
セールスフォースのアーキテクチャ(マルチテナントデータベース編)~ Flex Schemaとオプティマイザ
米国の計算機学会として知られるACMが主催したクラウドコンピューティングのシンポジウム「ACM Symposium on Cloud Computing 2010」(ACM SOCC 2010)が6月10日、11日にインディアナ州インディアナポリスで開催されました。
基調講演では、セールスフォースのアーキテクチャの解説が行われました。複数の利用者のデータを1つのデータベースに格納しているセールスフォースのクラウドでは、どのようなデータベース構造で、また検索のオプティマイズなどはどうしているのしょうか?
(この記事は「セールスフォースのアーキテクチャ(物理アーキテクチャ編)~ Podによるスケールアウト」の続きです)
マルチテナントとしてのデータベース構造と最適化
セールスフォースの内部でOracle RACを使っていることは説明したが、すべてのユーザーが共有するデータベースで、どのような構造でマルチテナントとしてのデータを保存しているのか、今度はそのことについて説明しよう。
(Force.comを用いると自由なスキーマでデータを定義できるため)さまざまなテーブルを持つテナントのデータをどのように保存しているのかといえば、実際には巨大な1つのテーブルとして格納している。
その基本的な仕組みは、値を入れるすべての列が可変長文字列になっていて、ここにデータが保存されている(図ではIDとTenantを除く「Data2」が可変長文字列。実際にはこの可変長文字型の列が501列設定されている)。これをFlex Schemaと呼んでいる。
下記の図では、この1つのテーブルに、Harrah'sの2つの仮想テーブルと、Dellの1つの仮想テーブルが保存されていることが分かる。
テーブルの1行目から3行目までがHarrah'sの1つ目の仮想テーブルで、何かの価格が保存されていり。4行目から6行目までが2つ目の仮想テーブルで、ゲームの名前が保存されてる。7行目から9行目はDellのテナントのためにプロダクト名が保存されている(Flex Schemaの詳しい解説は、記事「知られざる「マルチテナントアーキテクチャ」(3)~スキーマとメタデータの謎」を参照)。
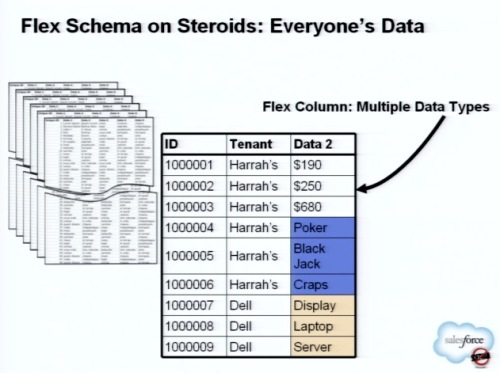
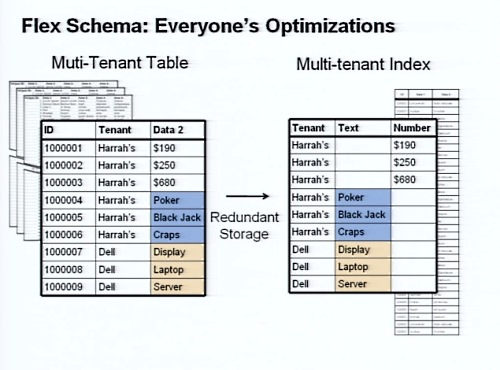
このように、実際には1つの巨大なテーブルの中にマルチテナントのデータが格納されているのだ。では、これに対してテナントごとに効率的な検索を行おうとするとき、どのような検索をするべきだろうか? 少なくとも、可変長文字列のデータが大量に保存されている列にインデックスを付けるのは非現実的なのだ。
そこで、基となるマルチテナントテーブルに対して非正規化を行い、テキスト型と数値型、日付型などデータ型ごとの列に分けたマルチテナントインデックス用のテーブルを作成し、この列に対してインデックスを設定する。これをアクセラレーテッドテーブルと呼ぶ。
マルチテナントテーブルに対する操作は、自動的にアクセラレーテッドテーブルにも反映され、両者は同期するようになっている。アクセラレーテッドテーブルによって、検索を高速化できる。
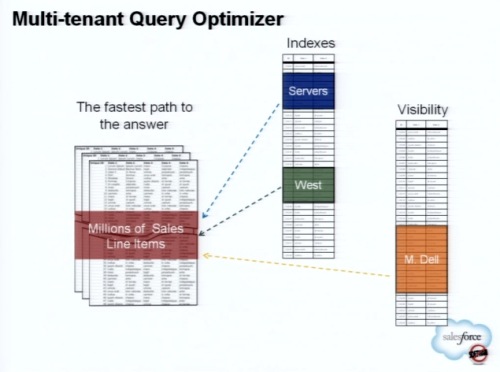
