
GitLab.comが操作ミスで本番データベース喪失。5つあったはずのバックアップ手段は役立たず、頼みの綱は6時間前に偶然取ったスナップショット
ソースコード管理サービスを提供するGitLab.comは、1月31日23時頃(世界協定時。日本時間2月1日15時頃)、操作ミスから本番データベースのデータの大半を失い、サービスが停止するという事故を起こしました。
The incident affected the database (including issues and merge requests) but not the git repo's (repositories and wikis).
— GitLab.com Status (@gitlabstatus) 2017年2月1日
これにより同社のWebサイトもサービスを停止。ただし、GitリポジトリとWikiに関しては影響を受けていないと報告されています。
 GitLab.comのWebサイトも障害対応モードに
GitLab.comのWebサイトも障害対応モードにこの記事を執筆している日本時間2月1日23時半現在、同社はまだ復旧作業の途中。なんとバックアップデータからデータベースのリカバリを行っているようすをYouTubeでストリーミング公開しています。
 リカバリのためのデータリストアの状況をYouTubeで生放送。待ち時間にエンジニアがユーザーの自由な質問に答えるゆるさも(上記はストリーミングのキャプチャ画像)
リカバリのためのデータリストアの状況をYouTubeで生放送。待ち時間にエンジニアがユーザーの自由な質問に答えるゆるさも(上記はストリーミングのキャプチャ画像)果たしてGitLab.comで何が起きたのでしょうか? これまでの経緯をまとめました。
スパムによるトラフィックのスパイクからレプリケーションの不調へ
GitLab.comは今回のインシデントについての詳細な経過を「GitLab.com Database Incident - 2017/01/31」で公開しています。また、もう少し整理された情報がブログ「GitLab.com Database Incident | GitLab」にも掲載されています。
これらのドキュメントを軸に、主なできごとを時系列に見ていきましょう。
1月31日16時(世界協定時。日本時間2月1日午前8時)、YP氏(Yorick Peterse氏と思われる)はPostgreSQLのレプリケーションを設定するためにストレージの論理スナップショットを作成。これがあとで失われたデータを救う幸運につながります。
1月31日21時頃、1人のスパムユーザーが4万7000ものIPアドレスを用いたサービスへの集中的なアクセスでデータベースの負荷が上昇。このスパムユーザーをブロック。
High load was partially caused by 47 000 IPs logging in to the same account at a high rate
— GitLab.com Status (@gitlabstatus) 2017年1月31日
1月31日22時頃。スパムで生じた大量のデータ書き込みがセカンダリデータベースでオンタイムに処理できなかったことが原因で、PostgreSQLからレプリケーションにおいて大きなラグが発生しているとアラートがあがる。
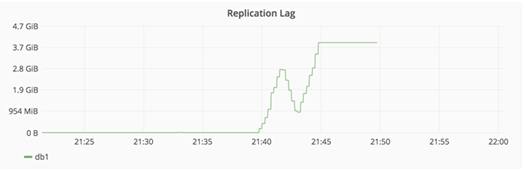
YP氏はもういちどクリーンな状態からレプリケーションを開始しようと、セカンダリのいくつかの不要データを削除。なおもレプリケーションがうまくいかないため、原因と思われる設定を変更してPostgreSQLを再起動。
We will be performing a PostgreSQL restart, this will take https://t.co/r11UmmDLDE offline for a short period of time
— GitLab.com Status (@gitlabstatus) 2017年1月31日
時刻は現地時間で23時頃を過ぎ、YP氏は仕事を早く切り上げるつもりが、突然のトラブルで遅くなってしまってイライラし始めます。
YP氏、決定的な操作ミスでデータを失う
1月31日23時頃。(ここで決定的な操作ミスが発生するので、以下は報告を訳します)
YP thinks that perhaps pg_basebackup is being super pedantic about there being an empty data directory, decides to remove the directory. After a second or two he notices he ran it on db1.cluster.gitlab.com, instead of db2.cluster.gitlab.com
YP氏は、おそらくpg_basebackupに空のデータディレクトリが存在することによって動作がおかしくなっているのだろうと考え、このディレクトリを削除することにした。しかしその1~2秒後、彼はその操作が(セカンダリの)db2.cluster.gitlbab.comにではなく、(プライマリの)db1.cluster.gitlab.comに対して実行したことに気がつく。
そしてこの1~2秒が致命傷に。
2017/01/31 23:27 YP - terminates the removal, but it’s too late. Of around 310 GB only about 4.5 GB is left - Slack
YPはすぐさま削除を停止させたが、もう遅かった。約310ギガバイトあったデータのうち、残ったのは4.5ギガバイトであった。
GitLab.comは本番データベースを失い、緊急のデータベースメンテナンスへ突入。
We are performing emergency database maintenance, https://t.co/r11UmmDLDE will be taken offline
— GitLab.com Status (@gitlabstatus) 2017年1月31日
事故で本番データベースを失い、リストア作業に入ることをユーザーに報告。
We accidentally deleted production data and might have to restore from backup. Google Doc with live notes https://t.co/EVRbHzYlk8
