
PaaSが進化する方向と、仮想化を使わないクラウド
セールスフォース・ドットコムのForce.comやグーグルのGoogle App Engineなど、初期のPaaSでは言語やデータベースがほぼ決め打ちなのに対し、最近登場してきたVMwareのCloudFoundryやレッドハットのOpenShift、DotCloudなどの新しいPaaSでは、データベースやプログラミング言語などが自由に選べるようになってきたため、第二世代のPaaSと呼べるのではないか。
先日の記事「プログラミング言語やデータベースが選べる新世代PaaS「DotCloud」が正式サービス開始でこのように書きました。
そしてこの記事を書きながら、僕の頭の中には第三世代のPaaSはきっとこうなるだろう、という予想も浮かんでいました。この記事では、その第三世代のPaaSとはどんなものになるのか、予想について書こうと思います。
マルチテナントネイティブ vs 仮想化ネイティブ
実は第一世代のPaaSと書いたForce.comやGoogle App Engineには、言語やデータベースがほぼ決め打ちという特徴以外にもう1つ大きな特徴があります。それは、ミドルウェアが最初からマルチテナントを想定したアーキテクチャになっており、データベースレイヤが複数のテナントで共有されていること。そして、仮想化を使っていない、という特徴です。あえて言葉を作るとすれば「マルチテナントネイティブ」なPaaSだといえます。
一方、第二世代のPaaSと書いたCloudFoundry、OpenShift、DotCloudなどは、プログラミング言語やデータベースが柔軟に選べる代わりに、テナントの境界を仮想マシンの境界に依存するため、実行環境として仮想化をベースにしたインフラを想定しています。こちらは「仮想化ネイティブ」なPaaSだといえるでしょう。
それぞれを図で表すと、次のようになります。左がマルチテナントネイティブなPaaS、右が仮想化ネイティブなPaaSです。
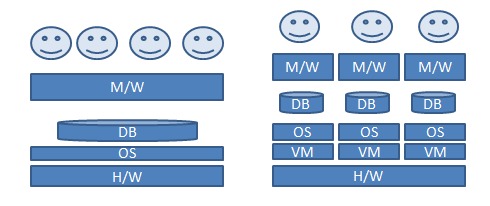 左が第一世代のマルチテナントネイティブなPaaS、右が第二世代の仮想化ネイティブなPaaS
左が第一世代のマルチテナントネイティブなPaaS、右が第二世代の仮想化ネイティブなPaaS効率の高さか、選択の幅の広さか
マルチテナントネイティブなPaaSでは、複数のテナントがデータベースやOSのプロセス空間を共有するため、あるテナントが別のテナントのデータを参照できないようにすべてのデータにテナントIDをつけて管理したり、重たい処理や無限ループや全件検索などで特定のテナントがリソースを消費しすぎないように処理場の制限をかける、といった機能がミドルウェアに組み込まれます。
そのためミドルウェアは独自実装の部分が多くなり、それが言語の決め打ち、データベースの決めうちにつながったと考えられます。
一方で仮想化ネイティブなPaaSでは、仮想化によってテナントごとの空間が分けてあるため、仮想マシンのうえで従来のミドルウェアやデータベースをほぼそのまま動かすことができます。それが、プログラミング言語やデータベース選択の幅の広さにつながるといえます。
しかし図をみると分かるとおり、仮想化ネイティブではテナントごとにOSも重複してますし、仮想マシンのオーバーヘッドもありますし、なによりデータベースがテナントごとに複数動作しているのはあきらかに効率の低下につながります。仮想化ネイティブのリソースの利用効率は、マルチテナントネイティブに比べるとずいぶん悪いものになります。
例えば、マルチテナントネイティブなセールスフォース・ドットコムのクラウドでは、昨年6月の時点でサーバは全部で3000台しかないことをCEOのマーク・ベニオフ氏が公言しています。しかもその半分はディザスタリカバリ用であり、実質1500台のサーバで当時約8万社もあるすべての顧客のアプリケーションを処理していたのです。驚異的です。
複数の顧客がプロセス空間もデータベースも共有したうえでチューニングが可能な、マルチテナントネイティブの効率性の高さをうかがい知ることができるでしょう。
第三世代のPaaSとは、第一世代+第二世代
ここまで理解すれば、第三世代のPaaSがどうあるべきなのかが見えてきます。そう、第一世代のPaaSが持つ効率性の高さと、第二世代のPaaSが持つ選択肢の広さを合わせ持つべきです。
つまり仮想化は用いずに、複数のテナントが1つのデータベースを共有します。そしてミドルウェアには、テナントごとにデータベースを分けたり、特定のテナントの処理が重くなりすぎないような制限機能が備わっています。
この第三世代のPaaSを実現するために必要なものは、Java、Ruby、PHPなどクラウド上でよく使われる言語に対し、マルチテナント機能を実現するためのフレームワークです。このフレームワークに、データベースを共有するためにデータにテナントIDを付加する機能や、負荷の高い処理を防止する機能、負荷の高い処理を監視する機能などを組み込むのです。
そうすることで、仮想化を用いずにマルチテナント化された、効率のよいPaaSを実現することが可能になるでしょう。ただしさまざまな言語でこうしたフレームワークを開発するのは、なかなか骨の折れる作業となるはずですので、その工数が最大の課題でしょう。
第三世代のPaaSは、おそらく第二世代のPaaSの普及と並行して開発が進んでいき、2年以内には登場するのではないか想像していますが、いまのところ知るかぎり、そのようなマルチテナント向けのフレームワークが開発されているという話は聞いたことがありません。
ですので現時点でこの第三世代のPaaSはまったくの仮説です。
と、こう予想しておきながら、PaaSの進化はこれとは別のシナリオもあり得ると考えています。そのシナリオはまた近いうちに別の記事で書こうと思います。お楽しみに。

