
クックパッドのデプロイとオートスケール、1日10回デプロイする大規模サイトの裏側(前編)。JAWS DAYS 2014
大規模なオンラインサービスを支えるためのオートスケールと、サービスをすばやく進化させていくための迅速なデプロイ。クックパッドはこの2つをクラウド技術の組み合わせによって両立させています。
同社のインフラ責任者である成田氏がその仕組みやルールを、Amazonクラウドのユーザーコミュニティ主催のイベントJAWS DAYS 2014で解説しました。
本記事では、その講演内容をダイジェストで紹介します。
クックパッドのデプロイとオートスケール
クックパッド インフラストラクチャー部長 成田一生氏。

クックパッドは昔はデータセンターを持っていましたが、2011年にAWSの東京リージョンができたのをきっかけに、AWSに全部サーバを移行しました。
クックパッドの規模は、1月のデータだと160万レシピ、これはChefのレシピじゃありません(笑)。料理のレシピが160万です。月間ユニークブラウザが4100万、有料会員が120万人くらいいらっしゃる、という規模のサービスです。

AWSの方の数字を見てみるとこんな感じです。EC2インスタンスが700くらい、これはオートスケールをやっているので多い時間帯でこのくらい、少ない時間帯で五百数十台。ELBも便利に使っていて、だいたい50くらい。

最近はRedshiftも便利に使っています。tabemiru.comという食品業界向けに出しているBIツールがありまして、クックパッドのレシピを利用者が検索した履歴を分析して、この季節にはこんなレシピが人気ですよ、といった情報を見やすく提供するものです。
社内の開発者は、インフラエンジニアが僕を含めて5人。開発者は60人くらいで、この人たちが1日10回はデプロイしているという状況です。Amazon.comは1時間に1000回くらいデプロイしているそうなので、それから較べると1日にたった10回ですが、この人数でみんなが1日10回デプロイするのはけっこう工夫が必要です。

デプロイは開発者自身の責任でやる
デプロイについて見ていきましょう。
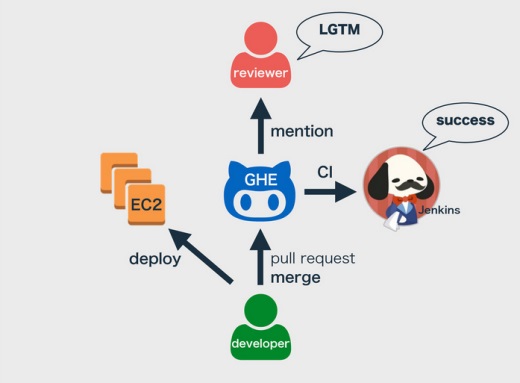
クックパッドでは、GitHub Enterprise(GHE)でアプリのコードからPuppetまで管理しています。開発者がコードを書いたらGHEにプルリクエストを送るとレビュアーにメンションが飛ぶので、レビューを受け取ってオッケーだよと、Looks Good To Meとしたら、開発者がプルリクをマージします。
マージするのはプルリクを出した本人です。プルリクした人にコードの責任を持ってほしいという意味で、そうしています。
マージしたらJenkinsでContinous Integratin(CI)が走って、CIが通ったらデプロイを開発者自身が行います。これも開発者がビルドの責任をもってほしいからです。
デプロイはルールを決めてやっています。
営業時間しかデプロイをしないのは、営業時間外だと問題が起きたとき気付ける人が少ないからです。ここには書いていませんが、開発者はデプロイしてから1時間は帰っちゃいけない、みたいなルールもあります。

imonはインフラモニターの略で僕が作ったツールなのですが、数秒単位でインフラの状況が見られます。デプロイした後はこれを開発者はじっと見て、エラーをチェックして例外を追いかけるとか、そういうことをしています。

タグを用いたサービスの自律的動作
サーバプロビジョニングの話。
昔はサーバ台数が有限だったので、サーバ管理台帳を作ったりして1台ずつデータを打ち込んで管理していましたが、Amazon EC2になってオートスケールさせたりサーバを増やしまくっているとサーバ管理台帳では運用できなくなります。そこで最近はサービスディスカバリということに取り組んでいます。

