
コンピュータサイエンス史上最大の課題「並列処理による性能向上」~情報処理学会創立50周年記念全国大会の招待講演
「いま、並列処理の壁というコンピュータサイエンス史上最大の課題に直面しています。しかしこれはチャンスでもあります。新しい時代を切り開いていきましょう」。IBM名誉フェローのFran Allen氏は、昨日3月10日に行われた日本の情報処理学会創立50周年記念全国大会の招待講演の演壇からこんなメッセージを聴衆に投げかけました。
Fran Allen氏は、コンパイラやプログラミング言語が専門で、女性で初めてチューリング賞を受賞した人。今回の招待講演のためにわざわざ来日したと紹介されました。
講演のタイトルは「The Challenge of the Multicores」。ここからは、Allen氏の講演の内容を紹介しましょう。
(この講演は英語で行われたものです。内容にはできるだけ正確を期したつもりですが、理解不足のところや聞き取れなかったところもありました。もし誤解や不正確なところがありましたら、コメント欄などでご指摘ください)。
東京大学 安田講堂で行われた招待講演の内容
 情報処理学会創立50周年記念全国大会の招待講演は、東京大学 安田講堂で行われた
情報処理学会創立50周年記念全国大会の招待講演は、東京大学 安田講堂で行われた「The Challenge of the Multicores」。なぜチャレンジなのか? それは現在、コンピュータの性能が1つのリミットに達しているためです。これまで予想していなかった変化に直面しています。スタンフォード大学学長のJohn Hennesyの言葉を借りれば、「コンピュータサイエンス史上最大の問題に直面している」ということになります。

これまでのコンピュータのピーク性能を示したグラフを見てみましょう。
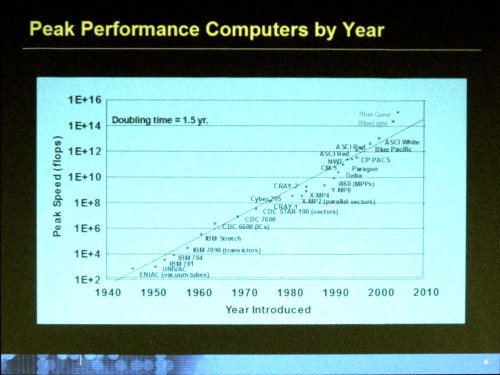
これらのコンピュータは、グランドチャレンジと呼ばれる課題に利用されてきました。社会や環境といったものが抱える大きな問題を解くために使われてきたのです。
IBM Stretchマシンは、NSA(米国家安全保障局)が冷戦時代に暗号解読に使っていました。当時、そうした仕事が最先端のコンピュータの役割だったのです。その後に登場したASCI Red、ASCI Whiteといったコンピュータは、ロスアラモス研究所で核爆発のモデルを計算していました。爆発がどのように構成されているのか、コンピュータの役割は実際の実験をシミュレーションに置き換えるためのものでした。そしてBlueGneneは、タンパク質や遺伝子などの構造を研究するために使われました。
こうしてコンピュータのピーク性能は長年のあいだつねにひとつのパターンを構成してきました。それはつまり、14カ月から18カ月ごとに性能が2倍になる、というムーアの法則にのっとった性能の向上です。
そしてこれからペタフロップ(PetaFlop=1015Flop)性能の時代へと入ろうとしています。

1ペタフロップの理想的な構成はこのようになるのですが、問題は、トランジスタが小さくなり、チップ上にたくさん乗るようになり、それが高速になるにつれて、チップの熱が高くなりすぎることです。

そして2002年ごろから、トランジスタの性能とプロセッサの性能にギャップが生じ始めました。プロセッサの性能を向上させるのには、新しいテクノロジを使わなくてはならなくなったのです。
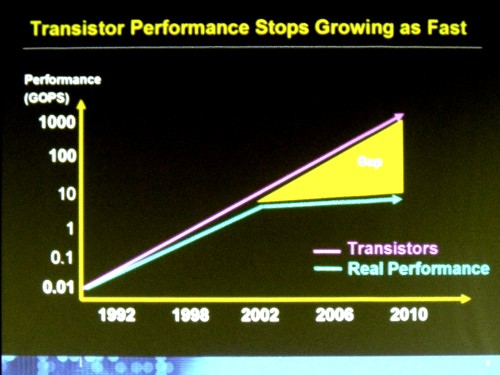
それを解決するために、シンプルで遅くて熱を出さないプロセッサをマルチコアにしてチップに乗せることになります。

