
Hadoopの最新動向を「Hadoop World:NY 2009」の資料から(後編)
Hadoopは、グーグルが大規模分散システムのために用いているMapReduceという技術を、オープンソースとして実現するために開発されたJavaベースのソフトウェア。クラウド対応のアプリケーションであり、数テラバイトにもおよぶ大容量のデータを高速かつ低コストに分析する方法として注目を集めています。
後編では、10月2日にニューヨークで開催された「Hadoop World:NY 2009」の午後のセッションの資料に目を通し、興味深いポイントを紹介しましょう。午後は3トラックに分かれ30ものセッションが行われていました。
この記事は「Hadoopの最新動向を「Hadoop World:NY 2009」の資料から(前編)」の続きです。
午後のセッション資料からハイライトを紹介
イェール大学のAzza Abouzeid氏とKamil Bajda-Pawlikowski氏は、HadoopとパラレルDBについて解説。パラレルDBは構造化データを扱い、Hadoopは非構造化データが対象。問い合わせ言語や実行方法、粒度などを比較しています。
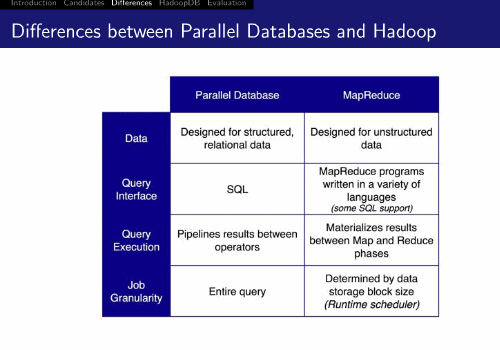
スケーラビリティはHadoopが優れるが性能はパラレルDBが勝り、結果として両方とも用途別に使い分けるべきだ、ということになったようです(参考:MapReduceとパラレルRDBでベンチマーク対決、勝者はなんとRDB! - Publickey)。

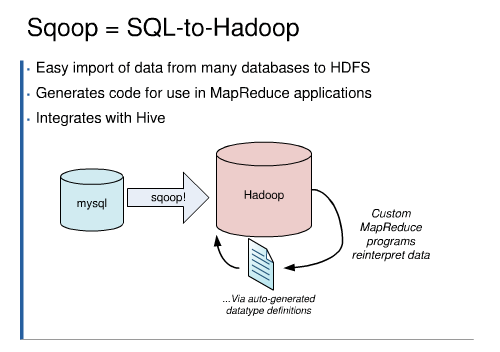
Clouderaが開発中のSqoopについて。MySQLからHadoopへのデータインポートを容易に行うためのツール。Hadoopアプリケーションのためのクラスなども自動生成してくれ、Hiveとも統合しているため、SQL的な問い合わせもそのまま利用できるとされています。

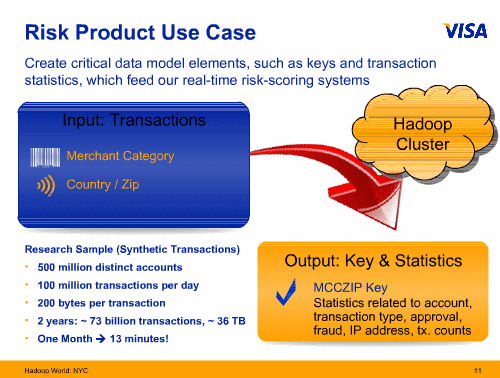
VISAによるHadoopの事例。5億アカウントの利用者から1日に1億トランザクションが発生し、トランザクションあたり200バイトのデータが生成されるという。過去2年間で730億ものトランザクションデータが生成されており、これを分析するのにこれまで1カ月かかっていたものが、13分になったと説明されています。
JP MorganがHadoopを導入した理由について。リレーショナルデータベースは酷使されており、性能をあげるにはメモリを増やす以外にない。プロプライエタリなトランザクションデータベースへ格納されるデータは増加の一途をたどっており、しかもデータは正規化されないものもある。そして、企業向けのデータは少数のベンダー製品に囚われの身となっているも同然で、プロプライエタリなものが多すぎる。もっと選択肢が必要だとの考え。

