
Apache Spark 2.0正式版がリリース。ANSI SQL標準サポート、10倍以上の高速化など
2016年7月28日
分散処理フレームワークの「Apache Spark 2.0」正式版のリリースが、開発元のDatabricksから発表されました。これまでApache Sparkはバージョン1.x(直前の最新版は1.6)でしたので、メジャーバージョンアップとなります。
Spark 2.0で最大の新機能は、新しいSQLパーサーを採用したことによるANSI SQL(SQL 2003)への対応です。ビッグデータのベンチマークの1つであるTPC-DSの99種類のクエリがそのまま実行可能と説明されており、プログラマが慣れ親しんだ一般的なSQL文はすべて実行可能になります。
また、DataFrameとDatasetは統合されたAPIとなりました。
こうしたAPIの変更や改善が行われた一方で、Spark 2.0ではパフォーマンスも大きく改善されています。
Spark 2.0では前バージョンと比べて10倍の速度向上を目論んでおり、それはバージョン1.5から導入された実行エンジンのTungstenを、モダンコンパイラとMPP(大規模並列処理)の技術を用いてさらに改善することなどにより実現したとのこと。
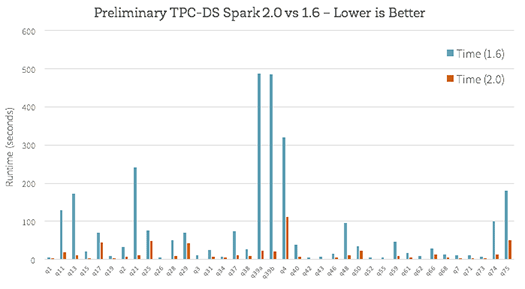
Databricksのブログで紹介されたTPC-DSのベンチマークの比較では、Spark 2.0 は前バージョンのSpark 1.6よりも大幅な性能向上が見てとれます。
関連記事
- Spark 2.0はフロントエンドAPIの創設と10倍の性能向上を目指す。早くも今年の5月頃登場予定。Hadoop Spark Conference Japan 2016
- 大規模分散データ処理フレームワーク「Apache Spark 1.6」正式リリース。メモリコンフィグレーションの自動化、静的型付けのDataset API、速度の向上も実現
- Apache Sparkがスループットとレイテンシを両立させた仕組みと最新動向を、SparkコミッタとなったNTTデータ猿田氏に聞いた(前編)
- Apache Sparkがスループットとレイテンシを両立させた仕組みと最新動向を、SparkコミッタとなったNTTデータ猿田氏に聞いた(後編)
あわせて読みたい
≫次の記事
今後5年における企業のデータセンター投資は抑制傾向。データセンター事業者のデータセンター投資は増加傾向。IDC Japan
≪前の記事
システムにいま何が起きているのか、どんなログでも読み込んで可視化するツール「Splunk」。新しいシステム運用とセキュリティ対策を実現するシスコ製品群との連携[PR]
今後5年における企業のデータセンター投資は抑制傾向。データセンター事業者のデータセンター投資は増加傾向。IDC Japan
≪前の記事
システムにいま何が起きているのか、どんなログでも読み込んで可視化するツール「Splunk」。新しいシステム運用とセキュリティ対策を実現するシスコ製品群との連携[PR]