こうしたチップを使って性能を向上させるために、私たちは並列化へと向かわなければなりません。並列化が性能向上を提供するという時代に入ったのです。
もちろん、これまでも性能向上のために並列化は取り入れられてきました。パイプライン、ブランチ予測といった技術をハードウェアレベルで用いてきました。並列化をチップの内部で行ってきました。しかしそれではもう不十分です。ソフトウェア自身が並列化されなければなりません。
しかし現在のソフトウェアは、ここで必要とされるような並列化を提供していません。性能を向上するにはソフトウェアの並列化に向かわなければなりませんが、それは提供できていない。これが現在のジレンマです。
ハードウェアレベルでは、今後10年から12年後にはチップに15ビリオン(150億。ちなみに現在のインテル Core i7プロセッサでトランジスタ数は7億~8億)のトランジスタが乗ることが現実となります。Intel、AMD、IBMといったどのメジャーなチップベンダもそう考えているのです。

このときのコンピュータアーキテクチャはどのようなもので、こうした新しい並列化のためのコードをユーザーは書くことができるのでしょうか? どうすれば15ビリオンのトランジスタが乗っているチップを、私たちは使いこなすことができるのでしょうか?
そして、自動並列化コンパイラはこうした問題を解決するパラレルパフォーマンスを提供できるのでしょうか?
私はこの問題に関してもっとも多くの時間を費やしてきましたが、残念なことにそれはとてもとても難しい問題です。
なぜでしょうか。とりわけ言語に課題があると考えています。現在プログラミングによく使われているCやC++、Javaといった言語はハードウェアに近いものであり、言語としてローレベルです。これらのプログラムを分析しても、アプリケーションが本当はどのような問題を解決しようとしているのかを知ることはできません。
しかしプログラミング言語には、高いレベルの言語、用途特化型の言語(DSL:Domain Specific Language)といったものが、コンピュータサイエンスが始まる前の1960年代からLispのような関数型言語やAlgol60、APLといったものがありました。それらは、人間がどのような問題を解こうとしているのか表現することを可能にします。そしてそれをコンパイラがハードウェアレベルに分析することは可能だと思います。

問題を正しく解く可能性はあるでしょう。並列処理を前進させるためにやることはたくさんあります。まとめると次の3つではないかと考えています。
- 自動パラレリズムとオプティマイゼーション
- 高レベルの用途特化型言語(DSL)
- C、Javaのような汎用言語を排除する
そして、まだ触れていないのが、オートマチックでダイナミックなデータローカリティの最適化、移動、組織化、保有といったことです。どのような方法でデータをオーガナイズし、ストレージに格納し、素早く操作するか。
一般にアーキテクチャは、計算ユニットとデータストア、この2つのあいだにあるバンド幅、レイテンシといったものを解決するためにあります。そしてここにパフォーマンスのバリアがあるのです。マシンの性能をより向上させていくには、こうしたバリアを乗り越えていくことが必要です。そしてこうしたバリアを乗り越えるためにキャッシュなどのデータをやりとりをするために多くの資源がつぎ込まれていきました。
計算ユニットをもっとストレージの中に分散して入れていく、というモデルがあるのかもしれません。
そして性能向上のための並列処理はこれ以上ハードウェアではできないのです。この道具をどう使うのか、それはソフトウェアにまかせられているのです。

最後に、この講義に非常に関連しているニュースを紹介しましょう。大規模なデータ処理をマルチコアで走らせた場合にどうなるか、という最新の研究です。
これによると、16コア以上ではスピードが減少するというのです。そしてこうしたマルチコアのCPUは市場に登場します。

これを解決するための答えは私にはありません。おそらくマルチコア時代にのこの問題を解決するには、デザインを見直し、アルゴリズムを再考する必要があるのでしょう。
もういちど、John Hennessyの言葉を引用しましょう。いま、コンピュータサイエンスがこれまで直面してきた中で最大の課題が目の前にあります。
しかしこれは、非常に大きなチャンスでもあります。過去50年で学んだ経験や知識、アイデアを放り投げて、大胆に考え、動くべきです。

そしていい知らせもしておきます。IBMの社長だったT J Watson, Srの言葉です。成功するには失敗を2倍にすればいい、という言葉です。ぜひチャレンジしてください、失敗を恐れずに大胆に、大きなリスクをとってください。

そして、コンピュータとコンピュータサイエンスにとっての新しい時代を切り開いていきましょう。


