
Treasure Dataのサービスはクラウド上でどう構築されているのか(後編)~July Tech Festa 2013
Treasure Dataといえば、日本人がシリコンバレーで創業したベンチャーとして知られている企業。そのシニアソフトウェアエンジニア中川真宏氏が、7月14日に行われたJuly Tech Festa 2013の基調講演で、同社がクラウド上で構築したサービスについてそのアーキテクチャを中心に解説を行っています。
この記事は「Treasure Dataのサービスはクラウド上でどう構築されているのか(前編)~Japan Tech Festa 2013」の続きです。
データを解析する「Plazma」の仕組み
データを解析するところでは「Plazma」と呼ぶ、Hadoopのエコシステムとカラムストアなどを組み合わせたものを用いています。

AWS上でサービスを展開しているので、内部のいくつかの機能はAWSに依存しています。1つはRDSで、ユーザー情報やカラムストアのメタデータ、キューとかスケジューラはRDSで構築しています。

S3の上にバックエンドの効率のいいカラムナストレージを用意することで、クエリをしやすくしています。MessagePackでデータを圧縮して効率を良くしているとか。
運用やパフォーマンスを考えて、EBS、EMR、SQSなどは使っていません。

これがバックエンドの構成となっています。
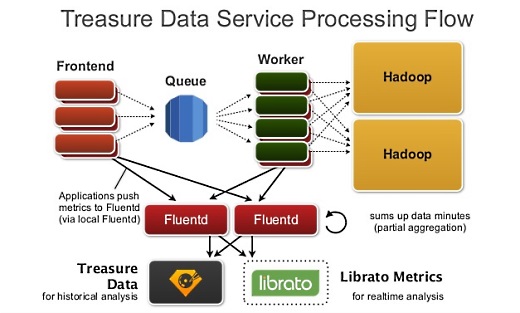
キューを挟んでフロントエンドとワーカーが対峙していて、いわゆる分散システムになっています。
キューにデータが置いてあると、ワーカーが死んだりしても簡単に状況が復帰できます。各コンポーネントをキューで配置するのは、これからクラウドでもオンプレミスでも大事になってくると思います。
クラウドではメトリクスを見ておかないと、ワーカーが落ちていたりCPUを食いまくって暴走しているといったことが分かりにくいので、libratoというツールでリアルタイムにメトリクスを見ています。
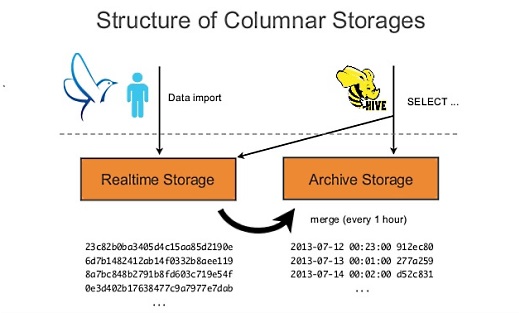
Hadoopではいちどデータを貯める必要があって、S3に2つのストレージ、来たデータが最初に入るリアルタイムストレージとアーカイブストレージを設けています。
リアルタイムストレージからアーカイブストレージへデータをマージするときに圧縮しているので、データが来ればすぐに分析できるようになっていて、しかも時間がたつとアーカイブストレージで圧縮されて効率のいいパフォーマンスを保証しています。
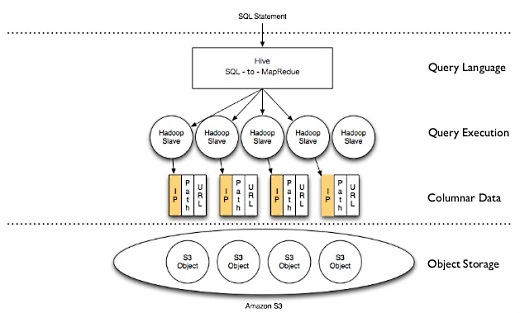
また、HDFSやHBaseのようなローカルストレージを意識してできないので、列指向でデータを持つことでI/Oコストを削減しようとしています。S3では、ここからここまでのデータをとってくる、というアクセスができるので、これで必要な部分だけをとってくる列指向のI/Oを実現しています。
レポーティング用途などではカラムを絞って検索することがあるので、そういうときに性能向上に役立っています。それによってS3のネットワーク越しのアクセスに対してHadoopでも高性能を実現していると。
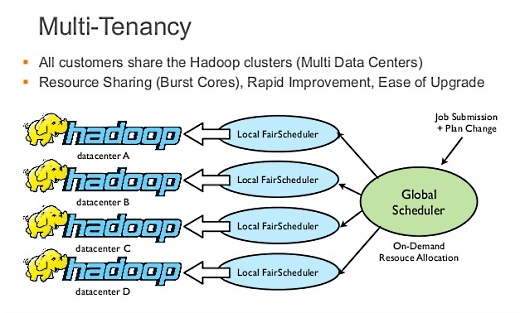
マルチテナントのところは、実は僕もどうやって動いてるか完璧には把握していないのですが。
Hadoopのグローバルなスケジューラがあって、ここで全体的なマルチテナントを実現しています。どこか空いているところがあれば、別のお客様がそこを使っていいよ、というような。
うちの古橋がここはずいぶんがんばったらしく、うまく動いていると。
クラウドでなければ実現できなかった
僕たちはかなり苦労して、Hadoopのプラットフォームは何がいいか、パラメータはどれがいいか、という試行錯誤をずいぶんしました。これはクラウドがなければ実現できなかったと思います。
いまでもHadoopのパラメータはちょくちょくいじってひたすら検証を繰り返していて、さすがにこれをオンプレミスでやるのは難しいなと思います。

