
Treasure Dataのサービスはクラウド上でどう構築されているのか(前編)~July Tech Festa 2013
Treasure Dataといえば、日本人がシリコンバレーで創業したベンチャーとして知られている企業。そのシニアソフトウェアエンジニア中川真宏氏が、7月14日に行われたJuly Tech Festa 2013の基調講演で、同社がクラウド上で構築したサービスについてそのアーキテクチャを中心に解説を行っています。
注目されているクラウドサービスがどのような仕組みになっており、それはどのような考え方で作られているのか。クラウドでシステム構築を考えている多くのエンジニアの参考になるはずです。講演の内容をダイジェストで紹介します。
Treasure Dataのクラウド戦略
Treasure Data, Inc。シニアソフトウェアエンジニア 中川真宏氏。
スタートアップなこともあって好きな肩書きを付けていいと言われたので、こんな肩書きにしてみました。
個人としてはオープンソースを中心に活動しています。

Tresure Dataのサービスが正式にローンチしたのは昨年9月。どんなサービスなのか、どんなシステムや技術を使っているのか、などを紹介したいと思います。
Treasure Dataのオフィスはシリコンバレーにありますが、ファウンダーは全員日本人です。いまは東京の新丸ビルにもオフィスがあって、メインはシリコンバレーですが日本でも営業や開発をしています。

なぜクラウドでサービスを展開しているか。
多くの企業で、いままではリレーショナルデータベース(RDB)にデータを展開するのが普通でしたが、大量のデータを蓄積し続けるのはRDBでは結構大変だったりするので、ここで数年前から話題になっていたのがHadoopです。
Hadoopはデータを貯めてバッチで処理するのにかなり有効なプロダクトで、データウェアハウスとHadoopを連係させるのが一時期トレンドでしたが、運用やメンテナンスの手間が増大するという課題がありました。そこでそうしたものを僕らが運用して、お客様には自分のビジネスに集中してもらおうというのがTreasure Dataのビジネス展開です。
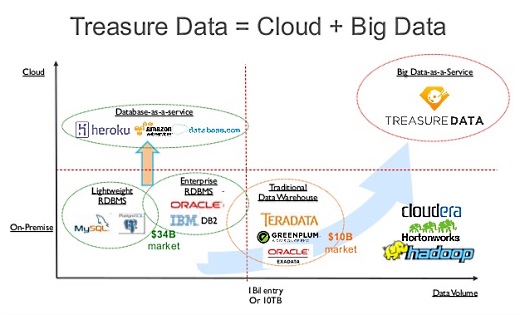
既存のシステムですと、イニシャルコストが高くて導入のハードルも高いので、お客さんがやりたいことをスタートするハードルが高いわけです。その分野の専門家がいればできますが、なかなかそういう人はいません。
最近のシステムはいろんなシステム、コンポーネントをどう組み合わせるのか、というのがどんどん複雑になってきています。そもそもデータが増えたりリソースが増えたらどうやってまとめていくのがいいのか、といった課題があります。
僕らは、ビッグデータに必要だろうという機能をワンパッケージで提供することによって、サインアップすればすぐにサービスが利用できる、ということを目指しています。
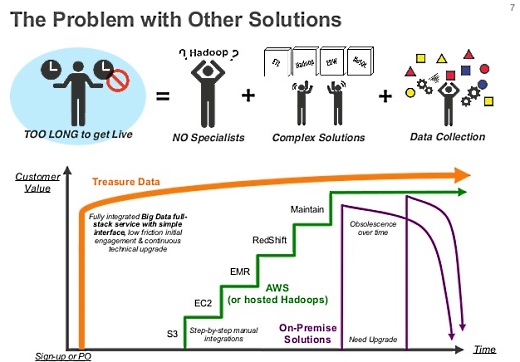
ビッグデータでは、機械学習などたくさんのことができます。僕らは、そもそも何が起きているのか、ユーザーがどんな行動をしたのかといったレポーティングに特化しています。
データを集める、貯める、クエリで検索、というのをひとまとめにしたシステムで提供し、マネージできるAPIを提供することで、サインアップするとすぐに解析などに利用できます。これがTresure Dataのサービスと、コンポーネントベースやオンプレミスなどとの大きな違いです。
クラウド上でHadoopを運用する、というのが先にあるのではなく、ビッグデータの解析をするために必要なサービスを提供している、ということです。この点が、Hadoop on Cloudとは違う価値を提供している、ということになります。

