
GREEがOpenStackを導入した理由と苦労と改良点(前編)。OpenStack Days Tokyo 2014
オープンソースで開発されているIaaS型クラウド基盤ソフトウェアのOpenStackをテーマにしたイベント「OpenStack Days Tokyo 2014」が、2月13日、14日の2日間にわたり開催されました。OpenStackはIBM、HP、シスコシステムズなど大手ベンダも相次いでサポートを表明し、急速に注目度を高めています。
OpenStack Days Tokyo 2014、2日目の基調講演ではグリー株式会社 インフラストラクチャ本部 渡辺光一氏、松橋洋平氏が登壇。GREEの本番環境で稼働しているOpenStackについて、導入の経緯から苦労した点、実装方法などについて紹介しました。本記事ではそのダイジェストを紹介します。
GREEにおけるOpenStackの導入事例
グリー株式会社 開発統括本部 インフラストラクチャ本部 渡辺光一氏、松橋洋平氏(写真は渡辺氏)。

今日のセッションでは、まず物理サーバベースで運用していたときの話から、なぜ仮想化し、OpenStackを入れることにしたのかという経緯について紹介します。それから、弊社のOpenStackシステムの全体像と実装についてと、導入したあとの課題や運用について、そして締めくくりに最近の取り組みや感想など。
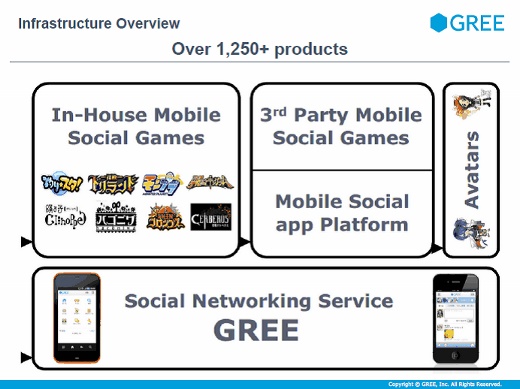
グリーは2004年12月に設立され、今年の12月で創業10年を迎えます。本社は六本木にあり、主にソーシャルゲームの開発やサービス提供などをしています。OpenStack導入以前から、短期間で急成長してきた経緯があります。
そのインフラを支えるために、独自にサーバダッシュボードを作っています。サーバごとにロールがあり、このダッシュボードからその状態が一目瞭然になっています。
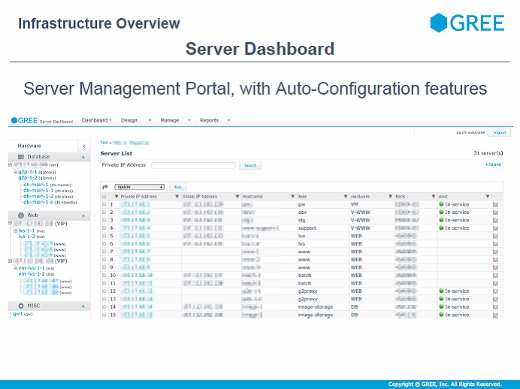
また、サーバにロールを設定して「ビルドサーバ」ボタンを押すと、WebサーバならApacheが入ってデプロイされるという、いまでいうChefやPuppetのような仕組みもあります。それぞれのサーバがサービス中なのか、サービスから外れているのか、壊れて修理中なのかというステータスも分かります。
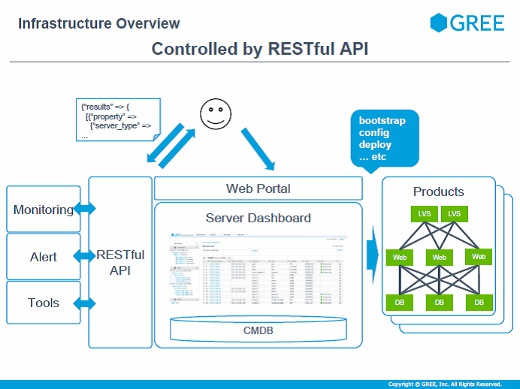
インフラ内部はすべてRESTful APIになっていて、モニタリングツールやデプロイツールといったものはすべてAPIで連係しつつサーバの管理をする仕組みになっています。全部がスケールアウトできるような構成になっていて、例えばゲームのイベントをたくさん行うと急激にワークロードが上がったりするので、そういう場合でも必要に応じてサーバをすぐに追加できるように、というところに力を入れています。
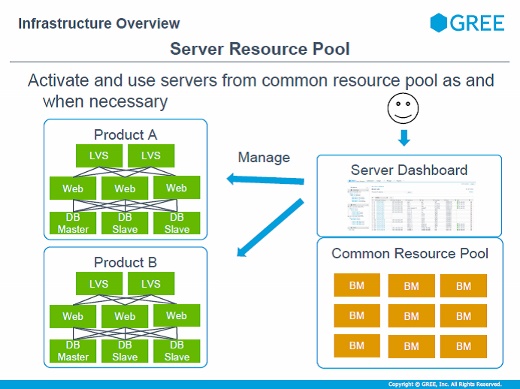
サーバを追加するときには、まず物理サーバを共通のプールに入れ、それを先ほどのダッシュボードからテナントへ追加していきます。故障したときやダッシュボードのアラートで以上を発見したときには排除し、ほかのサーバを補填する、といったサイクルになっています。
なぜインフラを仮想化しようとしたのか?