セールスフォースでは、マルチテナントに対応したクエリオプティマイザも実装している。
たとえば、セールスフォースではユーザーによってデータの「ビジビリティ」が異なる。組織のCEOならば、その組織(テナント)のデータすべてにアクセスができるだろう。しかし、営業担当者ならば一部のデータにしかアクセスできないかもしれない。
CEOが、サーバ(Servers)の西部地域(West)での売上げをチェックしようとしたとき、セールスフォースのマルチテナント対応クエリオプティマイザはどう働くかといえば、CEOは広い範囲のデータにアクセスできるため、まず必要なデータを取り出してからビジビリティの制限情報とジョインをして絞り込む、という方法をとるだろう。
一方で営業担当からのクエリであれば、ビジビリティの範囲が狭いので、先にビジビリティとジョインしてデータを絞り込んでから目的のデータ検索を実行するかもしれない。
このように、セールスフォースのマルチテナント対応クエリオプティマイザは、トラディショナルなデータベースが備えるコストベースのオプティマイザのように、まず統計情報を分析し、ジョインに先立って判断するといったことを行う。
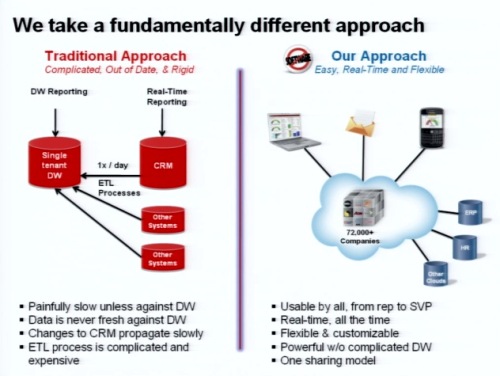
クラウドによるリアルタイムなレポーティングにも注力している。
これまでのデータウェアハウスでは、ETLツールなどを使ってCRMなどからデータを移動し、統合して分析するという手法を用いている。しかし私たちが考えているのは、いまあるクラウドのインフラ、Oracleやクエリオプティマイザなどをそのまま活用し、ビジネス分析とレポーティングをリアルタイムに実現するモデルだ。
このリアルタイムモデルを実現するために、これから2~3年はクラウドでのデータ分析に投資をする。
そのために、セールスフォースにとってはレアケースだが、内部にテナント固有のテーブルをダイナミックに生成する。レポートのための分析クエリを実行するには、テナントがテーブルを共有するこれまでのクエリでは十分に効果的ではないからだ。特定のテーブルにすることで、メモリ上においてハッシュジョインなども可能となる。
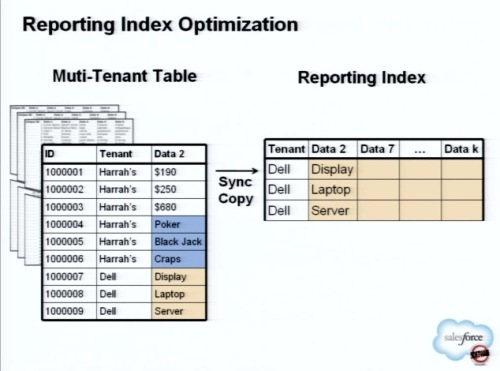
これ以外にもさまざまなテクニックを用いて、クラウドでのリアルタイム分析を実現していく。利用者はより大規模なデータセットをクラウドに置こうとしており、それを分析することはアドオンやオプションではなく基本的な機能とみなされるようになってきているのだ。
記事「セールスフォースのアーキテクチャ(シングルコード編)~ セールスフォースの内部コードで見る、過去との互換性をどう保つか」へ続きます。
記事「セールスフォースのアーキテクチャ」
- セールスフォースのアーキテクチャ(物理アーキテクチャ編)~ Podによるスケールアウト
- セールスフォースのアーキテクチャ(マルチテナントデータベース編)~ Flex Schemaとオプティマイザ
- セールスフォースのアーキテクチャ(シングルコード編)~ セールスフォースの内部コードで見る、過去との互換性をどう保つか
関連記事
あわせて読みたい
セールスフォースのアーキテクチャ(シングルコード編)~ セールスフォースの内部コードで見る、過去との互換性をどう保つか
≪前の記事
セールスフォースのアーキテクチャ(物理アーキテクチャ編)~ Podによるスケールアウト