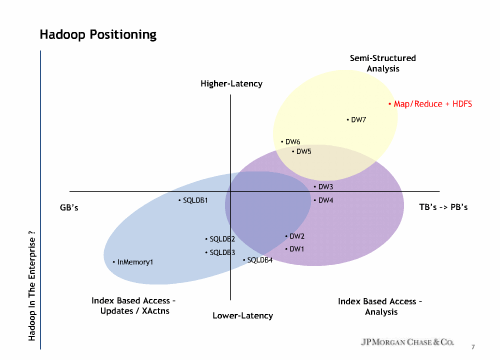
JP MorganにおけるHadoopのポジショニング。左下にはギガバイトクラスのデータを高速(Low Latency)に処理するインメモリデータベースが位置し、中央付近にはギガバイトからテラバイトのデータを処理するSQLデータベースが多数存在。その右側にはテラバイトのデータを高速に、もしくは多少の時間をかけて分析するデータウェアハウスが並び、いちばん右上には非構造化データでしかもペタバイトクラスのデータを処理するMapReduce処理系(すなわちHadoop)が位置づけられています。
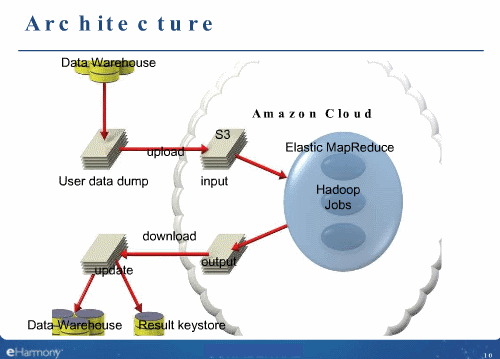
恋人マッチングサイトのeHarmonyの事例。大量の個人情報を基に適切なマッチングを計算するにはn人の二乗となる膨大な計算が必要。現在の10倍のメンバーに対応できる処理能力と、今後の成長に対応できるシステムを探していました。

その要件にマッチしたのがHadoopであり、Amazon EC2のMapReduceサービスを利用してシステムを構築下と説明されています。
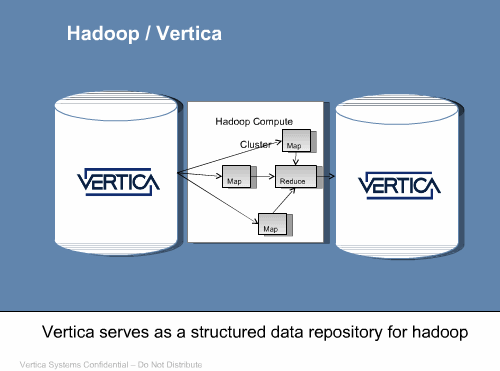
データウェアハウス用のデータベース製品を提供するVertica Systemsは、Hadoopとの統合製品を発表。大規模並列のカラムナデータベースであるVertica Analytic Databaseを、Hadoopのデータリポジトリとして利用可能に。これにより、ETLツールなどを用いたデータのインポートや、分析後のデータをBIツールなどで加工しやすくなる(カラムナデータベースについては、記事「カラムナデータベース(列指向データベース)とデータベースの圧縮機能について、マイケル・ストーンブレイカー氏が語っていること」を参考)。
参加者によるレポート記事
日本からHadoop World NY:2009に参加された方の記事やブログも紹介します。
- Hadoop World Report:優良企業はなぜHadoopに走るのか - ITmedia エンタープライズ
- Hadoop World NYC 参加記 - moratorium
- Hadoop World 2009 レポート « Agile Cat -- Azure & Hadoop -- Talking Book
日本では、このHadoop Worldを主催したClouderaも参加して11月13日にHadoop Conference Japan 2009が開催予定です(すでに定員を超えており、申し込みは締め切り済み、僕も間に合いませんでした)。その2日後の11月15日には北京で「Hadoop World:Beijin 2009」が開催される予定です。

