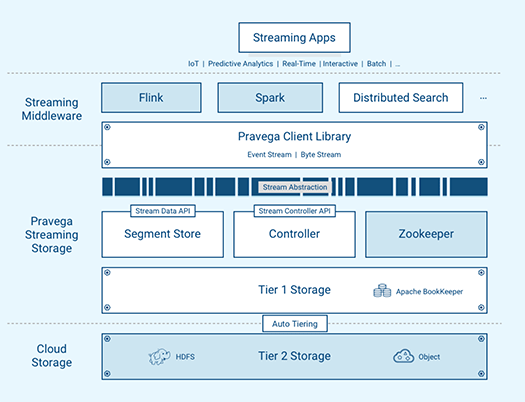
Pravegaがストリームデータを受け取ると、まずは受け取ったサーバのローカルキャッシュにデータが書き込まれ、すぐにTier-1ストレージ(Bookkeeper)によってPravegaクラスタ内の3つのサーバに冗長化されて保存されます。この処理は10ミリ秒以内に行われ、これによって高速な書き込みと高可用性が保証されます。
やがてBookkeeper上でデータがある程度の大きさになると、自動的にTier-2ストレージ(HDFS/Isilon/ECS)へデータがまとめて移されます。Tier-2ストレージへの保存が完了すると、Bookkeeper上に保存されていた3つのデータは削除され、新たな読み出しはTier-2ストレージから、またはBookkeeper上にプリフェッチ(先読み)されてキャッシュから行われます。
この2つの階層化ストレージを抽象化することで、Pravegaはリアルタイムにストリームデータを保存しつつスケーラブルで高可用かつ大容量なストレージを実現しているのです。
そして保存されたデータは読み出し用のストリームデータAPI経由で、いつでも正確に読みだしてリアルタイムとバッチのいずれの手段でも柔軟に分析、加工できます。
一度だけ確実に実行することを保証する「Exactly Once」対応
Pravegaの優れた点は、ストリームデータを分析や加工のためにわざわざ別のシステムへデータをコピーする必要がなく、従来の複雑なリアルタイムデータ処理システムに対してシンプルで高速、スケーラブルなシステムを実現できる点にあります。
さらにPravegaでは、ストリームデータに対して「Exactly Once」の特性を備えています。つまり、送信されてきたデータを失うことなく確実に捕らえ、重複することなく処理し保存する高い信頼性がある、というものです。

PravegaはIoTなどストリームデータが主役となる新しいITシステムにおけるストレージ基盤となる新しい世代のストレージ仮想化ソフトウェアだといえます。
そしてDell EMCはこのPravegaとリアルタイム分析エンジンのApache Flinkなどをハイパーコンバージドシステムに搭載し、ストリームデータ処理のための統合アプライアンス「Project Nautilus」も発表しています。それについては、また別の記事で紹介することにしましょう。
≫Pravega - Stream as a New Distributed Storage Primitive
(本記事はDell EMC提供のタイアップ記事です)
あわせて読みたい
Apache FlinkとPravegaを用いてリアルタイムデータ分析に最適化された統合システム「Project Nautilus」登場[PR]
≪前の記事
JITコンパイラを初搭載した「Ruby 2.6.0-preview1」リリース。大幅な実行速度向上を目指し

