
ラックごとに物理的にコンピュータリソースを最適化するFacebookの技術「Disaggregated Rack」とは何か?
Facebookは、データセンターのサーバ構成をより柔軟にするための新しい手法「Disaggregated Rack」を、1月に米サンタクララで開催されたOpen Compute Summit Winter 2013で明らかにしています(いまになって公開された動画を見ていたら見つけました)。
データセンターのサーバやストレージを効率的に利用するためには、仮想化によってリソースプールを作り、アプリケーションに応じてそれを切り出して使う方法が一般に考えられています。
しかしFacebookが採用する方法は、CPUやメモリやストレージを物理的なコンポーネントにして、それをラックに追加したり引き抜いたりすることでラックごとのシステム構成を物理的に変えてしまおうという手法です。
公開されているビデオから、Disaggregated Rackがどういうものか、まとめました。
ソフトウェアのハードウェアに対する要求が変わったらどうする?
Facebook Director, Capacity Engineering & Analysis Jason Taylor氏。担当は、Facebookのサーバキャパシティが決して不足しないようにすること。そのための予算管理と効率化の推進。

「Facebookにとってサーバの大量利用と効率化は非常に重要だ」とTaylor氏。そのための新しい方法が「Disaggregated Rack」。以下、Taylor氏のスライドと発言のポイントです。
まず、Facebookのサーバは用途別に5種類に大別されているとのこと。
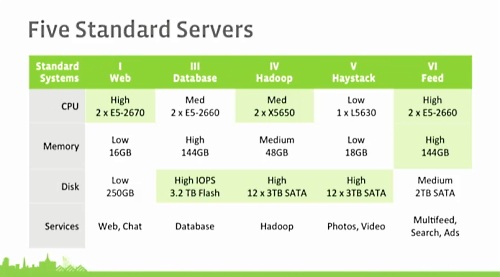
Web用はもっとも大量に購入されるサーバで、演算性能に最適化された構成になっており、Database用サーバはIOPSが必要なためフラッシュストレージを採用。Hadoopはボトルネックになりやすいため、高性能のCPUと多数のディスクを搭載。Haystackは写真を保存するため大容量ストレージを搭載し、Feed用サーバは高性能のCPUとメモリを必要とする。
サーバを5つのタイプに絞ることで、大量購入のディスカウントが可能になるとともに、構成を変更して別の用途へ振り分けやすくなり、運用もシンプルで新しいサーバを数時間で本番環境へ投入できるといったメリットがある。
しかし課題もある。時間がたつにつれて、ソフトウェアが要求するハードウェア仕様は変化してくる。そのとき、サーバを新しい要求に合わせて入れ替えたり、筐体を開けてCPUを変更したりメモリを追加したりしなくてはならないのか?
こうした課題を解決するために採用するのが「Disaggregated Rack」だ。
ラック単位でコンポーネントを抜き差しする
Facebookのソフトウェアは、ラック単位のリソースで考えられている。ラックあたりCPUがいくつあり、メモリ容量は合計でいくらか、ストレージ容量やフラッシュの容量はいくらなのか。
Disaggregated Rackは、コストを抑えつついかにラックごとのハードウェア構成を容易に再構成できるか、という課題の解決だ。

まずComputeノード。これは演算能力を提供する。ネットワークブートでストレージは持たない。

Ram Sled(Sledは“そり”の意味。おそらくラックのレールを滑らせるそりをイメージしたのではないか?)は、キーバリューペアを保存するメモリ容量を提供する。CPU性能はあまり気にしないので、FPGAやASIC、モバイル用プロセッサも使う。

Storage Sledは大容量ストレージを提供する。

Flash Sledはフラッシュストレージを提供する。

これらのSledをラックに追加したり抜き出したりすることで、ラックに対してハードウェア構成を容易に変更できるようになる。
例えば、サーチ機能にとってハードウェア構成で重要なのは、ラックにおけるメモリ容量とフラッシュストレージ容量の比率だ。当初、メモリとフラッシュの比率は1対10だった。その後サーチチームの要望で1対15に変更するのに、Flash Sledを4つラックに追加することで実現できた。
もしもDisaggregated Rackの仕組みでなければ、ラックからサーバを抜いて筐体ごとに構成を変更することになり、面倒だ。Disaggregated Rackなら、引き抜いたSledを別のラックで再利用することも容易だ。
Disaggregated Rackは、サーバ仮想化でリソースを調整するのとは異なるアプローチであり、ハードウェアの構成を変更してアプリケーションにフィットさせる方法だ。
この方法は構成のカスタマイズが容易で、サービスに応じてハードウェアを進化させていける。ハードウェアのリフレッシュも簡単で、イノベーションのスピードを上げていける。
(Tylor氏の発言はここまで)
アプリケーションの種類がある程度限定されているから可能か
Facebookがこのようにラック単位で物理的に最適な構成変更を可能にする技術を利用できるのは、基本的にどのようなアプリケーションが実行されるのかあらかじめ分かっており、それが短期間で大きく変わったりしない、という点が大きいのではないでしょうか。
クラウド、特に商用クラウドのデータセンターでは、利用者がそこでどんなアプリケーションを実行するのかをあらかじめ知ることはできません。ですから、要求があれば即座に構成を変更できるソフトウェア的な仮想化の技術が不可欠でしょう。
しかしFacebookが自社のアプリケーションを自社のデータセンターで稼働させる場合には、あらかじめソフトウェアとハードウェアをすりあわせて最適化することはそれほど難しいことではないでしょう。そのために物理的な構成を変更することで、仮想化のオーバーヘッドを排除できることは、Facebookのユースケースでは都合がいいはずです。
プロセッサ、メモリ、ストレージをコンポーネント化し、必要に応じて組み合わせるという方法論は、より柔軟で高効率なデータセンターの構築砲としては優れたものです。いまはまだサーバのプロセッサとメモリを一般的に切り離すことはできていませんが(Facebookもデータをキーバリュー型で管理するから実現できているわけで)、いずれもっとスマートな方法でサーバの機能は分解されコンポーネント化され、それを統合することが、将来のデータセンターを構築するテクノロジーとして一般化されていくのではないかと思われます。
そのときには、FacebookがRAM Sledでインテルプロセッサにこだわらなかったように、アプリケーションを処理するメインのプロセッサ以外のところで、用途に応じたさまざまなプロセッサがラック内で活用されることにもなりそうです。
あわせて読みたい
PayPalがVMwareからOpenStackに移行する理由は「可用性を犠牲にすることなくスケーラブル」だから
≪前の記事
グーグルがChrome DevToolsの学習ビデオを公開。DOM操作からプロファイリング、メモリリークの発見まで詳しく学べる

