
Apache Sparkがスループットとレイテンシを両立させた仕組みと最新動向を、SparkコミッタとなったNTTデータ猿田氏に聞いた(後編)
最近ビッグデータ処理基盤として急速に注目を集めているのが「Apache Spark」です。
Sparkは、Hadoopと比較されることも多く、Hadoopよりも高速かつ高機能な分散処理基盤だと言われています。Sparkとはいったい、どのようなソフトウェアなのでしょうか? 今年6月にSparkのコミッタに就任したNTTデータの猿田浩輔氏に聞きました。
(本記事は「Apache Sparkがスループットとレイテンシを両立させた仕組みと最新動向を、SparkコミッタとなったNTTデータ猿田氏に聞いた(前編)」の続きです。
Spark内部の動作が可視化
最新のSpark 1.4では、大きな機能追加が3つあります。
1つは、R言語でSparkを用いた処理が書ける「SparkR」です。これもDataFrame APIが呼び出され、オプティマイザが走ります。
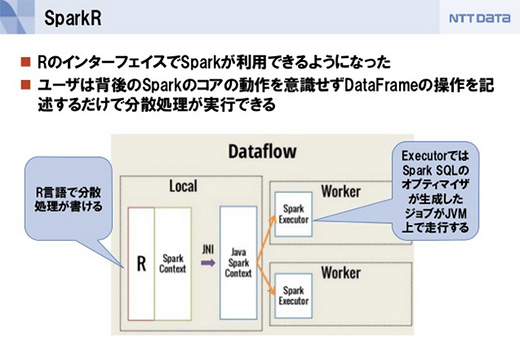 スライド「メキメキ開発の進む Apache Sparkのいまとこれから」から
スライド「メキメキ開発の進む Apache Sparkのいまとこれから」からまた、Spark内部の可視化が強化されました。Spark Streamingの統計情報の可視化によって単位時間あたりのデータの流量や処理のスループットが確認できますし、RDDの変換過程が可視化されたことでオプティマイザが入った変換や複雑なRDDの変換チェインの全体像が把握しやすくなり、ボトルネックなどが発見しやすくなっています。
各ジョブの開始、終了、タスクが割り当てられた時間や各タスクの実行時間、処理時間の内訳なども確認できます。例えばスレーブサーバが落ちたときにワーカーが何をしていたか、遅延がやたら大きいスレーブサーバがあるかどうか、特定のスレーブサーバに処理が集中していないか、といったことが分かります。すばやくトラブルシュートできるようになります。
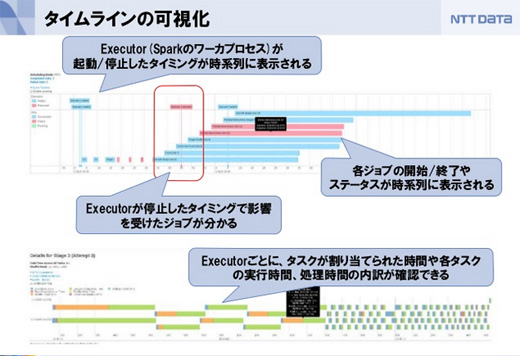 スライド「メキメキ開発の進む Apache Sparkのいまとこれから」から
スライド「メキメキ開発の進む Apache Sparkのいまとこれから」から「Project Tungsten」というプロジェクトが始まっていて、これはSparkの処理におけるCPUの利用効率を高めようというものです。SparkはJavaVMの上で動いているので、Javaのガベージコレクションの影響を受けます。そこでSparkに適した自前のメモリ管理によってガベージコレクションを削減したり、独自のデータ構造を持つことで無駄な中間オブジェクトの生成を省略することで効率をあげようとしています。
すでに最新のSpark 1.4で一部取り込まれています。
なぜNTTデータがSparkに取り組んでいるのか?
Sparkの説明をしていただいた猿田氏に、Sparkコミッタになった経緯と本業について聞きました。
──── 猿田さんのお話を伺う前に、NTTデータがSparkに注力している理由について教えてください。
猿田氏 Hadoopをお使いのお客様が増えてきて、しかも複雑な多段ジョブの実現が課題になってきた例もちらほらでてきました。
そこを解決する手段の1つがSparkで、1年ほど前に検証を開始し、いまでは弊社と商用テクニカルサポートの契約を結んでいるお客様もいらっしゃいます。
そうした商用サポートの提供を会社として実現していくときに、発生する課題を解決できる実力を持つ必要があります。それが私がSparkのコミュニティに積極的に参加している理由で、そこでいろんな課題を実際にパッチなどの提供で解決していくうちにコミッタとして認められた、というところです。
パッチを提供しているのは私以外にも社内にいますので、Sparkの最新版のリリースノートにはNTTデータの社員が何人か載っています。
──── 今回猿田さんが就任されたSparkのコミッタとはどんな役割を持つのですか?
猿田氏 コミッタとは、Spark本体のソースコードに直接変更を加える権限を持つ人のことです。
──── 猿田さんがコミッタになった経緯は?
猿田氏 私が本格的にSparkにコミュニティに参加して1年くらいですね。
もともとは分散処理のデバッグがとても難しくて、Sparkでそこを改善できないかということでパッチを投げたりしていました。実は、さきほど説明したタイムラインの可視化は私が開発を主導していました。
例えばお客様のところで分散処理に問題が発生すると、「このログはこのスレーブサーバので、あのログは別のスレーブサーバので……」と、スレーブサーバごとに何が起きたのかを分析するためにそれぞれのログを見なくてはいけませんでした。
それをもっとやりやすくできないかなと思っていたのです。
そこでSparkが出てきたときに、確実にこういう可視化ツールが必要になるだろうということで、議論しながら方向性を決めて開発を進めていったということですね。
──── 猿田さんのNTTデータにおける本業は何ですか?
猿田氏 SparkやHadoop及び関連するエコシステムの技術検証や、お客様のシステムへの導入支援とテクニカルサポートということになります。
サポート業務はリソースに余裕のある場合もあれば、まとめてどっと問い合わせがくることもあります。ですので基本的にはサポートの仕事を優先し、そこで発生した課題などを基に、空いた時間でコードを書いたり議論をしたりしています。
また、定期的に西海岸に1カ月ほど滞在していて、滞在中は日本にいるときよりもコードを書いています。加えて地の利を生かし、シリコンバレーエリアのエンジニアたちと直接議論などを行なったり、現地のイベントに参加して情報収集を行っています。
──── 開発者ではなくテクニカルサポートの人が直接コードを見て対応できるというのは非常に興味深い体制ですね。本日はありがとうございました。
あわせて読みたい
米GEが「Predix Cloud」でクラウド市場へ参入を発表。Cloud Foundryを基盤に、航空、エネルギー、医療などで発生する大規模データをリアルタイム分析
≪前の記事
Apache Sparkがスループットとレイテンシを両立させた仕組みと最新動向を、SparkコミッタとなったNTTデータ猿田氏に聞いた(前編)

