
HadoopのSQL対応分散クエリエンジン「Cloudera Impala」。Clouderaがオープンソースで公開
Hadoopのディストリビューションベンダとして知られるClouderaは10月25日、SQLに対応し、データの分析速度はMapReduceよりも何倍も高速だという新しい分散クエリエンジン「Cloudera Impala」(製品名「Cloudera Enterprise RTQ」)をオープンソースで公開しました。
これまでHadoopでは内部でMapReduceと呼ばれる処理が用いられていましたが、ImpalaではMapReduceを使わず、Clouderaが2年かけて開発した独自の分散クエリエンジンを用いて処理を行います。Hiveの上位互換のSQLが利用でき、Hive/MapReduceで数分かかっていた応答時間を数秒に短縮すると説明されています。
グーグルのDremel論文が発端
グーグルが大規模分散処理フレームワークであるMapReduceに関する論文を発表したことがHadoop開発のきっかけになったように、今回のImpalaの開発もグーグルの大規模分散クエリに関するDremel論文に触発されたものだとClouderaは明らかにしています。
Dremelは、現在グーグルのBigQueryと呼ばれるサービスです。Dremel/BigQueryはSQLに対応したカラム型データベースを大規模分散処理で実現しており、OLAP(Online Analytical Processing)やデータマイニングといったデータ分析処理を超高速に実行できます。
Impalaも基本的には並列分散クエリエンジンを用いた同様のアーキテクチャを実現しています。MapReduceよりも高速なのは、こうしたクエリ処理に関する性能を比較した場合でしょう。
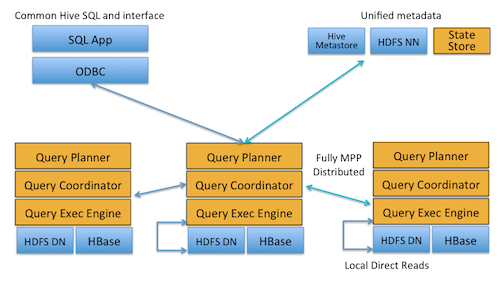 Cloudera Impalaのアーキテクチャ(「Cloudera Impala:Apache Hadoopで実現する、リアルのためのリアルタイムクエリ」から引用)
Cloudera Impalaのアーキテクチャ(「Cloudera Impala:Apache Hadoopで実現する、リアルのためのリアルタイムクエリ」から引用)Impalaの分散クエリエンジンとMapReduceとはそれぞれ得意な処理が異なるため、Impalaが従来のMapReduceの後継となる、あるいは置き換えるということはなく、共存していくものと考えられます。
またClouderaはCloudera Impala/Cloudera Enterprise RTQを「リアルタイムクエリ」と説明していますが、技術的特徴を考えればその本質はリアルタイム処理というよりも、高速に分析結果をはじきだせる反応速度の短いバッチ処理といえるでしょう。
Dremelのオープンソース実装はApacheでも
グーグルのDremelに触発されたのはClouderaだけではありません。すでにDremelのオープンソース実装としてApache Drillが進められています。
また、カラム型データベースはそもそも並列処理と相性が良いため、オラクルやSAPに買収されたサイベースなど以前から商用データベースベンダーから製品が出ており、特にビッグデータのブームによってカラム型データベースの技術の注目度が高まっていることから、今後さらに改良された製品が登場することでしょう。
ClouderaがCloudera Impalaを公開したことは、Hadoop/MapReduceで処理できる範囲にとどまることなく、ビッグデータにおいて商用データベースベンダーと競合する分野にも積極的に進出していくのだ、という意志の表れだと見ることができます。
あわせて読みたい
Amazonクラウド、ストレージ障害は潜在バグからメモリリーク発生が原因。きっかけはDNSの変更
≪前の記事
連載マンガ Mr. Admin:Excelができるからって、仕事ができるわけじゃなし