全体の構成
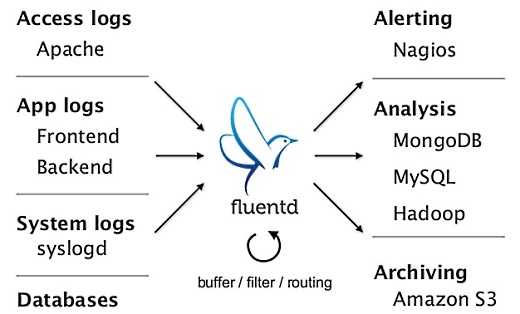
これが全体の構成です。データコレクションに関しては、fluentdを使ってデータをクラウドにあげるのをできるだけ自動化しています。すでにデータがたまっている場合には、バルクアップローダーも提供しています。
DWHに関しては、Amazon EMRを使わず、自分たちでカラムナストレージを作って、その上で生のHadoopではなく機能追加したHadoopを使っています。解析は通常のBIツールが使えるようになっています。
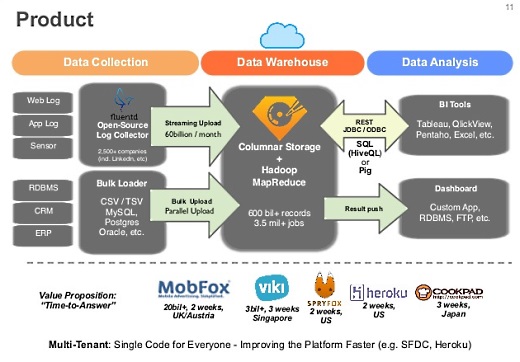
基本的には1カ月未満でプロダクションまで行っているお客様が多くて、いまは80社くらいのお客様がいます。

データ収集に使うfluentdとは
トレジャーデータのサービスアーキテクチャの考え方としては、とりあえずデータを貯めていって、スキーマはあとで考える、というもの。
そしてシンプルなAPI。なるべくお客さんが使いやすい、見て困惑しないAPIで、かつパワフルなものを提供したい。
そしてサインアップすれば、すぐにデータを収集して、分析には専用のBIツールも不要で、簡単に使い始められるようにな設計をしています。

海外のBI関係の調査によると、データを収集するところに苦労の60%があると。どういうデータをどう集めるかが大事で、そのためにfluentdを作りました。
実際、みなさんどうやってHadoopにデータを入れているかというと、putコマンドでマニュアルでやっているらしく、これだと運用コストがかかるし、データが大きいとそれだけネットワークを占領するなどいろいろ問題がありました。

そこでFacebookなどはScribeというコレクタを作ったりしましたが、一般にオープンソースで誰でも使えるようなデータコレクタがないので、fluentdを作って公開しています。
fluentdはパフォーマンスが大事なところはCで書いています。置くだけで使えて、rubygemsというエコシステムに乗っていて、100以上のプラグインがあります。

これは構成例ですが、Apacheがログを書き出すと、昔は定期的にscpとかでログをコピーしていたと思いますが、それだとレイテンシが大きすぎたりするので、fluentdを置いておくと、ずっと監視していてログが吐かれたときにfluentdがデータを収集してストリーム的にログ収集ができます。
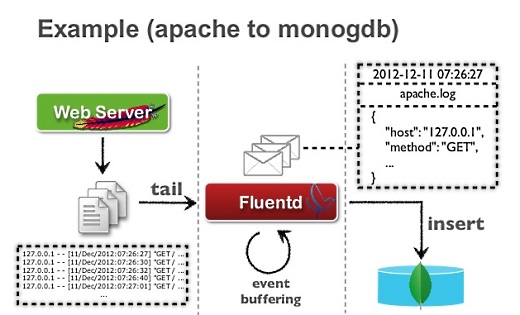
一行ごとに、時間と、このデータがどこからきたかなどがJSON形式になっているので、機械で読みやすくデータの破損にも強くなります。そして数秒や数分のタイムラグでログが分析できるようになります。
td-agentはfluentdのパッケージです。fluentdは起動スクリプトといったものを想定していないので、僕らがパッケージにして、起動スクリプトやrubyのランタイムなどを同梱しています。また、ちゃんと動くことを検証しているプラグインも同梱しています。

≫後編では、データ解析のアーキテクチャなどを解説しています。「Treasure Dataのサービスはクラウド上でどう構築されているのか(後編)~Japan Tech Festa 2013」へ。
(8/5 追記:イベント名を間違えていたため、タイトルと本文の一部を修正しました)
参考:Treasure Dataが新サービス発表。バッチ型クエリと比較して10倍から50倍高速な「Treasure Query Accelerator」とデータ可視化ツール「Treasure Viewer」
参考:オープンソースのバルクデータローダー「Embulk」登場。fluentdのバッチ版、トレジャーデータが支援
あわせて読みたい
Treasure Dataのサービスはクラウド上でどう構築されているのか(後編)~July Tech Festa 2013
≪前の記事
2013年7月の人気記事「IT系上場企業の平均給与」「技術的負債とは何か」「Vagrantは仮想環境をプログラミングする」