ローカルで使っているツールもほとんどなくて、Chefもサービスを使っているので、社内でメンテナンスしているツールはJenkinsくらいです。
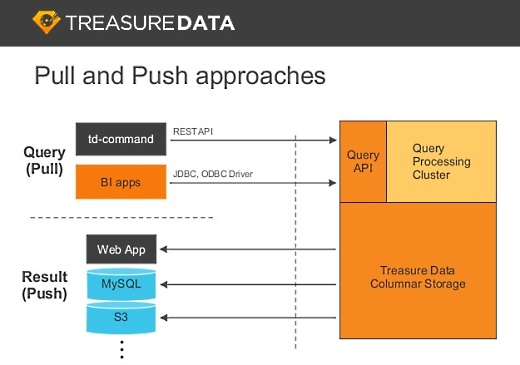
BIツールとの連係はプッシュとプル
数値の関連性が何十にもなってくると、ビジュアル化が重要になります。しかし僕らは独自のBIツールは持っていませんし、お客様がすでにBIツールを使っていることが多いので、それと接続できるほうがいいのではないかと考えています。
そこには2つのアプローチ、プル型と、データを書き出すプッシュ型があります。
プル型はREST APIからJSONで結果をとるとか、JDBC/ODBCなどで既存のBIツールで連係できます。
僕らが頑張っているのはプッシュ型の方で、ジョブの結果を外部にポストできるとか、MySQLに書き込むとか、S3に保存するとか。最近多いのは、Google Spreadsheetに書くというものです。
プッシュ型は自動化しやすいこともあって、多くのお客様が使っています。
結果、これだけのBIツールやAPIをサポートしています。

まとめ
Tresure Dataはいまのところ、データの収集、蓄積、解析の部分にフォーカスして実装しています。
特にシリコンバレーを歩いていると、「フォーカス、フォーカス」と言われます。クラウドは、アイデアをすぐ実現する手段としてはいいのですが、それだけだとすぐに追いつかれるので別の差別化要因を作る必要があります。
だから、自分たちの強みを常に意識して実装していく、そのためのビジョンを常に立てて、それを実現していくことが大事だと思っています。

(8/5 追記:イベント名を間違えていたため、タイトルと本文の一部を修正しました)
参考:Treasure Dataが新サービス発表。バッチ型クエリと比較して10倍から50倍高速な「Treasure Query Accelerator」とデータ可視化ツール「Treasure Viewer」
参考:オープンソースのバルクデータローダー「Embulk」登場。fluentdのバッチ版、トレジャーデータが支援
あわせて読みたい
DevOpsの大事なことは、だいたい原点に書いてある(前編)~ Developers Summit 2013 Summer
≪前の記事
Treasure Dataのサービスはクラウド上でどう構築されているのか(前編)~July Tech Festa 2013

