
Apache Spark 1.5正式版がリリース。JavaVMのオーバーヘッドを改善する「Project Tungsten」で、さらに高速に
高速なビッグデータ処理基盤として注目されているApache Sparkの最新版「Apache Spark 1.5」のリリースが発表されました。
Apache Sparkは、高いスループットを実現するバッチ処理と小さなレイテンシが求められるリアルタイム性の高い処理のいずれにも対応することを目指して開発された、大規模分散処理基盤です。
インメモリ処理や中間データなどをできるだけ生成させない効率的なスケジューラなどを備え、Scala、Java、R、Pythonなどに対応するなどが特長。
Project Tungstenによる高速化
Apache Spark 1.5の最大の特徴は「Project Tungsten」による実行エンジンの高速化です。
Apache SparkはJavaVMを用いて処理を行っていますが、JavaVMが備えるガベージコレクションやメモリ管理などの仕組みは、Apache Sparkが行う処理においては非効率なところがあり、処理速度のボトルネックになっていました。
これを解決するために「Project Tungsten」を立ち上げ、Spark自身がメモリマネージャなどを備えるようにしたのです。
To tackle both object overhead and GC’s inefficiency, we are introducing an explicit memory manager to convert most Spark operations to operate directly against binary data rather than Java objects.
オブジェクトのオーバーヘッドやガベージコレクションの非効率さを解決するため、私たちは明示的なメモリマネージャを採用し、Sparkでの処理のほとんどを、Javaオブジェクトではなく直接操作するために、入れ替えることにした。
(「Project Tungsten: Bringing Spark Closer to Bare Metal」から引用)
こうした改善で、Spark 1.4に比べてSpark 1.5では性能が大きく改善したと説明されています。
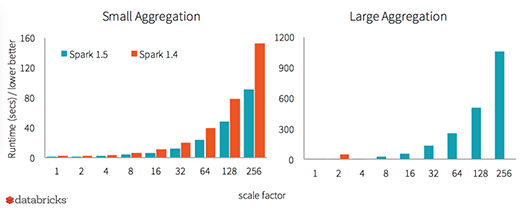
また、WebブラウザからSQLやDataFrameのクエリプランをビジュアルに参照できる機能、Spark Streamingのバックプレッシャー機能、Data Science APIの拡張などが行われています。
あわせて読みたい
Herokuを任意のAmazon VPCに展開できる「Heroku Private Spaces」パブリックベータ公開。ついに東京リージョンのAmazon VPCでもHerokuが利用可能に
≪前の記事
マイクロソフト、米国外のデータセンターに保存された顧客メールの提出を命じた米当局に抵抗し控訴。Amazon、シスコらも支持