— GitLab.com Status (@gitlabstatus) 2017年2月1日
ここからGitLab.comはバックアップデータからデータをリストアしようとするのですが、そこには予想以上のトラブルが待っていました。
バックアップ手段のうち5つが機能していなかった
GitLab.comはデータのバックアップ手段をふだんから複数用意していたはずでしたが、実際にバックアップデータを確認したところ、そのほとんどが機能していなかったという悲惨な現実に向き合うことになりました。
論理スナップショットは24時間ごとに取られる設定になっていました。今回はたまたま、データが失われる6時間前にスナップショットがとられました。
定期的なバックアップも24時間ごとにとられているはずでしたが機能していなかったようで、バックアップファイルは見つかりませんでした。
PostgreSQLのデータベースをバックアップするpg_dumpも定期的に実行されていたはずでしたが、PostgreSQLのバージョン違いによるエラーに気付かず、実行に失敗していたためバックアップはとられていませんでした。
NFSサーバに対してMicrosoft Azureのディスクスナップショットがとられていましたが、データベースサーバは対象となっていませんでした。
レプリケーションの手順は非常に脆弱で、エラーが起きやすく、マニュアル操作に依存するにもかかわらず、きちんと文書化されていませんでした。
同期プロセスはデータをステージング環境にあげるとWebhooksを消去してしまうため、24時間以内にそれを定期バックアップから取り出さない限り失われてしまうものでした。
Amazon S3へのバックアップも機能しておらず、バックアップファイルは空でした。
つまりリストア可能なバックアップファイルとして、たまたま6時間前にとられていた論理スナップショットが存在していました。そこで、この論理スナップショットがリストアに使われたようです。
YP氏はすっかり意気消沈のようす。
YP says it’s best for him not to run anything with sudo any more today, handing off the restoring to JN.
YP氏は、もう今日は自分がこれ以上sudoコマンドを実行しないほうがいいだろうと言って、リストア作業をJNに依頼。
その後の作業の説明は「We’re working on recovering right now by using a backup of the database from a staging database.」とされており、バックアップデータからデータベースのリカバリ作業が行われています。その様子はYouTubeのストリーミング動画で公開されています。
Live stream of us working to restore https://t.co/r11UmmDLDE: https://t.co/8D641MRczH
— GitLab.com Status (@gitlabstatus) 2017年2月1日
リカバリ作業を見守る3人のGitLab.comエンジニアはいずれも自宅からリモートで操作。ストリーミングを見ていると、ときおり子供の声らしきものが聞こえます。ただしそれぞれのタイムゾーンが異なるらしく、途中で1人はオフラインとなり寝たと説明がありました。
データがリカバリされていく様子もときどきツイートで報告されています。
We are 68% done with the database copy
— GitLab.com Status (@gitlabstatus) 2017年2月1日
We are 78% done with the database copy
— GitLab.com Status (@gitlabstatus) 2017年2月1日
We are 86% done with the database copy
— GitLab.com Status (@gitlabstatus) 2017年2月1日
日本時間2月2日0時0分時点で、まだ復旧作業は続いています。
日本時間2月2日午前1時半頃に、スナップショットをとった時点の状態にデータを戻すところまでいった模様。
We have the data, we are snapshotting to have a closer backup in case things go wrong
— GitLab.com Status (@gitlabstatus) 2017年2月1日
この状態からどうやってサービスを立ち上げていくか、エンジニアが議論しながら作業する様子もそのままストリーミングで公開されています。
 (画面はストリーミングのキャプチャ)
(画面はストリーミングのキャプチャ)(2月2日 午前11時追記)
その後、データベースのリストアに成功。
Database data restored, we're making sure all data we have currently is OK
— GitLab.com Status (@gitlabstatus) 2017年2月1日
サイトも復活しました。
https://t.co/r11UmmDLDE should be available to the public again
— GitLab.com Status (@gitlabstatus) 2017年2月1日
参考記事
ソースコード管理ツールのGitLabは、新バージョンとして公開された「GitLab 10.6」で、CI/CD機能(継続的インテグレーション/継続的デリバリ機能)と連係するソースコードリポジトリとしてGitHubやBitBucketなど、GitLab以外のGitリポジトリを設定可能となる新機能を含む「GitLab 10.6」を発表しました。
GitLab 10.4では、デプロイ前のDockerイメージに対して静的セキュリティ解析を行うツールや、動的にセキュリティ解析を行うツール、そしてWebブラウザから利用できる統合開発ツールなどが搭載されました。
ソースコード管理サービスを提供するGitLabは、GitHubなどに対応する開発者向けチャットサービス「Gitter」をオープンソースとして公開しました。
あわせて読みたい
オラクル、AWSとAzureでのOracle DBライセンス体系を変更。コア係数が適用外になり、ライセンス価格が2倍に
≪前の記事
W3CとIDPFが正式統合。Web技術と出版技術を融合する将来に向け、ロードマップ作成に着手