サービスでは、サーバ自身が自律協調的に動いて、ああ自分と同じグループにDBが追加されたなといったことをサーバ自身が知って、自分の設定を変更していく、といったことを実現するのがImmutable Infrastructure界隈の流行です。そのための仕組みとしてSerfやZookeeperとか、いろいろあります。
僕らはそういうミドルウェアを使わず、Amazon EC2のタグを使っています。タグはキーとバリューのペアをサーバに設定できるというもので、それに意味を持たせてサーバの属性や状態をタグとして記述することで、そのサーバで動いているプログラムが、自分自身やほかのサーバのタグを見て自律的に動くようにしています。
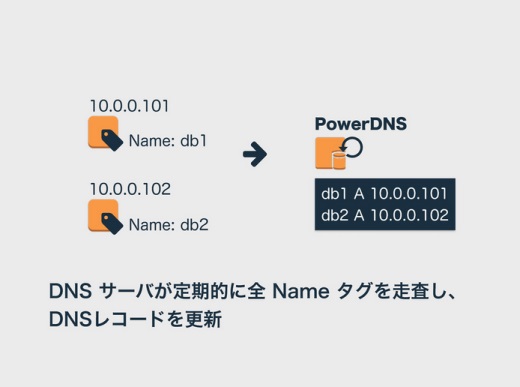
例えば僕らはNameタグの値がそのサーバ固有のホスト名になるようにしています。どうやっているかというと、このサーバのNameタグにdb1、もう1つのサーバのNameタグにdb2という値を設定したとします。
僕らはDNSのバックエンドにRDBMSを使えるPowerDNSというのを使っていて、ここにcronを仕込んで定期的にNameタグの一覧を取ってきてデータベースの内容を更新するようにしています。そうすると、Nameタグの値に応じたレコードが追加されます。
つまり、Amazon EC2のインスタンスにNameタグで名前を付けて放っておくと、そのホスト名でサーバにアクセスできる仕組みです。これ、けっこう便利です。
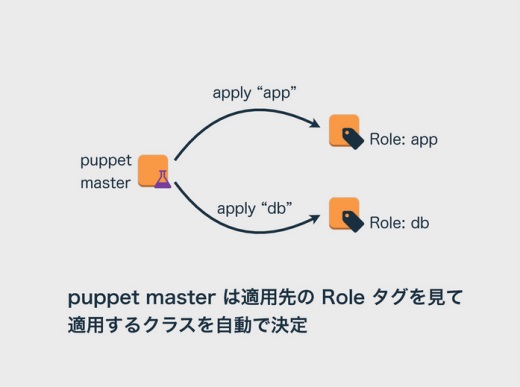
Roleタグは重要なタグの1つで、インスタンスの役割を記述しています。Roleタグにappと書くとそのインスタンスはアプリケーションサーバになり、dbと書くとデータベースサーバになります。
僕らはPuppetを使っているのですが、Puppet masterがこのRoleタグに従ってインスタンスにクラスを適用するようになっています。
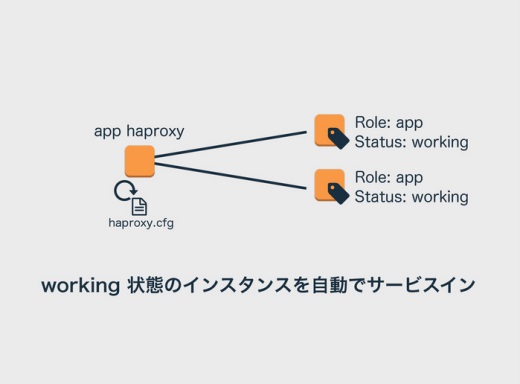
Statusタグは、そのインスタンスをロードバランサーに追加してサービスインしていい、ということを示すためのタグです。workingの値でサービスインとなります。
ここでもタグを見てHAProxyの設定ファイルが更新されるようにcronを仕込んでいます。
あわせて読みたい
クックパッドのデプロイとオートスケール、1日10回デプロイする大規模サイトの裏側(後編)。JAWS DAYS 2014
≪前の記事
[速報]Java 8が正式公開。ラムダ式、新しい日時API、JavaFX8など。NetBeans 8.0も登場

