
マイクロソフトのHadoop対抗技術「Dryad」、いよいよ始動か?
大規模分散処理のフレームワークとしてグーグルが開発したMapReduce処理や、そのオープンソース実装であるHadoopが急成長し、ビジネスの分野での商業利用が立ち上がり始めていることは、Publickeyでも何度か記事で紹介してきました。
- Hadoopを表計算のように使える「InfoSphere BigInsights」、IBMが発表
- グーグルによるMapReduceサービス「BigQuery」が登場。SQLライクな命令で大規模データ操作
- Hadoopは企業のための新たな情報分析プラットフォームとなる、とCloudera
グーグルがBigQueryの開始を発表し、IBMも大規模処理のエンジンとしてHadoopを採用、AmazonクラウドでもHadoop処理を行う「Amazon Elastic MapReduce」サービスを提供していることから分かるように、Hadoopはクラウドでの大規模データ処理において中心的な存在になると目されています。
しかしマイクロソフトはこれらMapReduce/Hadoopの動向とはほとんど無縁でした。
日経コンピュータ7月7日号で、マイクロソフトのクラウドプラットフォーム推進部 平野和順部長は、Windows AzureでのHadoopのサポートを明確に否定しつつ、独自の対抗技術であるDryadの投入をほのめかしています。
「利用者がHadoopをAzureで動かすのは可能だが、当社がサービスとして提供する予定はない。それよりもマイクロソフトのMapReduce対抗バッチ処理技術『Dryad』が利用できるようになる可能性の方が高い」(39ページから)
マイクロソフトのDryadとはどのような技術なのでしょうか? マイクロソフトのアーキテクトエバンジェリスト岩出智行氏のブログで公開されたエントリ「Dryad プロジェクト ~ Microsoft Research 研究紹介シリーズ」(以下、「Dryadプロジェクト」)で、Microsoft ResearchのDryad解説ページの翻訳など解説をしています。日経コンピュータの記事とこの記事などを合わせて、Dryadのポイントを見てみましょう。
MapReduceとDryadの違いは?
Dryadの解説を見る前に、まずHadoopの基となったMapReduce処理とはどのようなものか、簡単に紹介しておきましょう。
MapReduceとは、簡単に言えば大規模なデータを小さなデータに分割して処理するMap処理と、それをまとめて結果として出力するReduce処理からなります。書籍「Googleを支える技術」から、図を引用します。
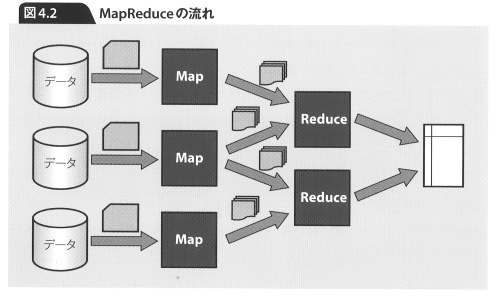
このMapReduceとマイクロソフトのDryadはどう違うのでしょうか? Dryadプロジェクトでは、次のように解説されています。
2つのシステム(Dryad と MapReduce)の最も基本的な違いとして、MapReduce では map/distribute/sort/reduce といった一連の操作を逐次実行することが求められるのに対して、Dryad では任意の DAG(Directed Acyclic Graph:有向非循環グラフ)によって処理を実行できるという点です。
特筆すべき点としては、 Dryad では、グラフの頂点において、異なる型の、複数の入力および複数の出力を扱うことができることです。これにより、多くのアプリケーションにおいては、アルゴリズムから実装までのマッピングをシンプルに行うことが可能になります。
Dryadのほうが柔軟な処理が可能で、MapReduceを包含する特徴を備えているとのこと。
そのDryadにおけるJobの構造を示した図を以下に引用します。MapReduceに似ていることが分かります。
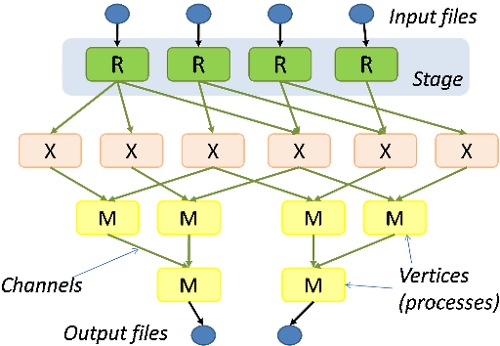
説明も引用しましょう。
Dryad を使用するプログラマは、いくつかのシーケンシャル(逐次)なプログラムをコーディングし、またそれらを一方向(one-way)チャネルで接続 (connect)します。 (Dryadにおける)計算は有効グラフとして構造化されます。つまり、プログラムは各グラフの頂点(vertex)となり、一方で、チャンネルはグラフの辺(edge)となります。Dryad の Job はグラフ ジェネレーターであり、それによりどのような有向非循環グラフ(directed acyclic graph)であっても統合的に扱うことが可能になります。
日経コンピュータの解説によると、DryadはC#やLINQなどを用いてプログラミングするとのことです。
現在Dryadはマイクロソフトのオンライン広告プラットフォームであるAdCenterでのログ処理で実際に使われているほか、アカデミック向けの公開が行われています。
Hadoopは主にビジネスインテリジェンスのための分析プラットフォームとして着々と実用化が進んでいます。DryadがWindows Azureのサービスとして、あるいは何か別の形で登場する日はいつになるのでしょうか。
あわせて読みたい
Facebook、memcachedに300TB以上のライブデータを置く大規模運用の内側
≪前の記事
Amazon.com、社内システムをクラウドへ移行中。オンプレミスからクラウド移行へのケーススタディ

