
SSD専用に設計された「ReThinkDB」、ロックもログも使わない新しいリレーショナルデータベースのアーキテクチャ
SSDがHDDに代わるストレージとして普及しようとしていることを背景に、SSDに特化したまったく新しいアーキテクチャを備えたリレーショナルデータベースを開発しようとしている企業があります。「ReThinkDB」です。
昨年7月に、PublickeyではReThinkDBの概要を記事「SSDに最適化したデータベース「RethinkDB」、ロックもログも使わずにトランザクション実現」で伝えました。
その記事の中では、ReThinkDBがロックを使わずにトランザクションを実現し、データベース利用中でもスナップショットがとれ、また異常終了しても容易に復帰できる機能を備えている、といったことを紹介しました。
4月に米サンタクララでに行われた「MySQL Conference & Expo」で、そのReThinkDBがどのようなアーキテクチャで上記の特徴を実現しようとしているのかが明らかになりました。同社のファウンダーであるSlava Akhmechet氏が行ったセッションの内容がビデオで公開されています。以下では、セッションを基に非常に興味深いそのアーキテクチャを紹介しましょう。
ReThinkDBのアーキテクチャの中身
Slava Akhmechet氏。私たちはデータベースで多くの問題を抱えているのに、データベースはそれほど進歩していないように見える。1980年代、30年前に考えられたアーキテクチャからほとんど変わっていない。

ハードウェアは大幅に進歩し、根本的に変化しているというのに。ディスクスペースは6桁も安くなり、メモリ価格も5桁安くなり、6コアのCPUさえコンシューマプロダクトになった。

過去2年でSSDは破壊的な技術になった。突然のように変化が起きたのだ。かつてグラフィックカードがゲーム市場を変えたように、これは重要な変化であり、すべてを変えると考えている。そこで、SSDに特化したデータベースのデザインをしなおそうと考えた。

SSDをデータベースに利用するだけでも大幅な性能向上が図れるだろう、では新しいアーキテクチャをSSDに載せたらどれだけ性能向上が図れるのか? そして顧客は性能がどれくらい早くなると新しい製品にスイッチしてくれるのだろうか?
性能向上は難しい。一部をオプティマイズしても全体の性能向上になるわけではないためだ。ドライブの性能やインデックスのサイズ、さまざまなトレードオフがある。

1つパラメータを変えればほかに影響する、あらゆる可能性を考慮しなければいけないので、さまざまなパラメータがあって最適な性能向上の方法を見つけるのは難しい。まるで迷路のようだ。
SSDのためにデータベースを設計するためにどこから始めればいいのか。最適化の最初のカギとは? データベース会の偉大な研究者であるJim Grayの論文から、ある言葉を引用しよう。

「アップデートを同一場所で行うのは毒リンゴだ」
つまりこれは、データベースのデータを変更するときに、ディスクの同じ場所の値を変更するのではなく、別の場所に変更を書き込むことを示している。
データベース研究者や開発者たちはこうして、アップデートのたびにディスクの異なる場所にデータを書き込んでいった。データの管理としてはこれはよい方法であるが、そうしたデータベースを使っていると、データがディスクに散らばっていき、アクセス時間がかかるようになり、データベースがどんどん遅くなる。
SSDはまったく違う。(SSDにとって)異なる場所に書き込むことはいいことである。
これがReThinkDBのテーブルのサンプルだ。「コンシステントビュー」と呼んでおり、ロックが不要になる仕組みを備えている。

点線から上が最初に用意されたデータであり、点線から下はそのデータに対するデリートやアップデートを示している。このようにデリートやアップデートは、そのテーブルに対してつねに新しいレコードとして最後に追加されていく。
そして、下からこのテーブルを読み込んでいくと、プライマリキーごとに最初に表れたデータがつねに最新の値を示しているのだ。
このアーキテクチャが、データベースのあり方を変えていく。
デリート、アップデート、クエリなど、データに対するすべての操作がテーブルの下から上に順番に行われていくため、クエリのときにロックがまったく必要ない。
また、最近のデータベースでは短いクエリと長いクエリの同時実行が問題になっているが、まったく問題なく同居できる。

異常終了でデータベースが破損したとしても、破損するのはデータの操作中だった下から数行のデータのみだ。その数行だけを取り除けば残りはすべて正常なデータとして復旧する。トランザクションログなどによる複雑な復旧手順は不要。

バックアップもファイルをコピーするだけ、データベースが動作中でもライブでバックアップがとれる。
とてもシンプルでエレガント。もちろん、MySQLにも同じ機能はあるが、ずっとエレガントに実装している。
インデックスについても追加操作のみで行う「アペンドオンリーインデックス」を用いている。
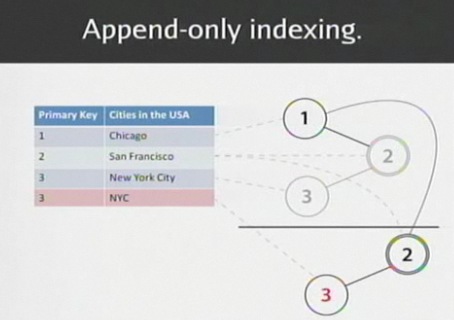
例えば、3つのノードを持つツリーに対して、3番目のノードをアップデートしたときには、ルートノード以下を全コピーしてアップデートする。こうしてつねにツリーが変更されるごとにコピーを繰り返していく。コピーの手間にたいするトレードオフとして、ツリーのガベージコレクションがなく、つねに過去のツリーが変更されることなく一貫性を保っているので、安全にファイルシステムレベルでスナップショットをとることができる。
また、データがアペンドオンリーのため、ある過去の時点を指定したクエリができるようになった。

ReThinkDBでは、データベース自身がログになっているため、ログのための別のディスクを確保する必要もない。ログを書く必要がないため書き込みが50%減少する。

しかしチャレンジもある。B-treeがちゃんと動くようにすること。毎度コピーしていたのでは膨大な量になってしまう。そこで2つ目のB-Treeは1つめ目のツリーへ仮想的にマップすることで実現しようとしている。2つ目のB-Treeは実体ではなく1つ目のツリーへのポインタにする。これでデータ量が非常に小さく高速にできる。
もう1つはキャッシュの一貫性をどう実現するかだ。複数のコアで実行したとき、あるキャッシュを更新したとき、別のキャッシュの一貫性をどう保つか?
簡単なプラグインやエレガントな方法はない。注意深く実装していくしかない。いまこうした問題の解決に取り組んでいるところだ。
新しいアーキテクチャに市場はどう反応するか?
データベース内のデータ操作を追加操作のみで実現するというアーキテクチャは、たしかにいままでのリレーショナルデータベースにはない新しいものだと思います。果たしてReThinkDBが完成して登場したときに、どれほどの性能を発揮し、また市場はどのような反応を示すのでしょうか。
以下のビデオでこのセッションの内容を見ることができます。