このように物理サーバベースで運用は回るように設計されているので、仮想化に対してどういうモチベーションがあるかというと、やはり物理サーバに対して大小さまざまなロールがあることです。バッチ用のサーバは負荷も低いしバッチ処理の回数もそれほど多くありません。そういう用途に物理サーバをまるごと割り当てるのはオーバースペックなので仮想化でサーバの利用率を向上させたいのと、仮想化ならではの特徴を活かして運用をもっと楽にしたい。例えば、テストの自動化などもそうです。

ただし考えなければならないこともあります。例えばハイパーバイザによる性能低下は、検証すると5%から50%くらいあって、数%の違いでも数十台の運用では結果的にコストが上がることもあります。
またノイジーネイバー(うるさい隣人)問題というのもあって、これは物理サーバ内のある仮想マシンがすごく忙しいと、同じ物理サーバ内の別の仮想マシンに迷惑をかけるのはうれしくないのでどうにかしなくてはいけないとか、KVMやOpenStackといったソフトウェアを入れることでさらにアーキテクチャが複雑になるとか、管理コストが上昇するのではないかといったことも考えました。
これらを検討しても、自動化やサーバリソースの効率的活用などがより柔軟にできる利点があるのではないか、ということで仮想化をすることにしました。
で、OpenStackを選ぶことになるわけですが、OpenNebulaやCloudStackなども検討しました。弊社はオープンソースソフトウェアを積極的に活用する文化があり、すべてAPIで操作できるとか、全部Pythonなのでモディファイしやすい点であるとか、さまざまな評価をしたうえでOpenStackに決めたと。
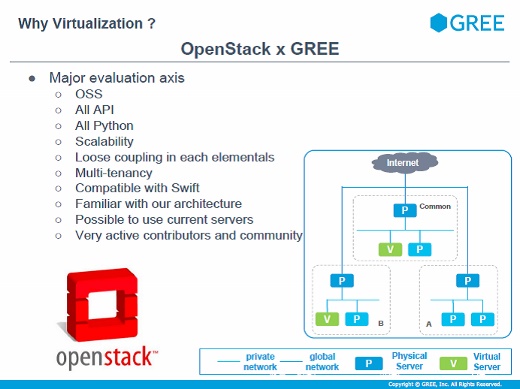
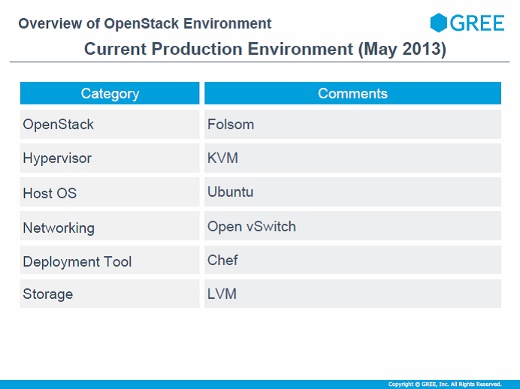
これが導入当時の環境です。ハイパーバイザはKVM、OSは全部Ubuntuです。ネットワークは将来的に柔軟なネットワークの実現を考えてOpen vSwitchにしました。ChefはOpenStackを構築するために使っています。
OpenStackを入れても操作は従来のままで
システムの概要ですが、従来のインフラと同一操作で利用できることを狙っています。サーバにApacheやMySQLを入れてプロダクション環境へデプロイしたり、コンテンツを入れたりする操作は今までと変わらず、OpenStackが見えないようになっています。
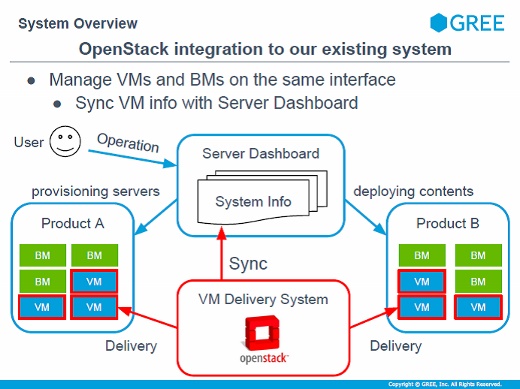
