
YARNの登場によりHadoopは複数の並列分散処理エンジンを併用できる環境へ。Hadoop Conference Japan 2014
Hadoopに関する国内最大のイベント、「Hadoop Conference Japan 2014」が7月8日に都内で開催されました。
今回のイベントのとりまとめ役でもある日本Hadoopユーザー会 濱野賢一朗氏は、基調講演の1つとしてHadoopがこれからどう進化しようとしているのか、「Hadoopを取り巻く環境」と題して現状をまとめています。講演内容のダイジェストを紹介します。
Hadoopがきっかけで並列分散システムが普及した
日本Hadoopユーザー会 濱野賢一朗氏。

今回の参加登録者数は1296名。アンケートによると約65%がはじめて参加される方で、これはかなり驚きました。このイベントの参加人数が大きく増えたわけではありませんが、裾野が広がっているなと、喜ばしく思います。

Hadoopの概況を振り返ってみたいと思います。Hadoopは大きく見ればたぶん、はじめて並列分散システムが普通に使われるようになった、多くの人が使うようになったきっかけだったと思います。
Hadoopのどこがよかったのか、その1つはたぶん、データ読み込みのスループットを最大化するシンプルなアーキテクチャを考えたところだったと思います。
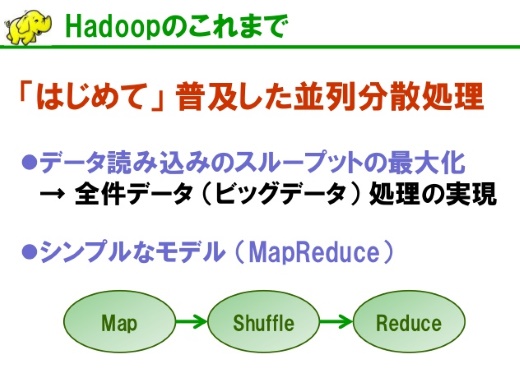
ある程度大きなボリュームのデータを、とくに全件を見なければならないときにそのデータをいかに読んでくるか。ディスクやサーバを並べて処理することで、1台のスループット掛ける台数分のスループットが出るというスケーラビリティを備えている。そういうシステムをミドルウェアとして届けてくれた。
もう1つは、並列分散処理には難しいことがいっぱいあります。途中で処理が失敗したらどうするか、大きいジョブをどうやってタスクに分割し、結果をまとめるのか。
Hadoopのモデルは非常にシンプルで、MapReduceに従って処理を書けば、並列分散処理で自動的に実行される。故障が起きても自動的にミドルウェアが対応するし、大きな処理を細かく分割することも、処理結果をまとめることもすべてフレームワーク、ミドルウェアがやってくれる。
そういうシンプルだけど非常に力強いフレームワークだったことが、これまでのHadoopを支えてきたものだったと考えています。
これからのHadoopがリードする世界とは
いま、Hadoopのバージョンや機能がどうなっているのか、全体感を皆さんは把握されているでしょうか。ちょっとまとめたのですが、こんな感じです。
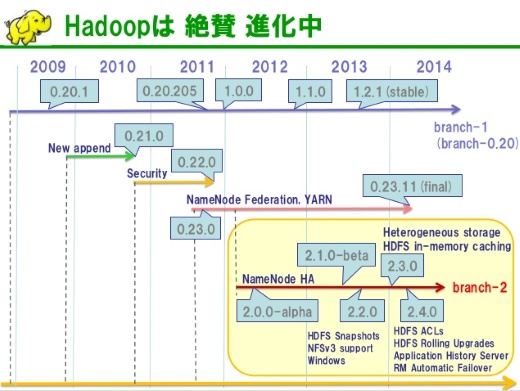
前回のカンファレンスでもHadoopを取り巻く状況は難解だと言っていたのですが、さらに複雑化していましてバージョンの系統が結構いっぱいある。
みなさんがたぶんいちばん多く使っているのが、0.20系と言われているところ。そのあと0.21系、0.22系、0.23系に続いて、2.x系の「branch-2」と呼ばれている流れがあります。このようにさまざまなバージョンが出ています。
いま、多くのディストリビューションはバージョン2.3や2.4を中心に実装されようとしていて、これからみなさんが使うものの多くはそれになると思います。
このバージョン2.3、2.4に向けてセキュリティを高めるもの、ファイルシステムの機能を向上させるものなど、いろんな機能がどんどん開発されています。
なかでもいちばん大きな動きは、たぶんみなさんピンとくると思いますが。これです。

大きな変化であるYARNが、だんだんHadoopの真ん中に座ってきている、そういう状況にあります。これまでMapReduceだけを動かすフレームワークとしてのHadoopが、MapReduce以外のアルゴリズムも動かしていこうと、そういう流れてなってきています。
今回、このイベントではこの点を重視してプログラムを組んでいます。
YARNの登場は何を意味しているかというと、これまでMapReduceを使っていていくつか課題に感じるところもあったかと思います。もちろんMapReduceにはよさもあって、安定的に手堅く動いてくれるのですが、1台のコンピュータに大きなメモリが乗って、ノード間の高速な通信もリーズナブルになってきたいま、MapReduce以外の仕組みも動かせる、そういう状況になってきています。

ニュースなどでは「MapReduceの時代は終わった」と書かれることがありますが、MapReduceは手堅くみなさんに使われていくと思います。
Hadoopの世界でMapReduceだけでなく、それ以外のフレームワークやミドルウェアが課題を解決できる可能性を開いていく、というのがこれから見えてくる世界かなと思います。
Hiveの利用が圧倒的に多く、ImpalaやSparkも
今回の参加者のみなさんに、主に今日のセッションで登場するキーワードのソフトウェアをどれくらい使っているのかを聞いてみました。
約半数の方がHiveをお使いで、また結構な数の方々がZookeeper、HBaseをお使いです。
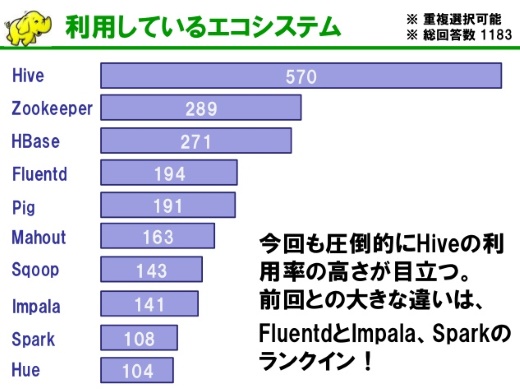
新しく登場したのは、Fluentd、MapReduce以外の並列処理の代表格と言っていいImpalaやSparkといったものも入ってきて、みなさんの利用の変化が見て取れる結果となりました。
公開されているスライド。
あわせて読みたい
HadoopはいずれOLTPも実現し、エンタープライズデータハブとなる。Hadoop Conference Japan 2014
≪前の記事
[速報]「Amazon Cognito」発表。モバイルとクラウドのデータ同期機能を提供、オフラインモバイルアプリを実現

