
オープンソースのバルクデータローダー「Embulk」登場。fluentdのバッチ版、トレジャーデータが支援
何ギガバイトもあるCSVをデータベースに読み込ませるようなバルクデータをバッチ処理するためのツール「Embulk」がオープンソースで公開されました。
コミッターとして開発しているのは、ログ収集ツールとして知られるfluentdなどの開発者として知られる古橋貞之氏、西澤無我氏、中村浩士氏らで、3人が所属するTreasure Dataも開発を支援しています。
古橋氏はEmbulkについて「簡単に言うとfluentdのバッチ版です」と説明。1月27日に行われた「データ転送ミドルウェア勉強会」で、Embulkの紹介を行いました。
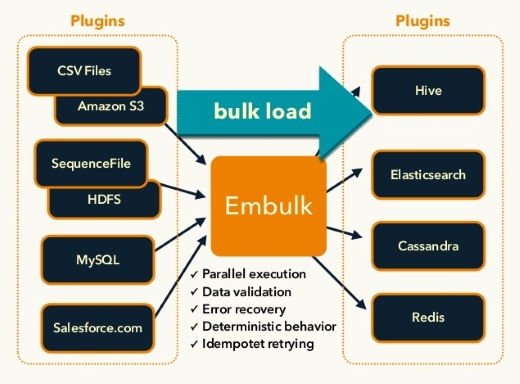
Embulkはプラグインベースのバルクデータローダー

古橋氏はまず、例えばCSVファイルをPostgreSQLに読み込ませようとすると、CSVの日付のフォーマットがPostgreSQLの想定しているフォーマットと違っていたり、Null値の表現が違っていたりして失敗して、データ変換のためのアドホックなスクリプトを何度も書くことになると、現状のバルクデータのロードが簡単でないことを紹介。
しかもこうした作業はXMLやJSONや各種ログフォーマットなどデータの種類が増えるごとに発生し、またロード先がPostgreSQLからMongoDBやAmazon RedShiftなど増えることでも同様に発生すると指摘。さらにデータの二重ロードやエラーの際のハンドリング、リトライ、大規模なロード時の性能最適化など、バルクロードのデータには数々の課題があることを示しました。

こうした課題を解決するために開発されたのが「Embulk」です。
「Embulkはプラグインベースのバルクデータローダー。プラグインで、あたらしいデータフォーマットやデータソースに対応できるし、これをオープソースにすることで再利用できる」(古橋氏)
Embulkのプラグインは階層構造になっており、インプット側は入力に対応する「FileInputPlugin」、gzipのデコードなどに対応する「DecoderPlugin」、そしてデータをパースする「ParserPlugin」の3層。そして実行部分も「Executor Plugin」になっており、例えばHadoopに対応したプラグインを書くと、MapReduce上で並列処理として実行できる、といった構造になっています。
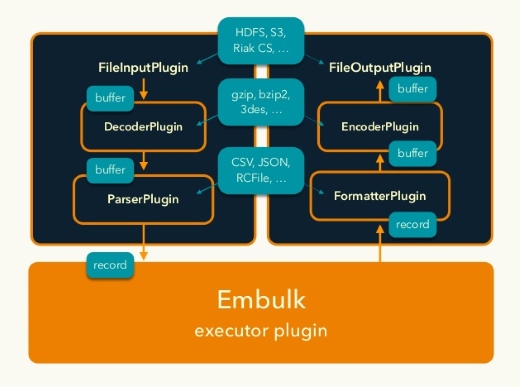
「プラグインを役割分担することで、それぞれをシンプルで再利用しやすくなる。例えばファイルフォーマットはそのままで入力はAmazon S3に対応するとか」(古橋氏)
古橋氏はEmbulk紹介の冒頭で「これがfluentd以上にはやってくれると嬉しいです」と切り出しています。実際に、fluentdのようにリアルタイムでログを収集する場面よりも、大規模なデータファイルをアプリケーションやデータベースにバッチ処理で読み込ませる場面の方が十分多いと思われます。Embulkのプラグインやエコシステムが充実していけば、fluentdよりも普及する可能性はかなり高いのではないでしょうか。
あわせて読みたい
YouTubeがHTML5のVideoタグをデフォルトにしたと表明、従来のFlashに代わり
≪前の記事
日本HP、Xeonプロセッサを採用した無停止サーバ「HP Integrity NonStop X」発表