OpenStackを入れることでデリバリは高速化されました。各プロダクト共通のサーバプールをOpenStackで抱えて、そこから作るようにしています。
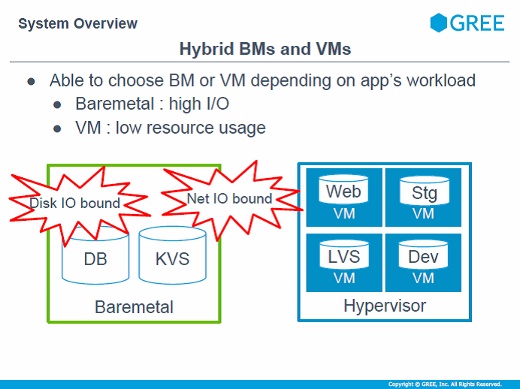
物理サーバと仮想サーバを混在させたハイブリッド環境を実現していますが、ソーシャルゲームのデータベースは書き込みが激しいので、仮想マシンだとユーザーに影響が出るくらいのオーバーヘッドが出るので、そこは無理せず物理サーバを使っています。リソース的に余裕があるところ。ステージングサーバやロードバランサーや一部のWebサーバでは仮想化を進めています。
QoSという概念をOpenStackに導入しました。仮想サーバ1台ごとの性能をある程度確保したいという要求があるので、ネットワークの帯域やディスクへのIOPSについて1台の限界を設定して、最低限ノイジーネイバー問題を解決できる仕組みを導入しました。
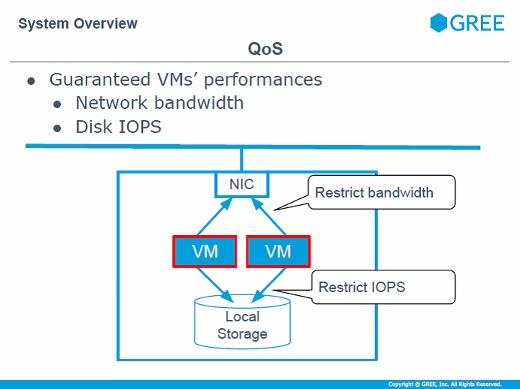
OpenStackのGREE環境への実装
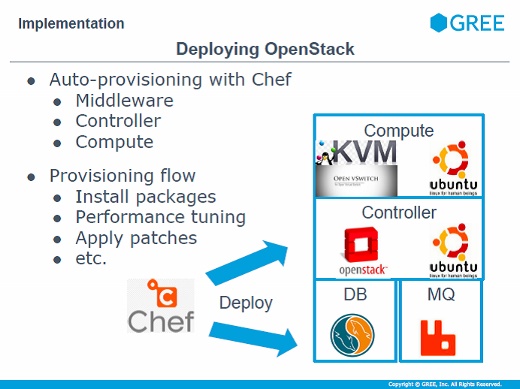
ここからは具体的に、OpenStackにどう手を加えて実装したかについて。
システムはすべてChefでデプロイされています。OpenStackのバックエンドのメッセージキューやデータベースもコントローラもすべてChefで、ハイパーバイザが載るコンピュートノードもChefで構成します。このChefのレシピは弊社で独自に開発しています。
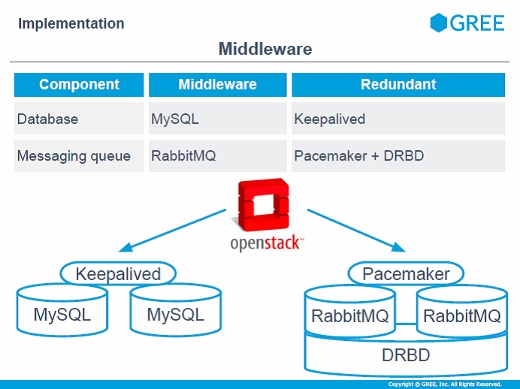
ミドルウェアの実装ですが、データベースはMySQLで、アクティブ-スタンバイの冗長化です。メッセージキューにはRabbitMQを用いていて冗長化はPacemakerとDRBD。ほかの構成も検討しましたがOpenStack Folsomではなかなかうまくうごかなかったのでこの構成にしました。
OpenStackのコントローラはKeepalivedの冗長化をしていて、アクティブのコントローラがダウンすると瞬時にスタンバイ側のコントローラに切り替わります。
コンピュートノードは、ハイパーバイザのオーバーヘッドを減らすために各種チューニングをしています。virtioやvhost、hugepagesなどを用いた一般的なKVMのチューニングを各種取り込んでいます。QoSはどうやったかというと、cgroupとtcを用いて実現しています。
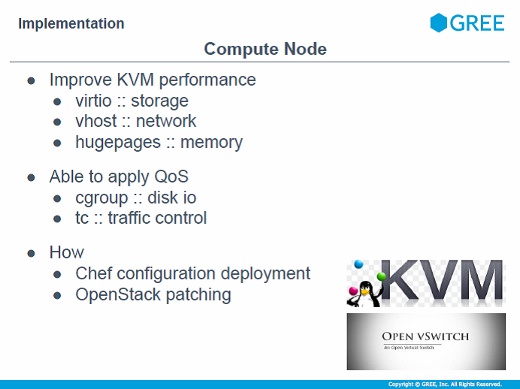
これらはChefでパッチを当てたりコンフィグを流し込んだりしています。
Region、Availability Zone、Aggregateの適用とQoS、運用コマンド
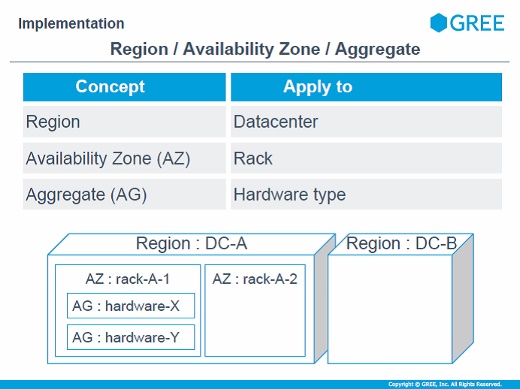
OpenStackのRegion、Availability Zone(AZ)、Aggregate(AG)を弊社の環境へどう適用したかについては、Regionはデータセンター単位にしました。ステージング環境もRegionを分けています。基本的に、管理したい単位を意識して分けています。
AZはラック単位で分けていて、AZを分けることで冗長化構成がとれるようにしています。AGに関してはハードウェアタイプを適用しています。
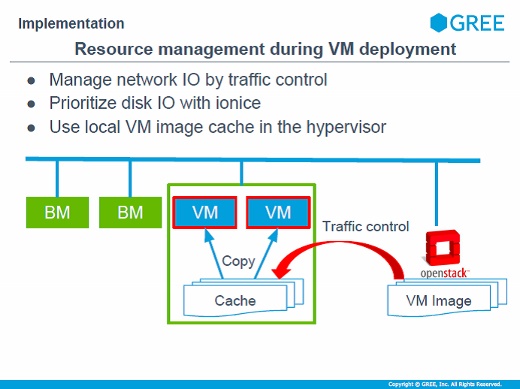
仮想マシンをデプロイするときには、ネットワークのトラフィックやディスクI/Oが気になります。ネットワークについては仮想マシンイメージが大きくて帯域を圧迫する可能性があるので、ある程度帯域を絞って転送するようにしています。
ディスクにイメージを書き込むときにもI/Oを下げてデプロイしていますし、デプロイするときにもハイパーバイザのローカルキャッシュにコピーして、そこからデプロイするような実装になっています。
OpenStackの運用コマンドがありますが、弊社では独自開発したコマンドを使っています。これは1つのyamlファイルを作って、これをバリデータで不正な入力などをはじいた上でシステムをセットアップしてくれるツールや、仮想マシンを作るときにはプロダクトごとに各種チューニングが必要なので、そういったパラメータのチューニングなどを実装しています。
また仮想マシンのスケジューラも独自に開発して、可用性が向上するような配置スケジューラにしています。例えばマスターとスレーブを同じラックに配置しないとか、そういう実装です。
モニタリング対象は100以上あって、リソースの使用状況や障害が起きたときに何が問題だったのか、などをグラフ化して特定する仕組みもできています。
OpenStack APIへのアクセス元は社内に限定しています。これはAPIの前段にリバースプロキシを入れて、そこで不正なアクセスをはじくようにしています。有効なアクセスについてもすべてSSLにしています。
あわせて読みたい
GREEがOpenStackを導入した理由と苦労と改良点(後編)。OpenStack Days Tokyo 2014
≪前の記事
見えてきたIBMのクラウド戦略、PaaSを強化し組み立て可能なサービス実現へ。IaaSでのAmazon対抗はせず

